

Compression Faceoff: Postgres TOAST vs Timescale Compression

Database compression is a critical technique in the world of data management—and an infamous gap in the PostgreSQL toolkit. Even if TOAST (The Oversized-Attribute Storage Technique) plays a pivotal role in PostgreSQL when it comes to efficiently storing large data values, it is not functional nor efficient enough to serve as a modern database compression mechanism.
But we’ll let the numbers prove our point! In this blog post, we show you how Timescale’s columnar compression can help you reduce your PostgreSQL database size (in a way that TOAST could never do!) by running a comparative analysis between both compression techniques.
You can then learn how the Timescale compression mechanism works and get advice on implementing it: Timescale is fully built on PostgreSQL, and you can try it for free to experiment with compression in your PostgreSQL databases.
PostgreSQL TOAST: A Quick Recap
In essence, TOAST is PostgreSQL's built-in method for managing large data values that don't fit within its fixed page size (8 kB). It compresses these oversized values and, if they're still too large, moves them to a separate TOAST table, leaving pointers in the original table.
- What Is TOAST (and Why It Isn’t Enough for Data Compression in Postgres)
- Building Columnar Compression for Large PostgreSQL Databases
However, TOAST is not a comprehensive solution for data compression in PostgreSQL. Its primary role is to manage large values within a Postgres page, not to optimize overall storage space. TOAST lacks user-friendly mechanisms for dictating compression policies, and accessing TOASTed data can add overhead, especially when stored out of line.
To give PostgreSQL a more modern compression mechanism, Timescale introduced columnar compression to PostgreSQL through the TimescaleDB extension. This columnar method can significantly reduce the size of your large PostgreSQL databases by up to 10x, with over 90 % compression rates, by shifting from PostgreSQL’s row-based storage to a columnar approach. This columnar compression not only reduces storage needs but also improves query performance, making PostgreSQL databases much more easily scalable.
TOAST vs. Timescale Compression: Comparing Compression Rates
Before getting into what Timescale compression is all about (and how to configure it if you decide to test it), let’s jump straight into the purpose of this blog post—to see how Timescale compression compares to TOAST in terms of compression ratios. We want to know which compression technique is more effective at reducing PostgreSQL storage.
To run this comparison, we used the table structures and other helper functions found in this repo. To compare the effects of different TOAST strategies and Timescale compression, we looked at the size of the following tables:
hit_uncompressed: A regular PostgreSQL heap table with TOAST strategy set toexternal, no compression applied.hit_compressed_pglz: Regular table with TOAST set tomain, usingPGLZfor default_toast_compression.hit_compressed_lz4: Similar to above, but usingLZ4for default_toast_compression.hit_hyper_compressed: A compressed hypertable (with Timescale compression) with 22 compressed chunks.
Initially, we loaded a 70 GB dataset with around 100 million rows. These are the sizes of each table and the compression ratio in each case:
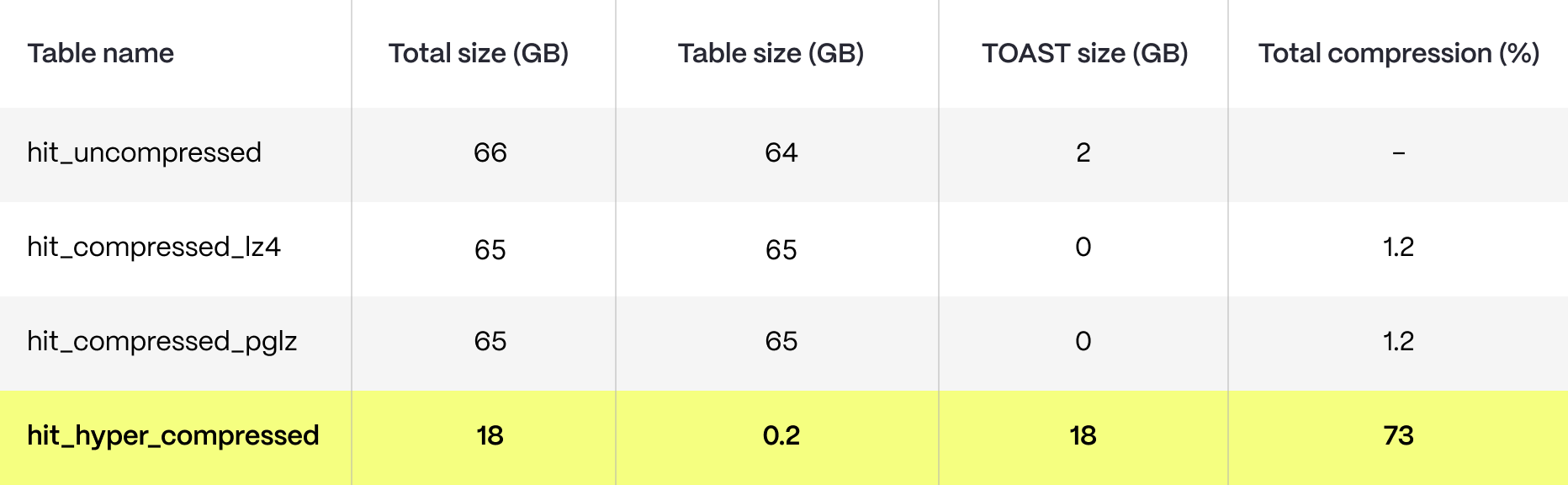
Note: We are not including index sizes here as most of the indexes applied to the hypertable are disregarded or eliminated. Timescale creates internal indexes on compress_segmentby and compress_orderby columns when applying compression—more on that later.
