

How to Get Faster Aggregated Data in PostgreSQL
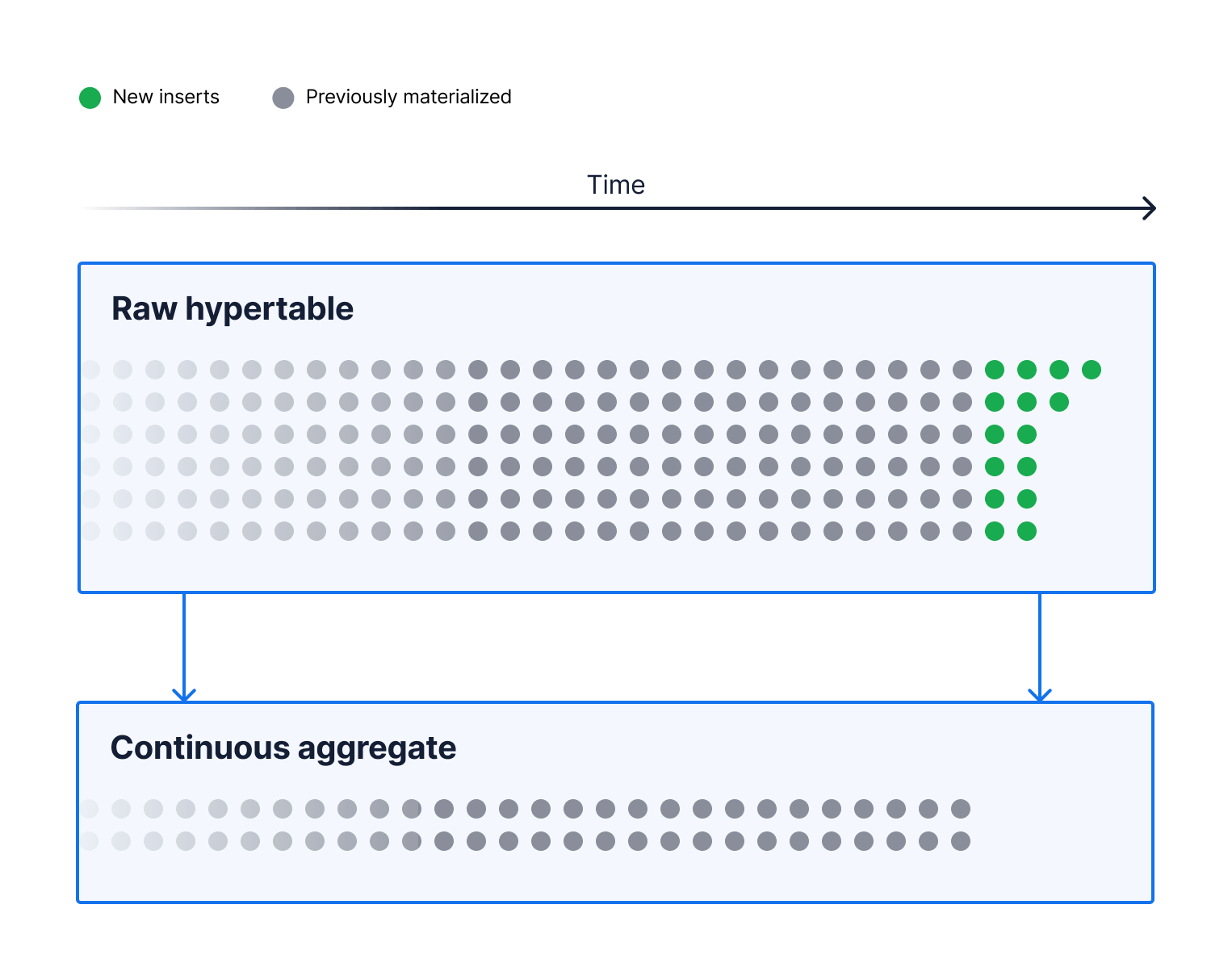
If, like most PostgreSQL users, you are looking for a way to speed up your queries by aggregating your data, you have probably heard of PostgreSQL materialized views. Unfortunately, you probably also heard about their downsides. While materialized views speed up your queries by making them reusable—storing the resulting data on disk—every time new data is added, updated, or deleted from the underlying table, you have to manually refresh the materialized view with a REFRESH MATERIALIZED VIEW [materialized view name]; statement.
