

Introducing Dynamic PostgreSQL: How We Are Evolving the Database to Help You Sleep at Night
Starting today, you can create Dynamic PostgreSQL databases on Timescale.
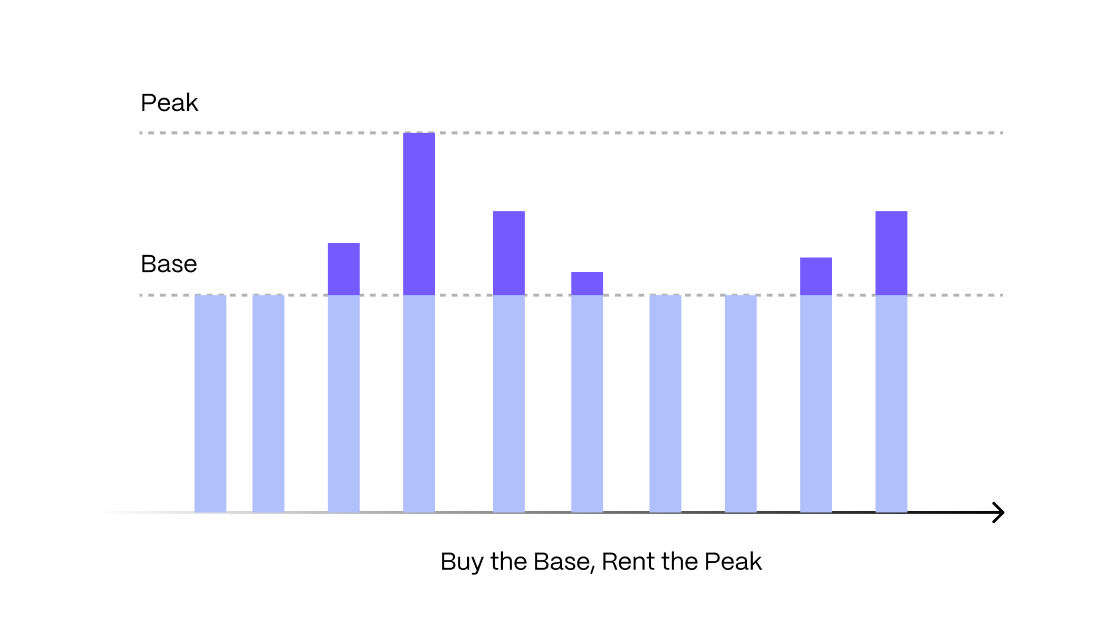
Dynamic PostgreSQL is the natural evolution of cloud databases, solving the problems of both provisioned databases and serverless databases. It is backed by dynamic compute, a Timescale innovation that instantaneously scales your available compute within a predefined min/max range according to your load. Instead of provisioning for your peak (and paying for it at all times), you can now pick a compute range: your database will operate at base capacity and instantly access up to its peak only when needed. Buy the base, rent the peak.
This results in unparalleled price-performance: customers running production workloads will save 10-20 % when migrating from AWS RDS for PostgreSQL and 50-70 % when migrating from AWS Aurora Serverless.
You can try out Dynamic PostgreSQL today. We offer a free trial—no credit card required—that gives you full access to the platform for 30 days.
To create a Dynamic PostgreSQL service, just select the PostgreSQL option when logging into Timescale:

Your application is always on, why shouldn’t your database be?
Welcome to the future.
Problem 1: Developers provision far more compute than they need
For the past several years, ever since we first launched Timescale, we have had a front-row seat to how developers use databases. For example, just in the last few months, we have analyzed over one trillion queries as part of our Insights product.
One thing we have learned is that developers often provision far more compute than they actually need.
On the one hand, this makes sense: You never want to worry about your database. Most database workloads are continuous, typically with some variability or burstiness to them. For example, a game that has more usage at night, a business application that has more usage during the day, or a connected home device that has more usage on the weekends than during the week.

