

Benchmarking Amazon Aurora vs. PostgreSQL

At Timescale, we pride ourselves on making PostgreSQL fast. We started by extending PostgreSQL for new workloads, first for time series with TimescaleDB, then with Timescale Vector, and soon in other directions (keep an 👀 out). We don’t modify PostgreSQL in any way. Our innovation comes from how we integrate with, run, and schedule databases.
Many users come to us from Amazon RDS. They started there, but as their database grows and their performance suffers, they come to Timescale as a high-performance alternative. To see why, just look at our time-series benchmark, our usage-based storage pricing model, and our response to serverless, which gives you a better way of running non-time-series PostgreSQL workloads in the cloud without any wacky abstractions.
Amazon Aurora is another popular cloud database option. Sometimes, users start using Aurora right away; other times, these users migrate from RDS to Aurora looking for performance from a faster, more scalable PostgreSQL. But is this what they find?
This article looks at what Aurora is, why you’d use it, and presents some interesting benchmark results that may surprise you.
What is Aurora? (It’s not PostgreSQL)
Amazon Aurora is a database as a service (DBaaS) product released by AWS in 2015. The original selling point was of a relational database engine custom-built to combine the performance and availability of high-end commercial databases (which we guess means Oracle and SQLServer) with the simplicity and cost-effectiveness of open-source databases (MySQL and PostgreSQL).