As if this wasn't time-consuming enough, manually refreshing materialized views comes with its very own set of problems: from outdated data (if you have a steady stream of data being written to your table, like time-series data) to performance hits (as the materialized view's definition needs to rerun on all the data in the table to refresh itself).
To solve this tricky problem, the Timescale team engineered a better data aggregation option—continuous aggregates, an incremental and automatically updated version of materialized views. Before we show you how to adequately configure them—Support engineer here 👋—let's discuss the challenges of fast data aggregation in PostgreSQL.
Data aggregation: Beyond materialized views
One of the main challenges of working with time-series data is effectively running aggregations over high data volumes. In PostgreSQL, you can retrieve data aggregations using various methods:
- Querying your data directly with an aggregation function and a
GROUP BY. You will probably find this option slow if you’re aggregating over large data volumes. - Querying a view that, in turn, calls an aggregation function with the
GROUP BY. Having your query saved as a view is handy, but it won’t actually improve your query latency since a view is a simple alias for your original query. - Querying a PostgreSQL materialized view of cached aggregates, also known as materialized aggregations. This will make your aggregate queries run faster since the materialized view will store previously computed results. However, you may not get up-to-date results.
As you can see, these options have shortcomings and may not get the job done—and that's when continuous aggregates come in handy. Continuous aggregates allow you to materialize aggregations well ahead of time so that your application can quickly retrieve the cached aggregates without waiting for them to be computed at query time.
That leads us to the fourth data aggregation method:
4. Querying a continuous aggregate: when you query a TimescaleDB continuous aggregate, it combines cached aggregated values from materialized aggregations with the newer data that has not been materialized. It provides an efficient and low-impact mechanism to refresh materialized aggregates more frequently for up-to-date results.
How continuous aggregates work
Materialization in PostgreSQL allows you to pre-compute aggregations over your data and makes them available as cached values. This provides snappy response times to your application when querying these cached values.
But while materialized views are commonplace in PostgreSQL, refreshing one after data insert, update, or delete is often a compute-intensive exercise that materializes aggregates for the full view. This process unnecessarily consumes additional CPU and memory resources for underlying data that has not changed and may leave the materialized view unavailable to your application.
With continuous aggregates, Timescale introduced a far superior method to speed up your application queries for aggregates. This method continuously and intelligently refreshes your materialization for new inserts and updates to the underlying raw data. It provides more flexibility over how soon your materialized aggregates are refreshed while keeping your continuous aggregates available.
For added data aggregation speed and storage savings, try our hierarchical continuous aggregates: using this Timescale innovation, you don't have to roll up your data from the raw dataset; you can simply create a continuous aggregate on top of another continuous aggregate. For the sake of this blog post, we'll focus on regular continuous aggregates, but you can check out this article to start experimenting with hierarchical continuous aggregates.
How to Obtain Fast Data Aggregation With Continuous Aggregates
So, how can you use continuous aggregates to improve upon materialized views and speed up data access, particularly when data changes quickly? First, you need to ensure you're using them in a correct way that's tailored to your use case.
To do this, we gathered our Support team's recommendations on how to get the best performance from continuous aggregates (we lovingly call them "caggs"), speeding up your data aggregations in PostgreSQL.
But first, a quick note: Although powerful, it’s worth mentioning that continuous aggregates come with some limitations. For example, they require a time_bucket function, and you can only query one hypertable in your continuous aggregate definition query.
Here is a simple example of a continuous aggregate definition that we will reference, when needed, throughout the blog. This is based on our device ops medium-sized sample dataset.
CREATE MATERIALIZED VIEW device_battery_daily_avg_temperature
WITH (timescaledb.continuous) AS
SELECT
time_bucket('1 day', time) as bucket_day,
device_id,
avg(battery_temperature) as battery_daily_avg_temp
FROM readings
GROUP BY device_id, bucket_day
WITH NO DATA;
You can refer to our documentation for more details on creating continuous aggregates and their limitations. Now, let’s jump to the tips.
Create a refresh policy
Continuous aggregates stay automatically updated via a refresh policy defined by you. This means you can configure your continuous aggregate view to update automatically in your desired time interval, including your latest data.
Here's how to start:
Create a refresh policy
SELECT add_continuous_aggregate_policy('device_battery_daily_avg_temperature',
start_offset => INTERVAL '3 days',
end_offset => INTERVAL '1 hour',
schedule_interval => INTERVAL '1 day');
Now, if you're a Timescale user, have you ever found yourself in the following scenarios?
- You created a continuous aggregate, and your query’s performance has not improved.
