

Speed Up Grafana by Auto-Switching Between Different Aggregations With Postgres
Learn how (and why) to speed up your Grafana drill-downs using PostgreSQL to allow "auto-switching" between aggregations, depending on the time interval you select.
The problem: Grafana is slow to load visualizations, especially for non-aggregated, fine-grained data
The Grafana UI is great for drilling down into your data. However, for large amounts of data with second, millisecond, or even nanosecond time granularity, it can be frustratingly slow and result in higher resource usage.
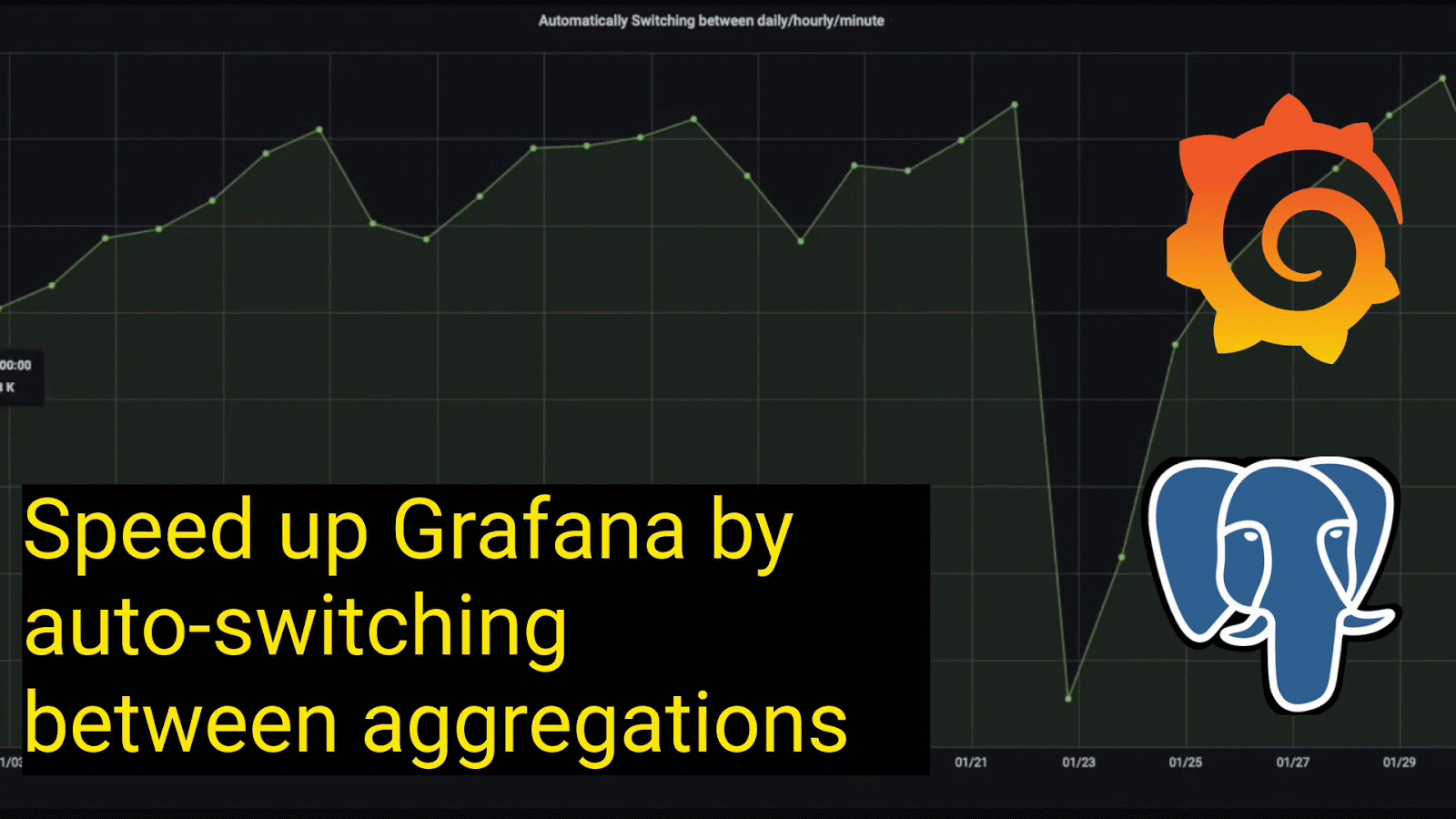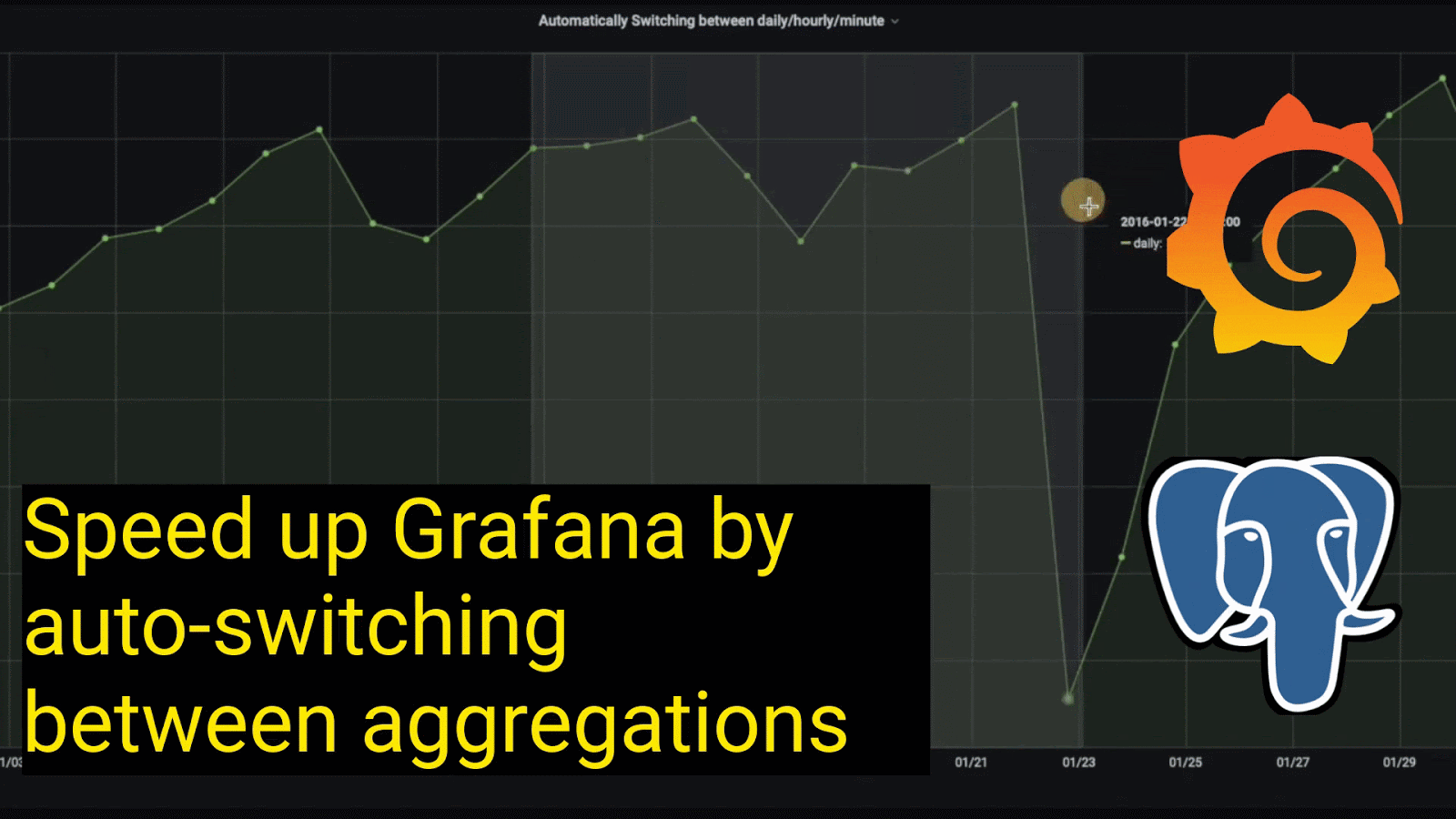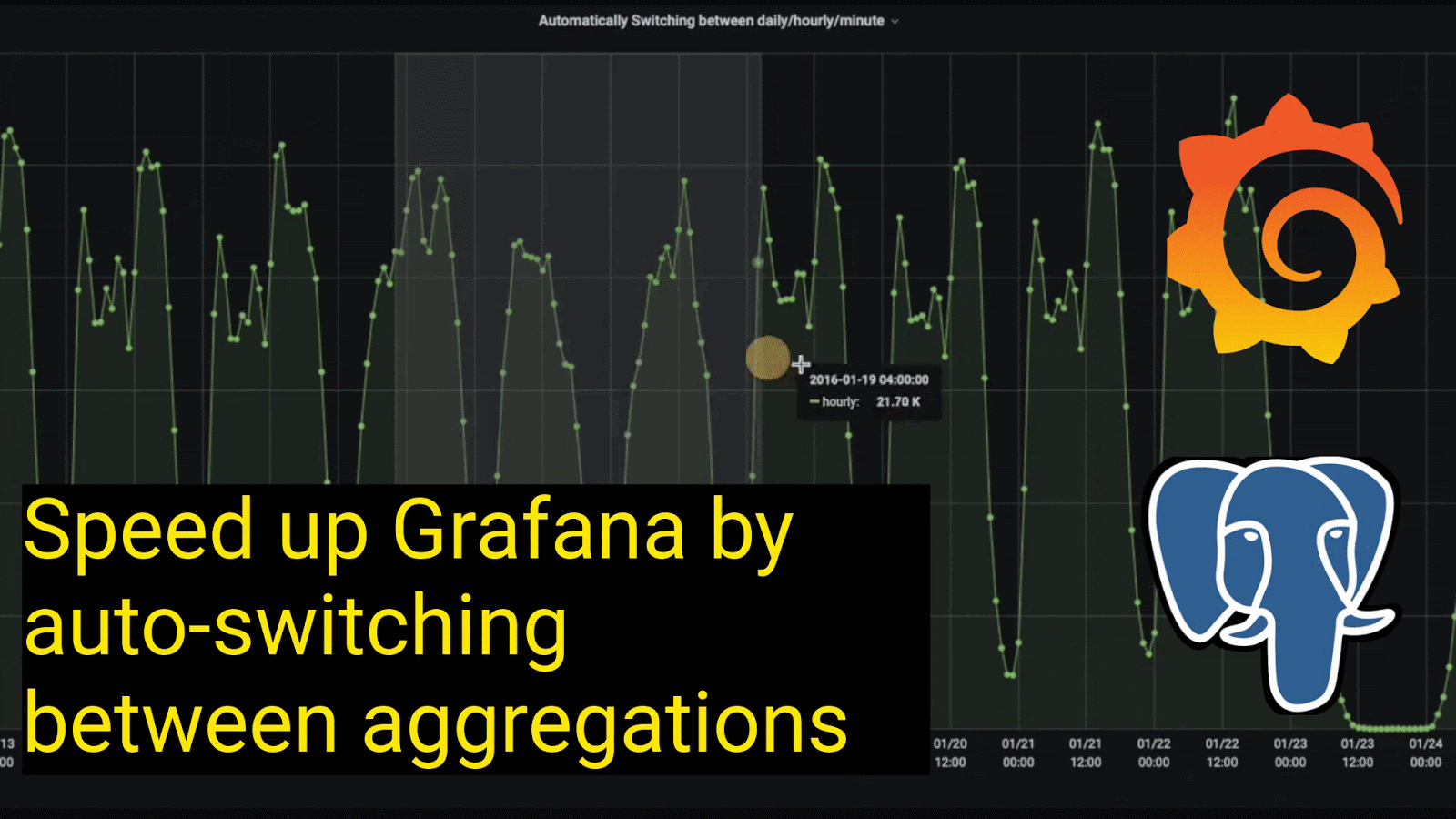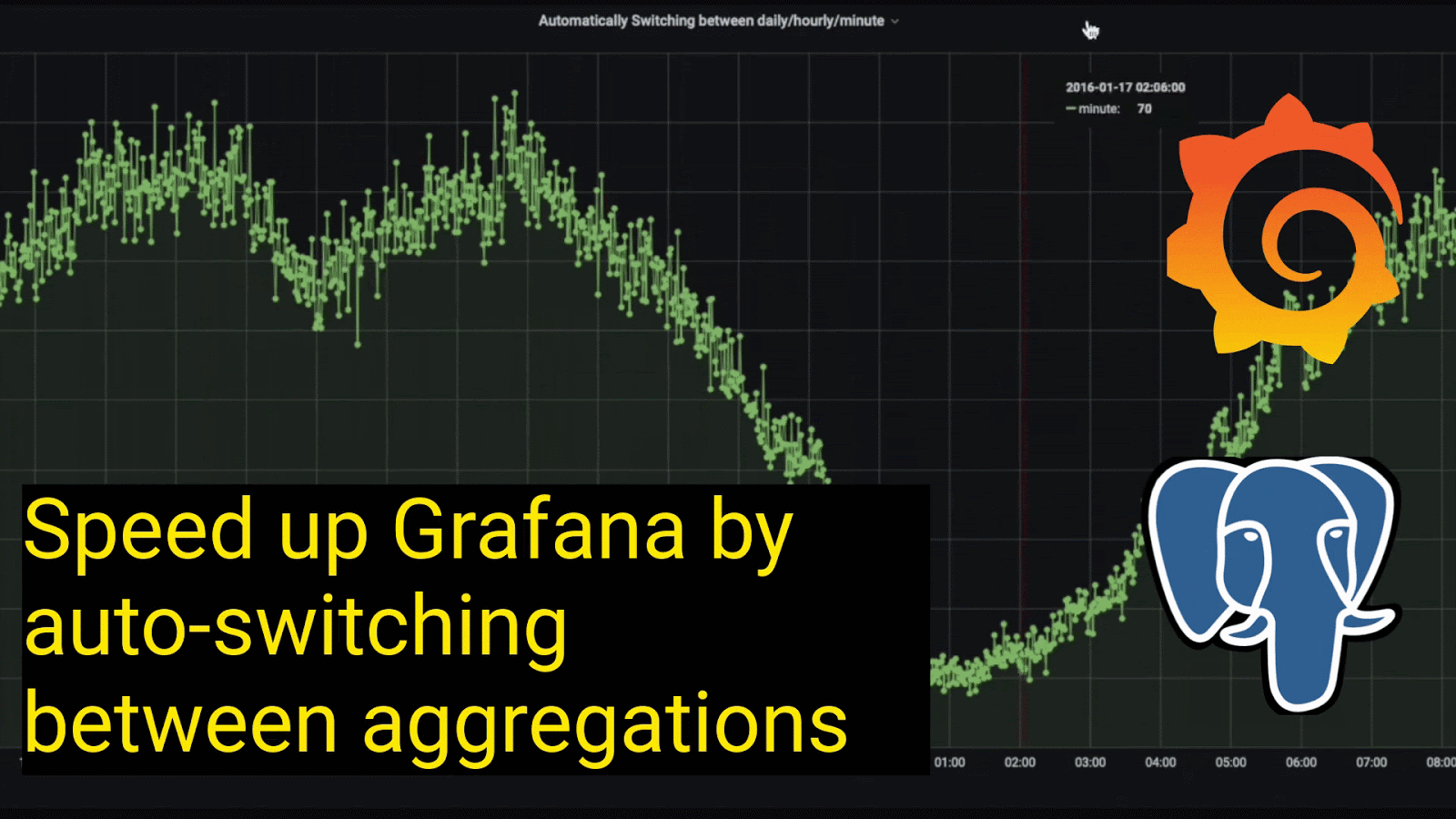
For example, take this graph of all New York City taxi rides during the month of January 2016:

One common workaround: instead of querying raw data and aggregating on the fly, you query and visualize data from aggregates of your raw data (e.g., one-minute, one-hour, or one-day rollups).