Originally, Amazon Aurora only supported MySQL, but PostgreSQL support was added in 2017. There have been a bunch of updates over the years, with the most important being Aurora Serverless (and then, when that fell a bit flat, Serverless v2), which aims to bring the serverless “scale to zero” model to databases.
Aurora’s key pillars have always been performance and availability. It’s marketed as being faster than RDS (“up to three times the throughput of PostgreSQL”), supporting multi-region clusters, and highly scalable. Not much is known about the internals of Aurora (it’s closed-source, after all), but we do know that compute and storage have been decoupled, resulting in a cloud-native architecture that is PostgreSQL-compatible but isn’t Postgres.
Investigating Aurora
There are a few ways of running Aurora for PostgreSQL, and you’ll be asked two critical questions from the Create Database screen.
First up, you need to select a cluster storage configuration:
- Do you want to pay slightly less for your compute and stored data with an additional charge per I/O request (Aurora Standard)?
- Or, do you want to pay a small premium on compute and stored data, but I/O is included (Aurora I/O-Optimized)?
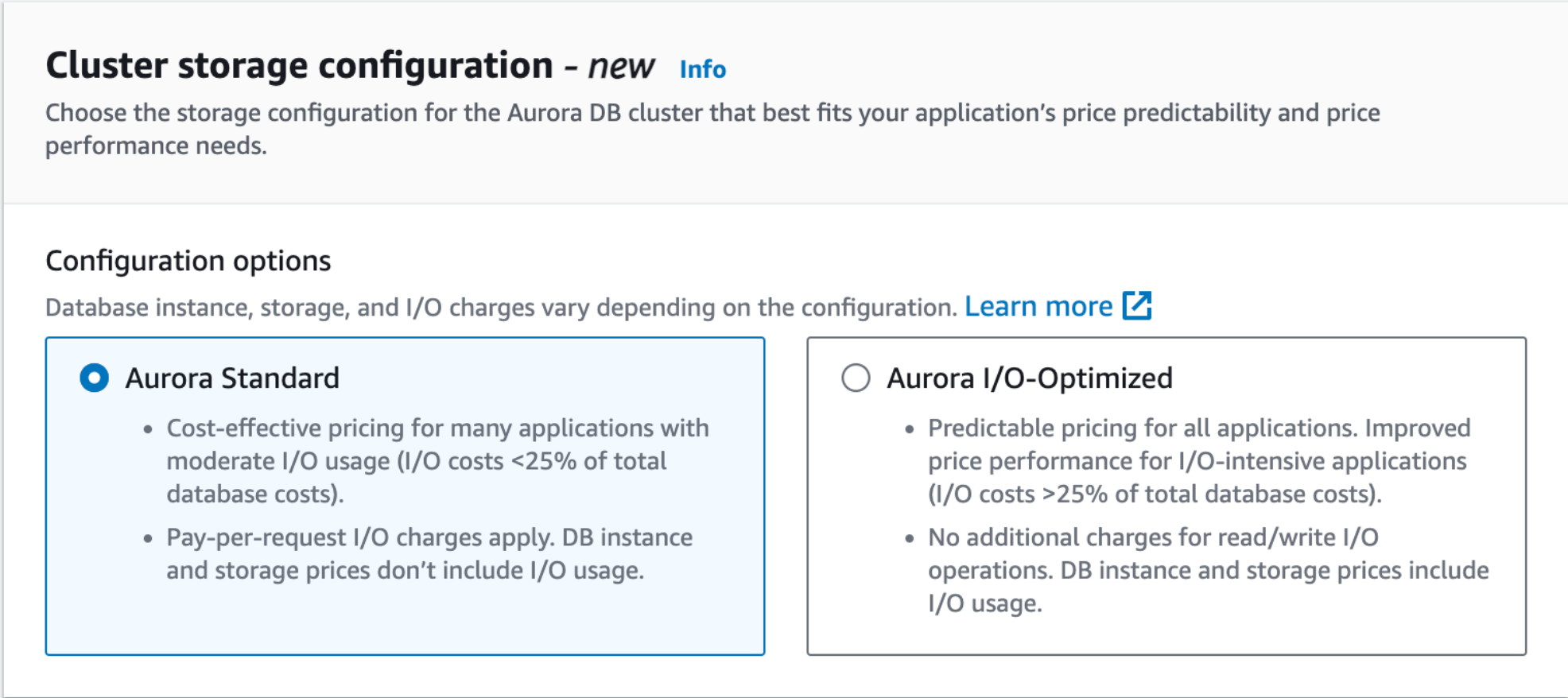