- You created a continuous aggregate, and initially, your query’s performance was great, but it degraded over time.
- You created a continuous aggregate, and your materialized aggregates have progressively become inaccurate.
If this sounds familiar, it is very likely that you do not have a continuous aggregate refresh policy (a.k.a. refresh policy) or that the policy has yet to run.
Look for any policy job using the following query:
select * from timescaledb_information.jobs;
Look for policy execution using the following query:
select * from timescaledb_information.job_stats;
Finally, create a refresh policy—like in the example above—if it doesn't exist.
Aim to create a continuous aggregate WITH NO DATA
As a general recommendation from Support, we advise creating a continuous aggregate with the WITH NO DATA option. By default, creating a continuous aggregate without that option materializes aggregates across the entire underlying raw data hypertable, regardless of when the cagg creation occurred.
Instead, let the continuous aggregate policy do the job for you. And if your underlying raw data hypertable has historical data older than start_offset in your cagg policy, you can manually and progressively refresh it using refresh_continuous_aggregate.
Note that you can have filters on time in your continuous aggregate query definition. This means you can limit which time buckets will materialize by defining the underlying raw data over which to aggregate. This is very rare since a continuous aggregate is expected to continuously materialize time buckets for newer underlying raw data.
Continuous aggregates come in two variations: materialized_only and real-time. By default, continuous aggregates are real-time aggregates. The latter allows you to query and compute in real-time aggregates over newer time buckets (in time, that is) that have not been materialized.
Interestingly, the continuous aggregate determines the data that needs to be aggregated in real time based on a watermark for the most recently materialized time_bucket. Therefore, a newly created continuous aggregate WITH NO DATA has a watermark that is either NULL or set to a time (i.e., 4714-11-24 00:00:00+00 BC) way back in the past. We hope you aren’t collecting data with prehistoric timestamps before that watermark.
Long story short, you can query your cagg for aggregates on any time_bucket over your entire underlying raw data hypertable. However, the aggregates are computed in real time as nothing is yet materialized.
Checking the watermark:
- Get the cagg ID.
SELECT id from _timescaledb_catalog.hypertable
WHERE table_name=(
SELECT materialization_hypertable_name
FROM timescaledb_information.continuous_aggregates
WHERE view_name='device_battery_daily_avg_temperature'
);
- Use the cagg ID to get its current watermark.
SELECT COALESCE(
_timescaledb_internal.to_timestamp(_timescaledb_internal.cagg_watermark(17)),
'-infinity'::timestamp with time zone
);
So, what happens when you have a year’s worth of underlying raw data and create a continuous aggregate with daily time buckets WITH NO DATA accompanied by a continuous aggregate policy that materializes/refreshes aggregates for the last three months of your data?
Before any time buckets are materialized, you will be able to query the daily aggregate all the way back to the earliest underlying raw data point. As soon as the continuous aggregate policy executes its first run, the daily aggregations now available to your query will only go as far back as three months from the time of this first policy run.
So, if you ever find yourself wondering why your continuous aggregate data disappeared partially or in full, check again.
Schedule your refresh policy to match your use case
Once aggregations for any given time bucket are materialized, their values will not change until the next refresh, at the very earliest. Therefore, materialized aggregates may get outdated, especially for ingest workloads with backfills. However, they remain current for append-only ingest workloads.
Depending on how quickly your materialized aggregates get out of date due to incoming data backfills, you may need to set up your refresh policy to run more frequently.
For append-only workload, schedule your refresh policy to run once per day.
SELECT add_continuous_aggregate_policy('device_battery_daily_avg_temperature',
start_offset => INTERVAL '3 days',
end_offset => INTERVAL '1 day',
schedule_interval => INTERVAL '1 day');
For backfill workload, schedule the refresh policy to run multiple times per day (or as frequently as necessary based on your application requirements).
SELECT add_continuous_aggregate_policy('device_battery_daily_avg_temperature',
start_offset => INTERVAL '3 days',
end_offset => INTERVAL '1 day',
schedule_interval => INTERVAL '30 minutes');
There are many factors to consider when choosing your continuous aggregate refresh policy schedule:
- The accuracy requirements for materialized aggregations
- Whether your ingest workload includes backfill
- The
time_bucketinterval in the continuous aggregate’s query definition
With an append-only ingest workload (a.k.a. data ingested with increasing timestamps), refreshing existing materialized aggregations is essentially a no-op. Therefore, the schedule interval need not be shorter than the time_bucket interval. Additionally, the most recent time_bucket will not be materialized until (now() - end_offset) is greater or equal to midnight the following day.