In this case, it's evident that TOAST compression offers only marginal advantages in terms of reducing the table size. As we argued in this blog post, TOAST is effective in compressing larger data values but doesn’t have a mechanism for reducing table sizes independently of the size of the individual rows. On the contrary, Timescale compression yields a 72 % reduction in storage requirements for this particular table.
To illustrate better the nature of TOAST, we ran another test, this time introducing a new column named payload with a JSONB data type, populating it with randomly generated data ranging in size from 1 byte to 3 kilobytes. This is how the results varied:
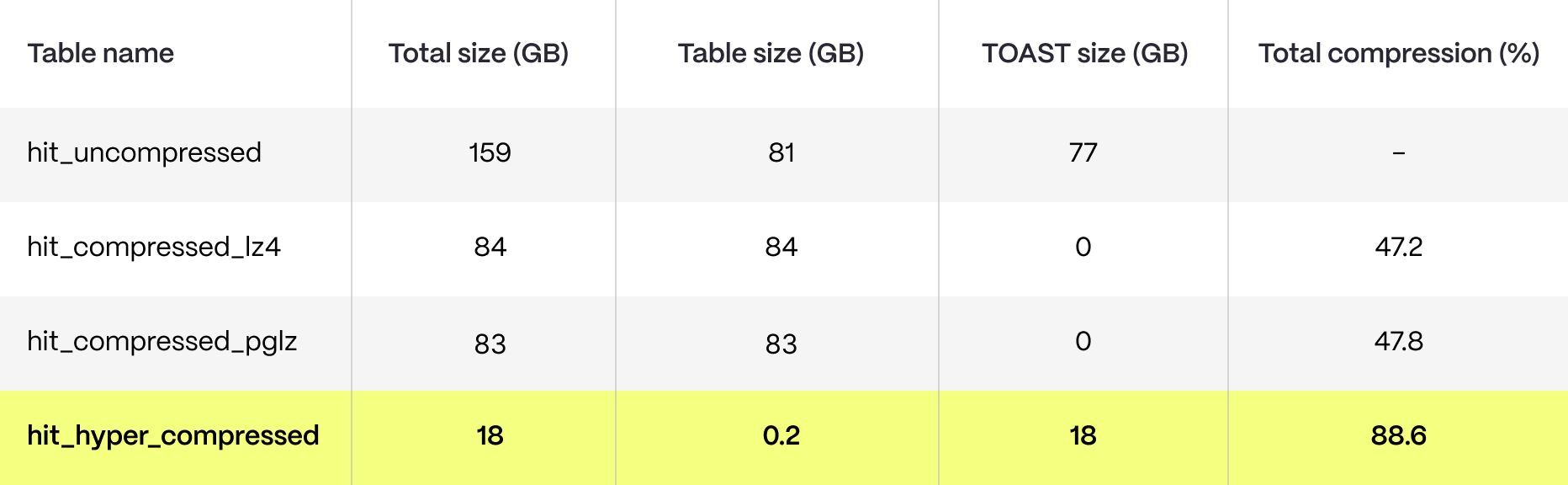
As you can see, TOAST results improve when the JSONB column is introduced. JSONB columns often contain more complex and larger data structures than plain text or numeric data—therefore, TOAST is more effective at compressing it.
Still, Timescale compression performs much better. Timescale's columnar compression is particularly adept at handling complex data types like JSONB; this format often contains repetitive and patterned data, which especially fits Timescale’s columnar storage. Timescale also applies different algorithms optimized for various data types, including LZ4 for JSONB values. With further optimization, Timescale’s compression rate could even improve—many Timescale users see compression rates over 90 %!
Implementing Timescale Compression
Let’s walk you through the mechanics of implementing Timescale compression, briefly covering how it works architecturally and how you configure it as a user—so you can test it out more effectively afterward. If you’re already up to date with Timescale compression, feel free to skip this section.
Timescale compression architecture
In Timescale, compression operates at the level of individual chunks (partitions) in a hypertable. Each compressed chunk utilizes a hybrid row-columnar format, where 1,000 rows of uncompressed data are grouped together and transformed into column segments.
The primary objective here is to consolidate this data into a single row, thereby eliminating the need for numerous rows to accommodate the same information. This design also allows the Timescale engine to apply various compression algorithms depending on the data type, such as Gorilla compression for floats and delta-of-delta with Simple-8b and run-length encoding for timestamps and integer-like types.