In our benchmark, we saw a 33 % increase in CPU costs and a massive 125 % increase in storage costs when moving from Standard to I/O-Optimized, although I/O-Optimized still came in cheaper once the I/O was factored in. AWS recommends using an I/O-Optimized instance if your I/O costs exceed 25 % of your database costs.
I/O-Optimized turns out to be a billing construct: we saw roughly equivalent performance between the two storage configurations.
After you’ve chosen that, there’s another big decision coming up: do you want to enable Serverless v2?
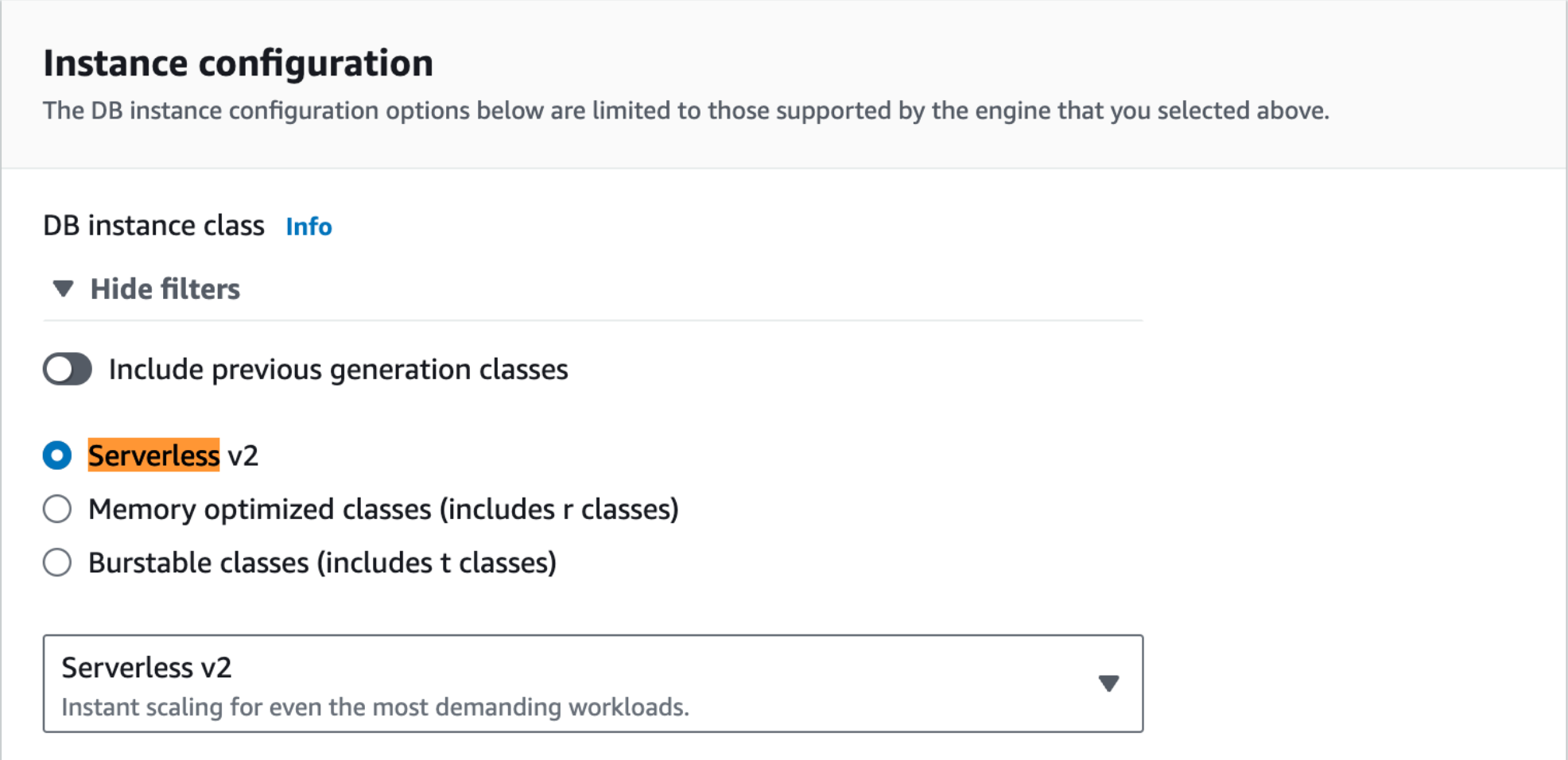
Although three options are shown, there are really only two: Provisioned and Serverless. Provisioned is where you choose the instance class for your database, which comes with a fixed hourly cost. Serverless is where your prices are driven by your usage.
If you have quiet periods, Serverless might save you money; if you burst all the time, it might not. When you choose a Provisioned type, you get a familiar “choose your instance type” dialog; when you select Serverless, you get something new.
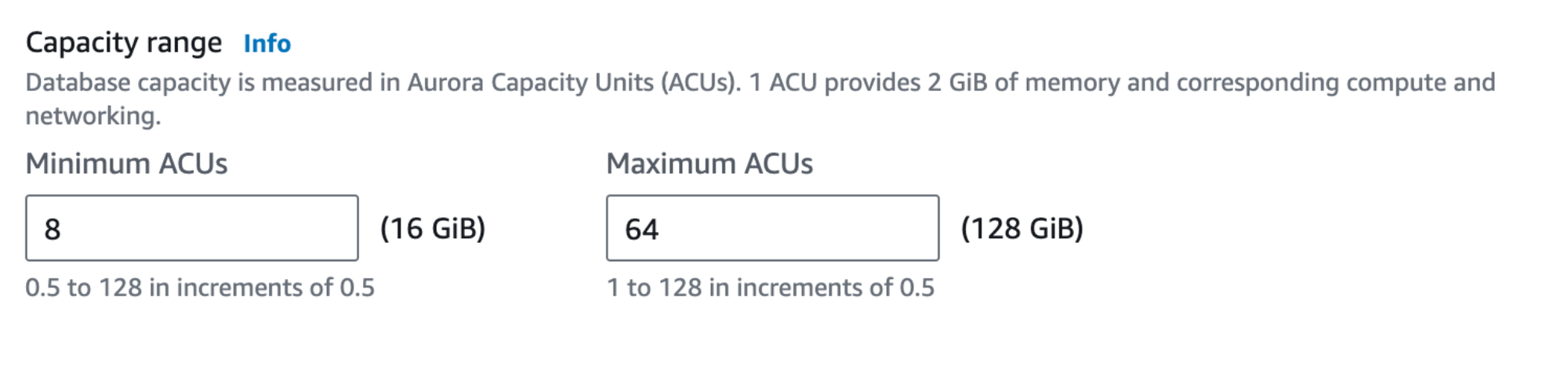
So, instead of choosing a CPU and memory allocation associated with an instance, you set a range of resources in ACUs (Aurora Capacity Unit), which your cluster will operate within.
So, what exactly is an ACU? That’s an excellent question and one which we still don’t entirely know the answer to. You can see that the description states an ACU provides “2 GiB of memory and corresponding compute and networking,” but what on Earth is corresponding compute and networking?