And then, when we add backfill ingest workload, the accuracy of caggs’ materialized aggregations and how soon they should be refreshed for your application becomes essential.
The materialized aggregation for any given time_bucket immediately goes out of date as soon as new data is ingested into the time_bucket time window. As such, your application’s requirements on how soon out-of-date materialized aggregations should be refreshed determine the policy schedule.
Save storage by managing data wisely
Once you have materialized your aggregation, do you still need the underlying raw data? Sometimes, the answer is “no.” Numerous use cases rely on visualizing data and primarily rely on continuous aggregates to retrieve and display data at various rollups quickly.
For instance, we may visualize device battery temperatures for the last day using raw data, show temperatures for the last month using daily averages, and finally, show temperatures for the last year using weekly averages. In this case, raw data only needs to be kept in the hypertable for up to a week, just enough time to compute the aggregates for the last week for the weekly continuous aggregate.
Creating a continuous aggregate and refresh policy for device battery daily average temperature:
CREATE MATERIALIZED VIEW device_battery_daily_avg_temperature
WITH (timescaledb.continuous) AS
SELECT
time_bucket('1 day', time) as bucket_day,
device_id,
avg(battery_temperature) as battery_daily_avg_temp
FROM readings
GROUP BY device_id, bucket_day
WITH NO DATA;
SELECT add_continuous_aggregate_policy('device_battery_daily_avg_temperature',
start_offset => INTERVAL '3 days',
end_offset => INTERVAL '1 hour',
schedule_interval => INTERVAL '1 day');
Creating a continuous aggregate and refresh policy for device battery weekly average temperature:
CREATE MATERIALIZED VIEW device_battery_weekly_avg_temperature
WITH (timescaledb.continuous) AS
SELECT
time_bucket('1 week', time) as bucket_week,
device_id,
avg(battery_temperature) as battery_weekly_avg_temp
FROM readings
GROUP BY device_id, bucket_week
WITH NO DATA;
SELECT add_continuous_aggregate_policy('device_battery_weekly_avg_temperature',
start_offset => INTERVAL '2 weeks',
end_offset => INTERVAL '1 hour',
schedule_interval => INTERVAL '1 week');
Create a retention policy on the ‘readings’ hypertable to drop the raw data after at least a week (using three weeks to avoid any boundary issues, so we don’t drop the data before the weekly policy has materialized the aggregate over the most recent week). Here's how:
SELECT add_retention_policy('readings', INTERVAL '3 weeks');
As a note of caution, one must also take special care when revising the continuous aggregate policy or manually refreshing the continuous aggregate. Refreshing a continuous aggregate’s time window for which raw data has been deleted will result in the continuous aggregate either losing data for time_buckets with no underlying raw data or inaccurate data for time_buckets with partially deleted underlying raw data.
To expand on what we just wrote, we can also drop previously materialized aggregates from your continuous aggregate once the data is no longer needed.
Retention policy on the daily average temperature continuous aggregate to drop data after a month:
SELECT add_retention_policy('device_battery_daily_avg_temperature', INTERVAL '1 month’');
Retention policy on the weekly average temperature continuous aggregate to drop data after a year:
SELECT add_retention_policy('device_battery_weekly_avg_temperature', INTERVAL '1 year');
Each continuous aggregation you create will consume additional storage. With very large data, aggregation on smaller time buckets can amount to significant additional storage consumption. Therefore, consider compressing aggregated data older than your continuous aggregates' refresh policy’s window_start parameter value.
For more details, see our introduction to compression on continuous aggregate in our blog Increase Your Storage Savings With TimescaleDB 2.6: Introducing Compression for Continuous Aggregates.
Enabling compression on the continuous aggregate:
ALTER MATERIALIZED VIEW device_battery_daily_avg_temperature SET (timescaledb.compress = true);
Set up the compression policy. Note that the policy’s compress_after setting must be greater than the refresh policy window_start. In our case, compress_after is set to seven days, while the refresh policy window_start is set to three days.
SELECT add_compression_policy('device_battery_daily_avg_temperature', INTERVAL '7 days');
Change the chunk_time_interval
By default, when a continuous aggregate is created, the internal hypertable is assigned a chunk_time_interval that is 10x the chunk_time_interval of the hypertable with underlying raw data that our continuous aggregate query is aggregating. For instance, a seven-day chunk_time_interval for the queried hypertable turns into a 70-day chunk_time_interval for the continuous aggregate’s internal hypertable.