For PostgreSQL data sources, we do this by aggregating data into views and querying those instead, and for TimescaleDB, we use continuous aggregates—think “automatically refreshing Postgres views” (for more, see the continuous aggregates docs).
However, this often leads to several Grafana panels, each querying the same data aggregated at different granularities. For example, you might capture the same metric over time but set up aggregates at various intervals, such as in minute, hourly, and daily intervals.
This then requires three separate panels, one for each aggregated interval.

But, what if we could use one universal panel that could “automatically” switch between minute, hourly, daily, or any other arbitrary aggregations of our data, depending on the time period we’d like to query and analyze? This would speed up queries and use resources like CPU more efficiently.
Enter the PostgreSQL UNION ALL function.
The Solution: Use Postgres UNION ALL
When we use PostgreSQL as our Grafana data source, we can write a single query that automatically switches between different aggregated views of our data (e.g., daily, hourly, weekly views, etc.) in the same Grafana visualization (!).
🔑 The key: we (1) use the UNION ALL function to write separate queries to pull data with different aggregations, and (2) then use the WHERE clause to switch the table (or continuous aggregate view) being queried, depending on the length of the time-interval selected (from either the time picker or by highlighting the time period in a graph).
This allows us to drill arbitrarily deep into our data and makes loading the data as efficient and fast as possible, saving time and CPU resources. (In Grafana, drilling into data is typically done by zooming in and out, highlighting the time period of interest in the graph as shown in the image below.)

Try It Yourself: Implementation in Grafana & Sample Queries
To help you get up and running with UNION ALL, I’ve put together a short step-by-step guide and a few sample queries (which you can modify to suit your project, app, and the metrics you care about).
Scenario
We’ll use the use case of monitoring IoT devices, specifically taxis equipped with sensors. For reference, we’ll use a dataset containing all New York City taxi ride activity for January 2016 from the New York Taxi and Limousine Commission (NYC TLC).
Prerequisites
- TimescaleDB instance (Timescale Cloud or self-hosted) running PostgreSQL 11+
- Grafana instance (cloud or self-hosted)
- TimescaleDB instance connected to Grafana (see this tutorial for more)
- Use the queries below to create two continuous aggregates. These will be the aggregate views we switch between in our Grafana visualization:
To create daily aggregates:
CREATE VIEW rides_daily
WITH (timescaledb.continuous, timescaledb.refresh_interval = '1 day')
AS
SELECT time_bucket('1 day', pickup_datetime) AS day, COUNT(*) AS ride_count
FROM rides
GROUP BY day;SQL query to create daily aggregates of rides during January 2016
This computes a roll-up of the total number of rides taken during each day during the time period of our data (January 2016).
To create hourly aggregates:
CREATE VIEW rides_hourly
WITH (timescaledb.continuous, timescaledb.refresh_interval = '1 hour')
AS
SELECT time_bucket('1 hour', pickup_datetime) AS hour, COUNT(*) AS ride_count
FROM rides
GROUP BY hour;SQL query to create hourly aggregates of rides during January 2016
This computes a roll-up of the total number of rides taken during each hour during the time period of our data.
For more on how continuous aggregates work, see these docs.
Example 1: Auto-switch between daily aggregate, hourly aggregate, and raw data
In the example below, we have a query using UNION ALL, where we only select a specific table or view, depending on the length of time selected interval in the Grafana UI (controlled by the $__timeFrom and $__timeTo macros in Grafana).