How do you compare this to Provisioned if you have no idea how many CPUs are in an ACU? Is an ACU one CPU, half a CPU, a quarter of a CPU? We actually have no idea, and we can see no way to quickly find out. The opacity was frustrating during our tests. It feels obfuscated for no good reason.
Confusion aside, the general idea is that, at any time, Amazon Aurora will use the number of ACUs (in half-a-point increments) that it needs to sustain your current workload within the range you specify. If your workload lets you scale up and down, Serverless might be a good idea. Or is it?
Aurora costs
So, why isn’t everybody using Aurora? The other axis is price, and while Amazon Aurora pricing is significantly harder to model than RDS, it’s definitely more expensive, with the difference soaring as you scale out replicas or multiple regions.
We thought so. We have had some interesting testimonials from customers telling us that they had lost confidence in Aurora. So, to draw our own conclusions, we started where any reasonable engineer would—we benchmarked.
Benchmarking Configuration
But, before we started, we had to decide what we would benchmark against. We ended up choosing the Serverless (v2) I/O-Optimized configuration because that’s what we tend to see people using in the wild when they talk to us about migration.
When deploying Amazon Aurora Serverless, we need to choose a range of ACUs (our mystery billing units). We wanted to compare with a Timescale 8 CPU/32 GB memory instance, so we selected a minimum of 8 ACUs (16 GB) and a maximum of 16 ACUs (32 GB memory). Again, this veneer over CPUs is very confusing. In a perfect world, one would hope that an ACU provides one CPU from the underlying instance type—but we just don’t know.