At continuous aggregate creation, there is no option to set the chunk_time_interval. However, the value for this config parameter can be modified manually on the continuous aggregate’s internal hypertable to a more convenient chunk_time_interval that meets your requirements.
Finding the internal hypertable for your continuous aggregate:
SELECT
materialization_hypertable_schema || '.' || materialization_hypertable_name
FROM timescaledb_information.continuous_aggregates
WHERE
view_schema = 'public' and
view_name = 'device_battery_daily_avg_temperature';
Use the name of the internal hypertable in the result from the above query to change the cagg’s chunk_time_interval.
SELECT set_chunk_time_interval('_timescaledb_internal._materialized_hypertable_17', INTERVAL '2 weeks');
Create an index on your aggregated columns
Oh well, if you must, TimescaleDB 2.7 introduced the next iteration of our continuous aggregates in which all aggregated values are finalized. This means that you can now create an index on an aggregated column, enabling you to speed up queries with filters on a continuous aggregate’s aggregated columns.
Align your time bucket to your time zone
About a year ago, we introduced an experimental time_bucket_ng function to support monthly and yearly time buckets and time zones. We have since deprecated time_bucket_ng and ported most of its functionality to the original time_bucket function. For additional details, see our blog post Nightmares of Time Zone Downsampling: Why I’m Excited About the New time_bucket Capabilities in TimescaleDB.
Now, you can create a continuous aggregate and align the time buckets to a specific time zone rather than the default UTC time zone. Note that you will need a continuous aggregate per time zone to support multiple time zones. And we hope that each of your continuous aggregates' query definitions will filter out data that does not belong to its time zone.
Here’s how you can create a continuous aggregate and align the device battery's daily average temperature to India's standard time:
CREATE MATERIALIZED VIEW device_battery_daily_avg_temperature_India
WITH (timescaledb.continuous) AS
SELECT
time_bucket('1 day', time, 'Asia/Kolkata') as bucket_day,
device_id,
avg(battery_temperature) as battery_daily_avg_temp
FROM readings
GROUP BY device_id, bucket_day
WITH NO DATA;
Querying the continuous aggregate and shifting bucket times to India’s standard time:
SELECT
bucket_day::timestamptz AT TIME ZONE 'Asia/Kolkata' as India_bucket_day,
*
FROM device_battery_daily_avg_temperature_India;
Continuous Aggregates: Things to Remember
Remember that your refresh policy materializes aggregates for time buckets between now() and the past.
The continuous aggregate policy will only materialize aggregates for time buckets that fit entirely within the refresh time window. now() is the latest possible time for a continuous aggregate policy refresh time window. Therefore, the refresh policy will only materialize aggregates for time buckets before now().
You can manually materialize aggregates for any time bucket—past, present, and future.
Using refresh_continuous_aggregate, you can manually materialize aggregations for any time bucket, past, present, and future. To do this, specify a refresh time window that fully overlaps with the desired time bucket.
For instance, if you have a continuous aggregate for daily temperature averages, you can materialize today's averages (even if today’s bucket is still receiving new data) by defining a refresh time window that starts at/before midnight today and ends at/after midnight tomorrow.
So hypothetically, if today’s date is November 16, 2016, manually materializing aggregates for that date would look as follows:
CALL refresh_continuous_aggregate('device_battery_daily_avg_temperature',
window_start => '2016-11-16 00:00:00+00',
window_end => '2016-11-17 00:00:00+00');
More data to process, more time to refresh.
The performance of a continuous aggregate refresh will depend on the amount of data processed. If you create two continuous aggregates that query the same hypertable but with different time_buckets, the continuous aggregate with the query on larger time_buckets (i.e., month) will take longer to refresh compared to the continuous aggregate with the query on smaller time_buckets (i.e., day).
However, if your data ingestion involves a significant amount of backfilling data with timestamps in the past, it all comes down to the refresh time window rather than the time_bucket.
Get Better PostgreSQL Data Aggregation With Timescale
Working with customers every day, the Timescale Support Team has no doubts that continuous aggregates are one of the most loved TimescaleDB features—just read (or watch) what the folks at Density had to say about them. We hope these tips will help you follow some best practices for improved performance and speed when using continuous aggregates.
And you know what they say, seeing it is believing it: if you want to test how continuous aggregates can make a difference in your applications, sign up for a free Timescale account day. You’ll get to experiment with continuous aggregates (and so much more!), and we’ll be happy to assist you along the way.