You never want your database to run out of resources. If your database is at max capacity, that leads to a terrible customer experience (or no customer experience!). So, most developers end up provisioning for the peak, plus a buffer. This results in developers paying for much more compute than they actually need.
On the other hand, this seems crazy to us. What other business resource would organizations be okay spending far more than what they need? Wasted compute equals wasted money.
Problem 2: Serverless databases fall short for production workloads
Some of you might be asking, “What about serverless databases?”
The concept of serverless originated with stateless workloads. After the success of virtual machines in the cloud, where users could stop needing to worry about hardware, they next asked why even worry about running application servers at all? After all, many users just wanted to run functions and only be charged for the time those functions were running. And it’s easy and seamless to spin up functions as needed, almost precisely because they are stateless. Serverless—and function-as-a-service or FaaS—became a hit, with AWS Lambda taking over.
Developers then asked themselves, “Why pay for my database when I’m not using it?” The actual question is good: wasted resources are a massive database problem. And the practice of provisioning an AWS RDS database on a specific server instance (say, a db.m6gd.2xlarge) sure doesn’t feel modern or flexible: fixed CPU, fixed memory, fixed local disk. Most of it underutilized most of the time.
But this is where things get tricky: databases are very different from Lambda functions.
Serverless databases today are wrong for most production workloads for two main reasons:
- Serverless databases focus on the extremes for scaling up and down, even to zero.
- Serverless databases introduce much higher pricing to account for the resource “headroom” reserved to serve changing demands (and worse, often with pricing models that are hard to understand or predict).
Let’s start by discussing the hot topic of “scale to zero.” The reality is that most production databases don’t need and won’t actually benefit from scaling to zero.
Now, there are some use cases where “scale to zero” makes sense. For example, proof-of-concept demos or more hobbyist applications. The ability to occasionally run an ad-hoc query against your dataset (AWS Athena and Google BigQuery make a strong case for a low-cost, serverless cloud data warehouse for very intermittent use). Another suitable use case would be to avoid forgetting to spin down a cloud dev instance once finished—there’s value in “auto pausing” a non-production database (although that requires much simpler functionality than envisioned by serverless).
But for your production database and in more operational settings? You don’t want to scale to zero.
Scaling to zero means a “cold boot” on restart: empty database shared buffers, empty OS cache, empty catalog caches (in the case of PostgreSQL).
(Yes, some serverless databases lower the time it takes to start the database running, but they do so from an empty state. In a relational database like PostgreSQL, it can take minutes (or longer!) to build a warm working set again, especially for larger databases.)
The cold start performance hit is even greater as many serverless databases adopt different cloud storage architectures, where the cost and latency of fetching database pages from remote storage into memory is even greater. These overheads again lead to worse performance or force platform providers to compensate by using greater physical resources (e.g., Amazon Aurora databases have twice the memory of RDS), a cost that ultimately gets passed on to users.
So, in many scenarios, serverless databases end up with higher and unpredictable pricing.
For example, if you compare Aurora Serverless against Amazon RDS, you’ll see that 8 vCPU compute and 500 GB storage on Serverless is 85 % more expensive than RDS ($1,097 vs. $593). And this is using Aurora I/O Optimized and its more predictable storage prices, which launched just six months ago. (Although, even here, we still have to infer its actual compute capacity, as Aurora Serverless prices by confusing opaque “Aurora Capacity Units,” which to our best-informed estimates are 1 ACU = 0.25 vCPU.)
Previously, with Aurora Standard, users would also pay for each internal I/O operation, which was nearly impossible to predict or budget. Many serverless databases continue to charge for such reads and writes. In fact, when we benchmarked the serverless AWS Timestream, we saw costs that ended up more than 100x higher than with Timescale due to all of these higher marginal costs. The unpredictability and variability of costs were the opposite of worry-free.
In short, serverless databases are prone to poorer performance, unpredictable bills, and high costs as workloads scale. They are only well suited for intermittent workloads that spin up only occasionally and can tolerate cold starts with their lack of in-memory data caching.
The developer dilemma