We used the Time Series Benchmark Suite (TSBS) to compare Amazon Aurora for PostgreSQL because we wanted to benchmark for a specific workload type (in this case, time series) to see how the generic Aurora compared to PostgreSQL that has been extended for a particular workload (and also because we ❤️ time series).
Note: Many types of workloads are actually time series, more than you would think. This doesn’t only apply to the more traditional time-series use cases (e.g., finance) but also to workloads like energy metrics, sensor data, website events, and others.
We used the following TSBS configuration across all runs (for more info about how we run TSBS, you can see our RDS Benchmark):
Aurora vs. PostgreSQL Ingest Performance Comparison
We weren’t expecting Timescale to compare when it came to ingesting data (we know the gap between us and PostgreSQL for ingest has been narrowing as PostgreSQL native partitioning gets better). By separating the compute and storage layers, we thought we would see some engineered gains in Aurora.
What we actually saw when we ran the benchmark—ingesting almost one billion rows—was Timescale ingesting 35 % faster than Aurora with 8 CPUs. Aurora was scaled up to 16 ACUs for the entire benchmark run (including the queries in the next section). So not only was Timescale 35 % faster, but it was 35 % faster with 50 % of the CPU resources (assuming 1 CPU == 1 ACU).
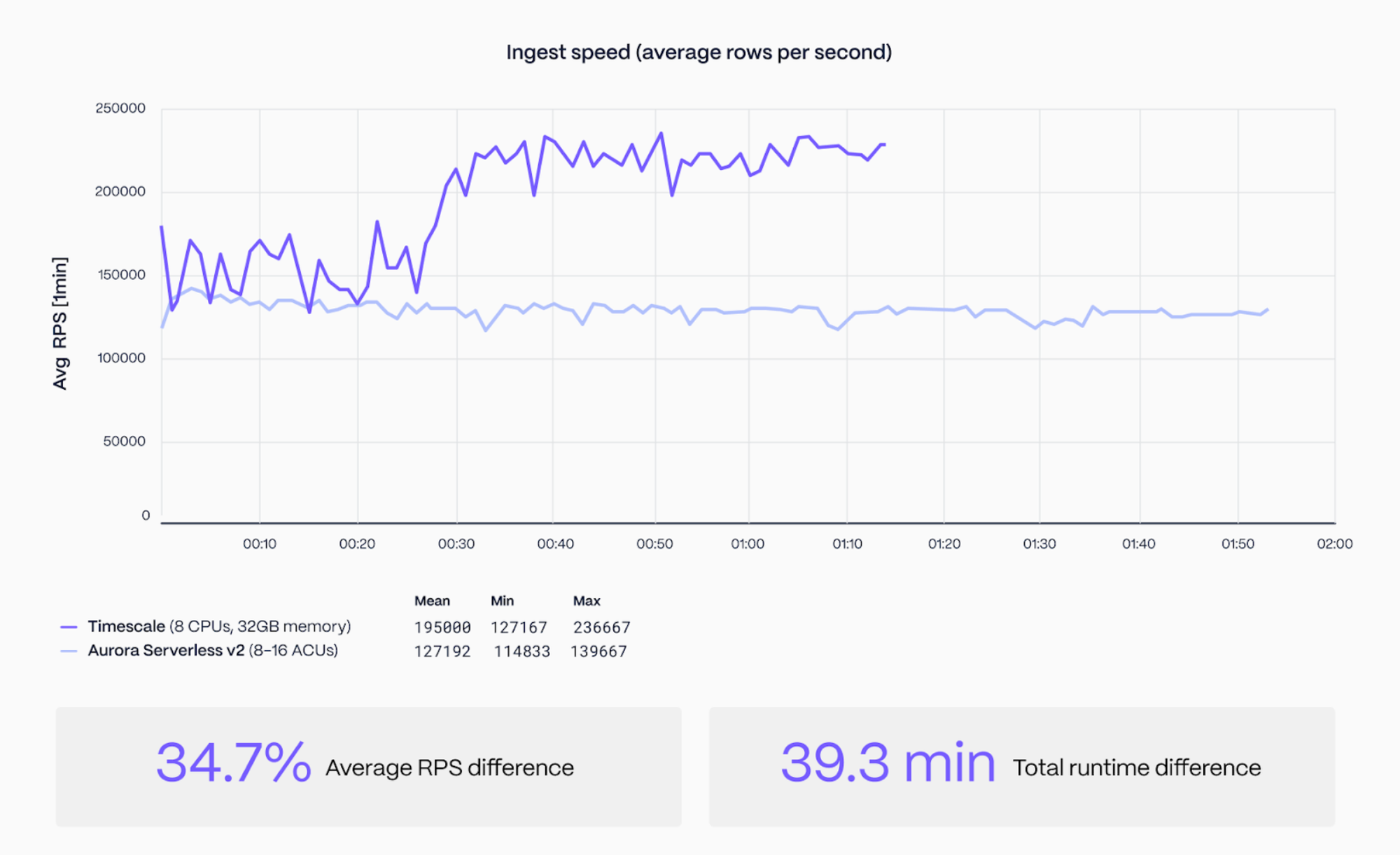