As the comments in the code below show, we use daily aggregates for intervals greater than 14 days, hourly aggregates for intervals between 3 and 14 days, and per-minute aggregates calculated on the fly from raw data for intervals less than 3 days:
Switching between daily aggregation, hourly aggregation, and minute aggregations on raw data
-- Use Daily aggregate for intervals greater than 14 days
SELECT day as time, ride_count, 'daily' AS metric
FROM rides_daily
WHERE $__timeTo()::timestamp - $__timeFrom()::timestamp > '14 days'::interval AND $__timeFilter(day)
UNION ALL
-- Use hourly aggregate for intervals between 3 and 14 days
SELECT hour, ride_count, 'hourly' AS metric
FROM rides_hourly
WHERE $__timeTo()::timestamp - $__timeFrom()::timestamp BETWEEN '3 days'::interval AND '14 days'::interval AND $__timeFilter(hour)
UNION ALL
-- Use raw data (minute intervals) intervals between 0 and 3 days
SELECT * FROM
(SELECT time_bucket('1m',pickup_datetime) AS time, count(*), 'minute' AS metric
FROM rides
WHERE $__timeTo()::timestamp - $__timeFrom()::timestamp < '3 days'::interval AND $__timeFilter(pickup_datetime)
GROUP BY 1) minute
ORDER BY 1;Query to switch between daily aggregation, hourly aggregation, and per-minute aggregations created on the fly using raw data
This produces the following behavior in our Grafana panels:
Querying daily aggregates for intervals greater than 14 days:

Querying hourly aggregates for intervals between 3-14 days:

Querying raw data for intervals less than 3 days:

This allows you to automatically switch between different aggregations of data, depending on the length of the time interval selected. Notice how the granularity of the data gets richer as we drill down from looking at data over the month of January to looking at data in a single day:

Example 2: Auto-switch between daily, hourly, and 10-minute aggregates
Querying only from continuous aggregates allows us to speed up our dashboards even further. You might not want to directly query the hypertable that houses your raw data, as the queries may be slower due to things like new data being inserted into the hypertable.
The following example shows a query for switching between aggregations of different granularity without using the raw data hypertable at all (unlike Example 1, which does on-the-fly rollups of raw data).
First, let’s create 10-minute rollups of the raw data:
CREATE VIEW rides_10mins
WITH (timescaledb.continuous, timescaledb.refresh_interval = '10 minute')
AS
SELECT time_bucket('10 minutes', pickup_datetime) AS bucket, COUNT(*) AS ride_count
FROM rides
GROUP BY bucket;Query to create 10-minute rollups of data in a continuous aggregate
Switching between daily aggregation, hourly aggregation, and minute aggregations (no raw data involved)
-- Use Daily aggregate for intervals greater than 14 days
SELECT day as time, ride_count, 'daily' AS metric
FROM rides_daily
WHERE $__timeTo()::timestamp - $__timeFrom()::timestamp > '14 days'::interval AND $__timeFilter(day)
UNION ALL
-- Use hourly aggregate for intervals between 3 and 14 days
SELECT hour, ride_count, 'hourly' AS metricFROM rides_hourly
WHERE $__timeTo()::timestamp - $__timeFrom()::timestamp BETWEEN '3 days'::interval AND '14 days'::interval AND $__timeFilter(hour)
UNION ALL
-- Use raw data (minute intervals) intervals between 0 and 3 days
SELECT bucket, ride_count, '10min' AS metric
FROM rides_10mins
WHERE $__timeTo()::timestamp - $__timeFrom()::timestamp < '3 days'::interval AND $__timeFilter(bucket)
ORDER BY 1; Query to switch between daily aggregation, hourly aggregation, and per-minute aggregations, all using continuous aggregates
In this post, we saw how to use UNION ALL to automatically switch which aggregate view we’re querying on based on the time interval selected so that we can do more efficient drill downs and make Grafana faster
You can find more information about the UNION ALL function and how it works in this PostgreSQL tutorial—from the aptly named PostgreSQLtutorial.com—and “official” PostgreSQL documentation.
That’s it! You can modify this code to change the aggregates you query, time intervals, and the metrics you want to visualize to suit your needs and projects.
Happy auto-switching!
Next Steps
In this tutorial, we learned how to use PostgreSQL UNION ALL to solve a common Grafana issue: slow-loading dashboards when we want to query fine-grained raw data (like millisecond performance metrics).
The result: you create graphs that enable you to switch between different aggregations of your data automatically. This allows you to quickly drill down into your metrics, saving time and CPU resources!
For more resources to speed up Grafana performance, learn how you can fix slow dashboards using downsampling.
Learn more
Want more Grafana tips? Explore our Grafana tutorials.
Need a database to power your dashboarding and data analysis? Get started with a free Timescale account.