This is where we have ended up:
- Many developers still choose traditional DBaaS services with provisioning for production applications due to their reliable performance, control, and understandability, but hate the waste that arises from the necessity of overprovisioning.
- Some developers choose serverless databases for their apparent cost savings, flexibility, and ease of use, but hate the performance hit and the unpredictable, obscure pricing (which often result in bills mysteriously higher than a provisioned instance).
As developers ourselves, neither of these options is very appealing! There is an opportunity for better.
Solution: Introducing Dynamic PostgreSQL
That’s why we developed Dynamic PostgreSQL.
Dynamic PostgreSQL consistently supports your baseline and seamlessly scales compute when you need it, up to a defined max. This makes it perfect for the range of continuous workloads you typically see in production settings (whether uniform, variable, or bursty).
Dynamic PostgreSQL is 100 % PostgreSQL, with all the benefits of the PostgreSQL community and ecosystem, plus the maturity of Timescale’s database platform. To build Dynamic PostgreSQL, we’ve innovated on how we operate our PostgreSQL infrastructure rather than modifying the internals of PostgreSQL. This gives you access to everything that PostgreSQL—and the Timescale platform—offers, without the fear of running on a forked PostgreSQL query or storage engine.
With Dynamic PostgreSQL, you choose a compute range (a minimum and maximum CPU) corresponding to your workload needs. This compute range also comes with effective memory that is equivalent to what most DBaaS services traditionally offer on the “maximum” end of the compute range.
The base (minimum) of your CPU range acts exactly like the provisioned DBaaS model: the minimum CPU is at all times dedicated to your service to run your application. As your load increases—either due to your external application’s demand or even due to occasional internal database tasks like incremental backups or table auto-vacuuming—your database can use up to the peak (maximum) of your CPU range with zero delay.
How do we achieve zero delay? Dynamic compute works differently than some other serverless or auto-scaling database offerings, so it doesn’t involve the slow scaling (and performance hit) you typically see from remote migrations. Instead, our infrastructure configuration and workload placement algorithms ensure that databases can scale up on their underlying node without restarts or reconfiguration. Your instance always has access to its maximum compute as needed.
And the best part is that you only pay for the base plus what you use above it. We call this model of choosing a compute range and scaling between it “buy the base, rent the peak.”

For example, if you choose a 4–8 CPU option, you will always have 4 CPUs dedicated to your service and 32 GB of effective memory. This ensures good base performance at all times. When your load increases, your application can use up to 8 CPUs instantaneously as it needs—metered and billed on a fractional CPU basis—and never more than 8 CPUs if this is your max limit.
The dynamic model allows you to “size” your database more cost-effectively and worry-free. You can choose a compute range where your standard demand fits the minimum, yet you can grow or spike up to the peak (maximum) as needed. This maximum creates an inherent cap on any usage above your base compute, leading to an easy-to-understand cost ceiling. Further, we charge the same rate per (fractional) CPU-hour for both your base and any metered usage over this: there is no upcharge for using above your base, and therefore no price penalty for scaling.
Finally, if you realize you provisioned a size range that is too low or too high, you can easily adjust your compute range to a size that better suits your application’s needs.

Engineered to save you money
We currently offer five different compute ranges based on your workload size, with corresponding effective memory you receive for the range regardless of your instantaneous usage.

Dynamic PostgreSQL also uses Timescale’s usage-based storage, where you only pay for the volume of data stored (in GB-hours), not for a provisioned disk size. No worrying about wasting money with an over-provisioned disk or similarly worrying that you’ll run out of disk space. Timescale’s dynamic cloud infrastructure ensures you have sufficient storage capacity, when you need it, and that you only pay for what you use.
We have developed Dynamic PostgreSQL intentionally to save you money. Customers running production workloads typically save 10-20 % when migrating from AWS RDS for PostgreSQL and 50-70 % when migrating from AWS Aurora Serverless.
At the end of the month, your bill consists of two simple, easy-to-understand metrics: (1) your compute costs, billed as your hourly base compute plus any fractional CPU usage above it but no more than your peak; and (2) your storage costs, billed as data consumption in GB-hours. There are no new metrics or derived units to measure or understand.
Just pay for what you use. Zero extra costs or hidden fees.
- Compute: predictable, based on a defined range
- Storage: only pay for what you store
No wasted resources. No overpaying. No losing sleep at night. A bill you can explain to your boss.
Try it today
You can try out Dynamic PostgreSQL today! Timescale offers a free trial—no credit card required—that gives you full access to the platform for 30 days. To create a Dynamic PostgreSQL service, just select the PostgreSQL option when logging into Timescale:

The platform now offers two service types to serve the specific needs of your databases:
- Time-series services are engineered to boost query speed and scalability for your most demanding workloads, offering key Timescale features such as hypertables, columnar compression, continuous aggregates, and tiered storage. Use them to host your sensor data, energy metrics, financial data, events, and other data-intensive workload.
- PostgreSQL services are dynamic Postgres services optimized for cost-efficiency and ease of use. Use them for your relational-only databases, e.g., business records.
Once you select “PostgreSQL,” configuring your Dynamic PostgreSQL service is super simple. Select your region, your dynamic compute range, and your high availability and connection pooling options— boom! 💥 You now have a Dynamic PostgreSQL database ready to use in production.


If you have any questions, reach out to us. We’d love to hear your feedback and to help you with your PostgreSQL use case (time series or not)!
This is just the beginning. We’re in the middle of three consecutive launch weeks, and this is just the start of Week 2: Dynamic Infra Week. Stay tuned for more this week, this month, this year, and the many years to come. 🙂