At this stage, some of you might be wondering why Timescale jumped in ingest speed around the 30-minute mark. The jump happened when the platform dynamically adapted the I/O on the instance as we saw data flooding in (thanks to our amazing Usage Based Storage implementation).
Aurora vs. PostgreSQL Query Performance Comparison
Query performance matters with a demanding workload because your application often needs a response in real or near real-time. While the details of the TSBS query types are basically indecipherable (here’s a cheat sheet), they model some common (although quite complex) time-series patterns that an application might use. Each query was run 10 times, and the average value was compared for each of our target systems.
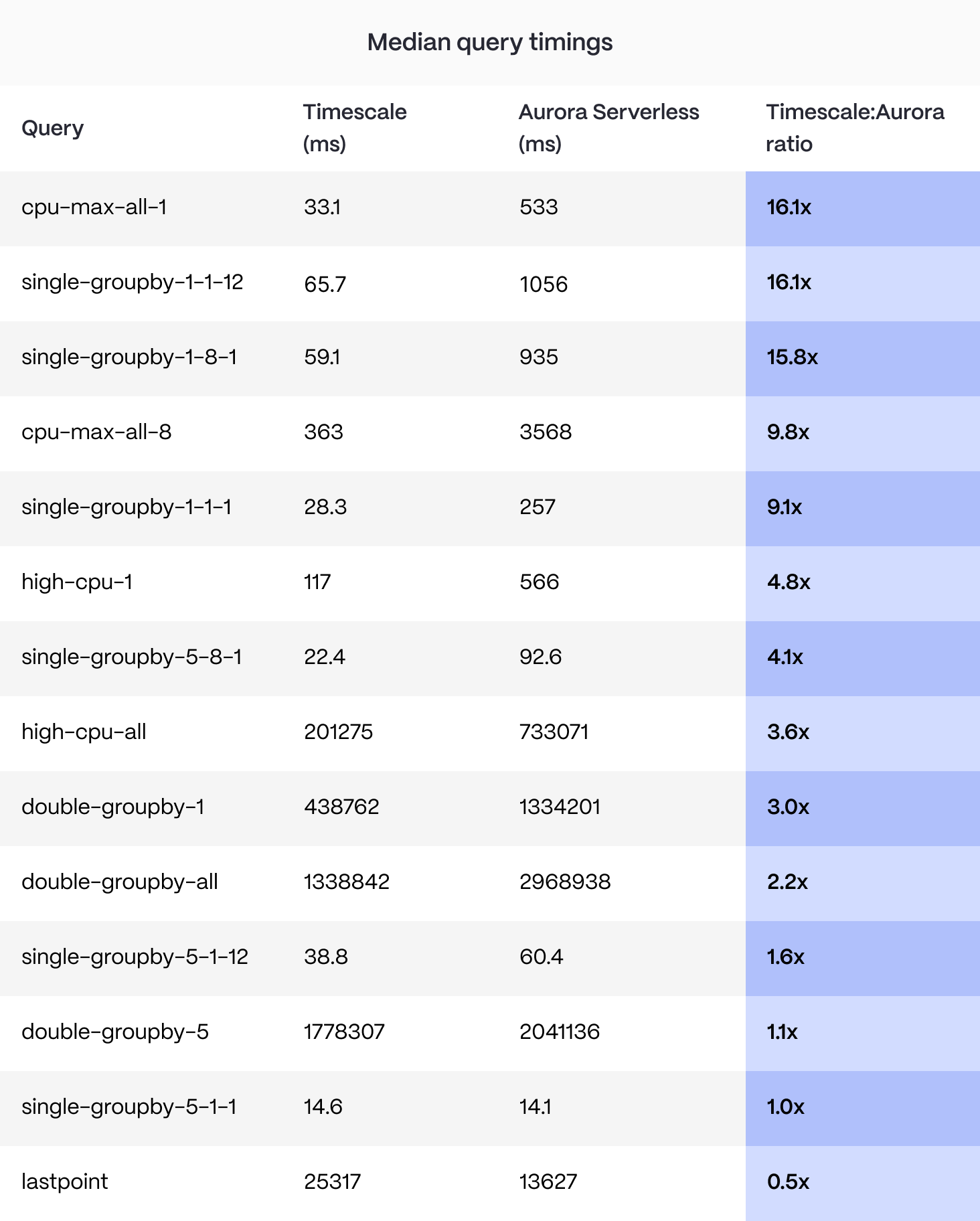
The results here tell another very interesting story, with Timescale winning in most query categories—we were between 1.15x and 16x faster, with two queries being slightly slower. When we did a one-off test with a Timescale instance with 16 CPUs, some queries stretched out to 81x faster, with all categories being won by Timescale.
Why is this? Timescale is optimizing for the workload by teaching the planner how to handle these analytical queries and also using our native compression—which flips the row-based PostgreSQL data into a columnar format and speeds up analysis. For more information about how our technology works and how it can help you, check out our Timescale vs. Amazon RDS benchmark blog post.
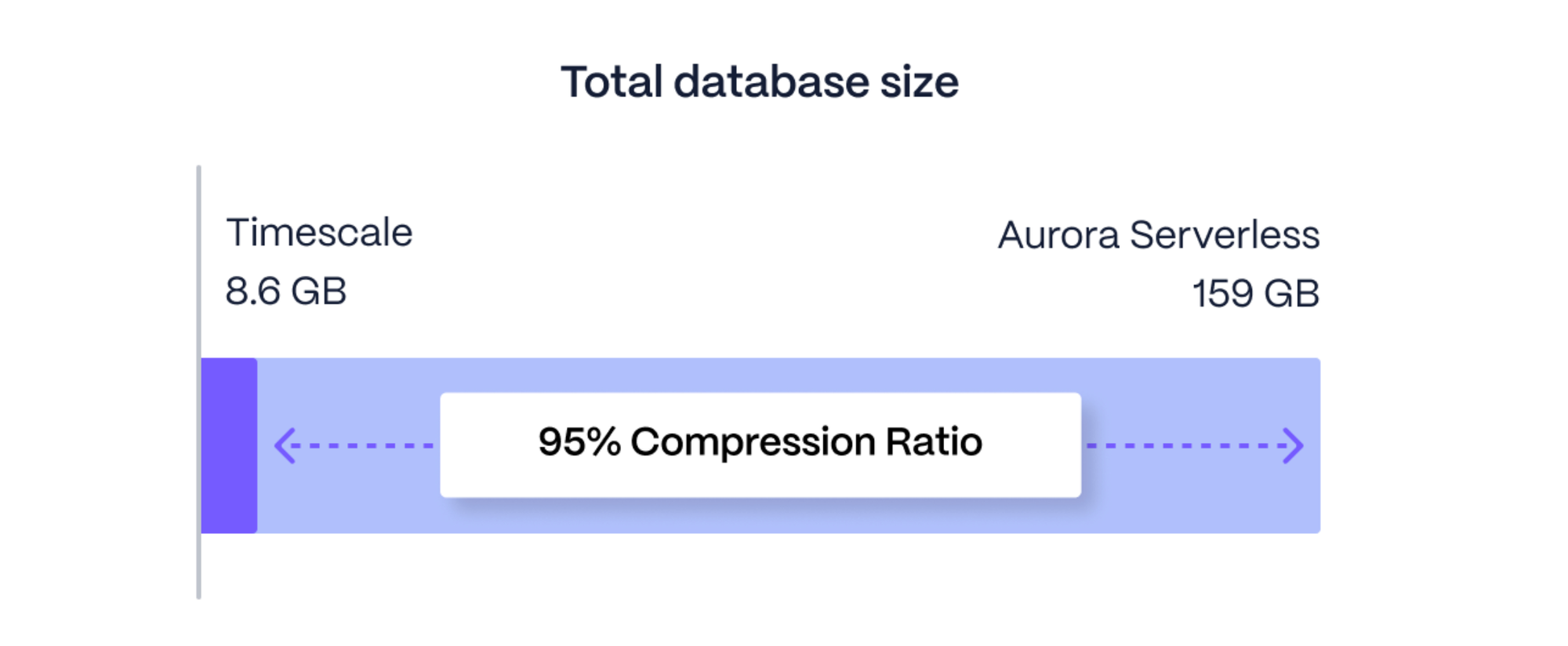
Aurora vs. PostgreSQL Data Size Comparison
What about the total size of the CPU table at the end of the benchmark? There were no surprises here. Amazon Aurora (even though it’s using a different storage backend to PostgreSQL) doesn’t seem to change the total table size, with it coming in at 159 GB (the same as RDS did). In contrast, Timescale compresses the time-series data by 95 % to 8.6 GB.
Aurora vs. PostgreSQL Cost Comparison
There is no way to sugarcoat it: Amazon Aurora Serverless is expensive. While we were benchmarking, it used 16 ACUs constantly. First, we tried the standard Serverless product, but it charged a prohibitive amount for I/O, which is why we don’t see anyone using it for anything even remotely resembling an always-on workload. It defeats the purpose of serverless if you can’t actually ingest or query data without breaking the bank.
So, we switched to the Serverless v2 I/O-Optimized pricing, which charges a small premium on compute and storage costs and zero rates on all I/O charges. It’s supposed to help with pricing for a workload like the one we’re simulating.
Let’s see how Aurora I/O-Optimized really did. The bill for running this benchmark has two main components: compute and storage costs. (Although Aurora actually charges for some other facets, the costs were low in this case). These are the results:
Compute costs:
- Aurora Serverless v2 I/O-Optimized costs $2.56 per hour for the 16 ACUs, which were used for the duration of the benchmark.
- The Timescale 8vCPU instance costs $1.26 per hour (52 % cheaper than Aurora).
Storage costs:
- Aurora Serverless v2 I/O-Optimized needed 159 GB of storage for the CPU table and indexes, which would be billed at $34 per month.
- Timescale needed 8.6 GB to store the CPU table and indexes, which would be billed at $7.60 per month (78 % cheaper than Aurora).
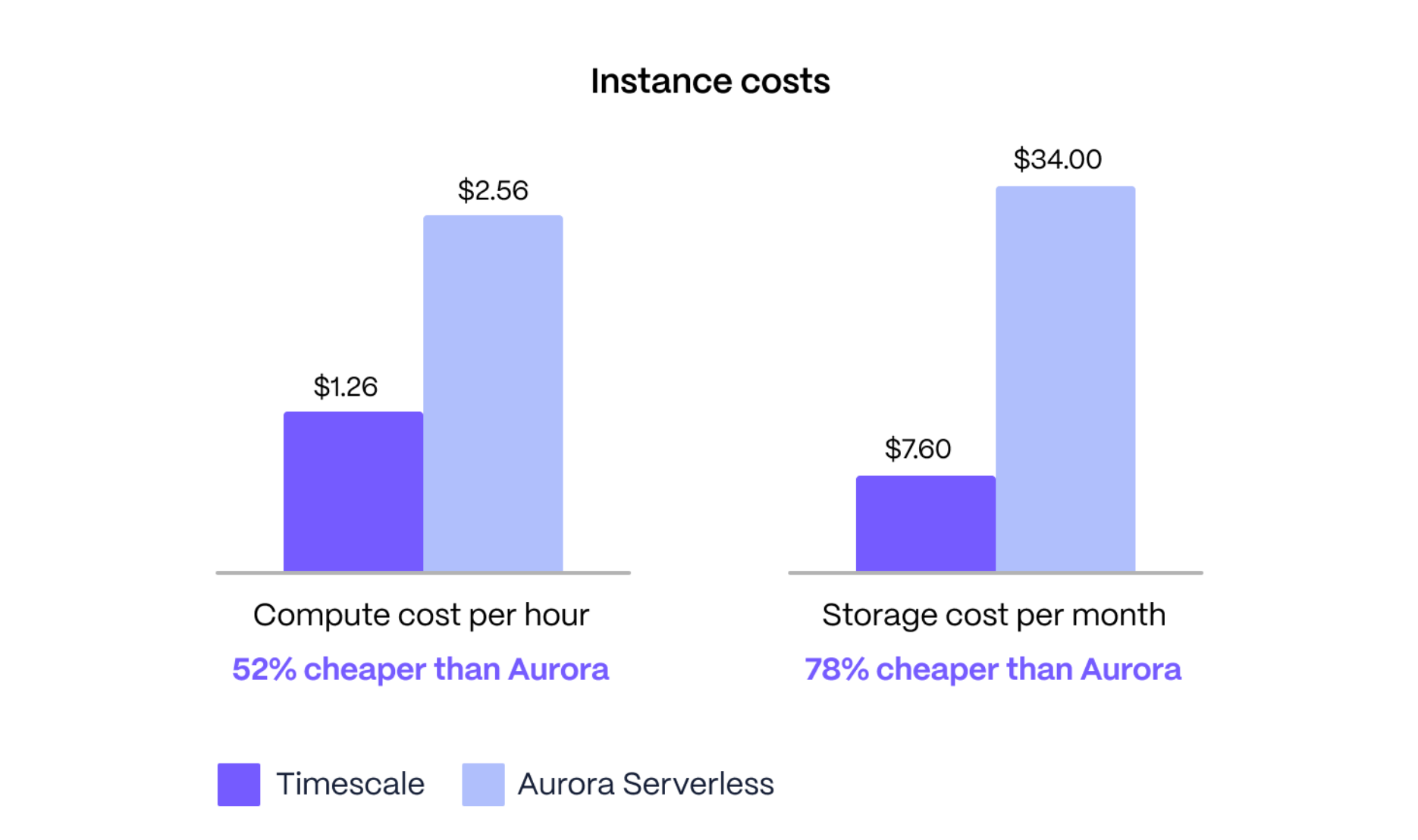
Timescale is 52 % cheaper to run the machines used for the benchmark (assuming a constant workload) and 78 % cheaper to store the data created by the benchmark.
Our Finding
The main takeaway from this benchmark was that, although Aurora Serverless is commonly used to “scale PostgreSQL” for large workloads, when compared to Timescale, it fell (very) short of doing this.
Timescale was:
- 35 % faster to ingest
- 1.15x-16x faster to query in all but two query categories
- 95 % more efficient at storing data
- 52 % cheaper per hour for compute
- 78 % cheaper per month to store the data created

While Aurora does replace PostgreSQL’s storage backend with newer (closed-source ☹️) technology, our investigation shows that Timescale beats it for large workloads in all dimensions.
Looking at this data, people might conclude that “Aurora isn’t for time-series workloads” or “of course a time-series database beats Aurora (a PostgreSQL database) for a time-series workload.” Both of those statements are true, but we would like to leave you with three thoughts:
- Timescale is PostgreSQL—in fact, it’s more PostgreSQL than Amazon Aurora.
- Timescale is tuned for time-series workloads, but that doesn’t mean it’s not also great for general-purpose workloads.
- A very high proportion of the “large tables” or “large datasets” that give PostgreSQL problems (and might cause people to look at Aurora) are organized by timestamp or an incrementing primary key (perhaps bigint)—both of which Timescale is optimized for, regardless of if you call your data time-series or not.
Create a free Timescale account to get started with Timescale today.