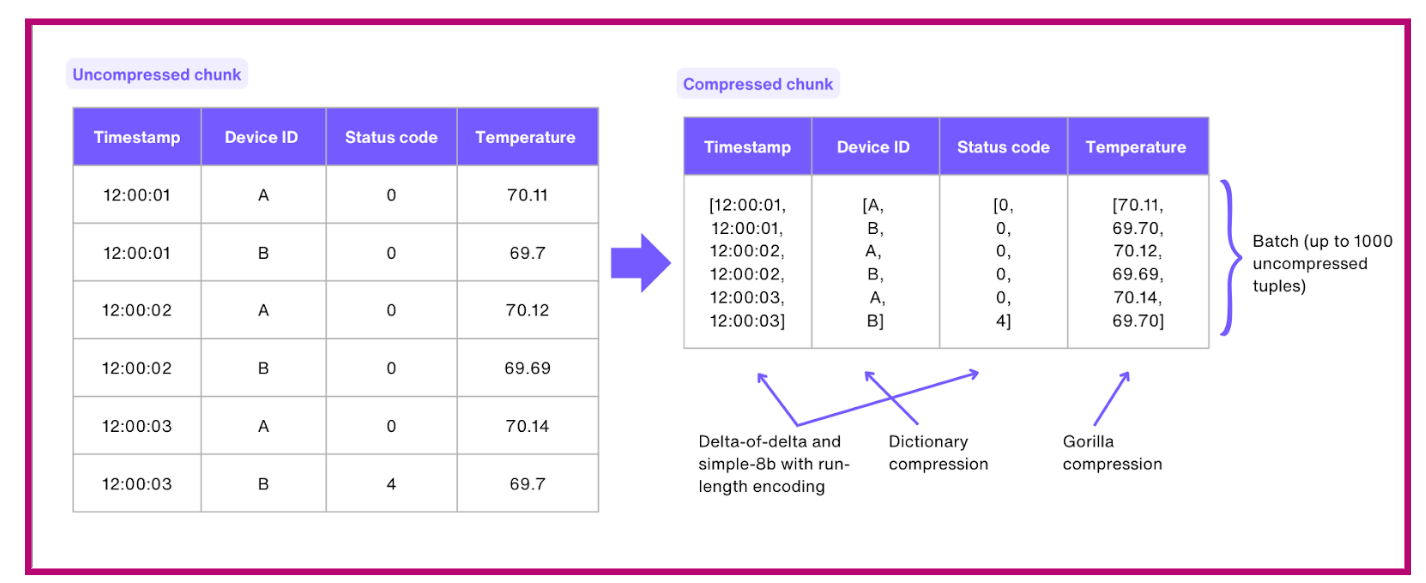
Let's delve further into the mechanics of how this process operates:
- As we previously mentioned, Timescale's compression operates on individual chunks in a hypertable. The chunks, once identified by a user-defined compression policy based on their age, undergo a transformation process.
- When this transformation process begins, it then consolidates multiple records within each chunk into a single row with an array-like structure. This leads to a substantial reduction in storage overhead, as we’ll see later. For instance, in the case of a chunk containing 10,000 records, this process can generate 10 rows, each housing thousands of arrayed values per column.
- Following the consolidation of records, TimescaleDB employs compression algorithms tailored to each column based on their data types.
- Utilizing properties such as
timescaledb.compress_orderbyandtimescaledb.compress_segmentbycan further optimize the compression process. - If
timescaledb.compress_orderbyproperty is used, items inside the array are ordered based on the specified columns before compression. This operation functions similarly to the SQLORDER BYclause. By default,compress_orderbyto the hypertable's time column inDESCorder. - If
timescaledb.compress_segmentbyproperty is enabled, these columns are used for grouping the compressed data rows. This should be applied when the column is used in the query'sWHEREclause. It's worth noting that thecompress_segmentbycolumn will remain in an uncompressed state (which we will see in the upcoming example). By default,compress_segmentbyis set to null. - After Timescale compression, if the size of the compressed row exceeds the
TOAST_TUPLE_THRESHOLD(2 kB), that row is relocated to a secondary storage location (the toast table), and a pointer is established within the chunk to reference this data.
Enabling Timescale compression
To enable compression in a particular hypertable, you would define a compression policy that automatically compresses chunks (partitions) once they reach a certain age. For example, the compression policy below automatically compresses all chunks older than seven (7) days:
ALTER TABLE <HyperTable> SET (
timescaledb.compress,
timescaledb.compress_orderby = 'col1 ASC/DESC, col2',
timescaledb.compress_segmentby = 'col1, col2, ...'
);
-- Set Compression Policy
SELECT add_compression_policy('test', INTERVAL '7 days');
If you wish, you could also manually compress individual chunks, for example, if you want to run some tests to experiment with compression:
SELECT compress_chunk('<chunk_name>');
Understanding the role of orderby and segmentby in Timescale compression
The process of compression changes how indexes are used on hypertables: since we’re switching to columnar storage, most traditional indexes applied to the hypertable are no longer utilized after compression. To still allow for efficient querying and ingestion, Timescale leverages specialized indexes that are tailored to work with the compression setup via the compress_orderby and compress_segmentby parameters we mentioned earlier.
compress_orderby is a parameter that dictates the ordering of data within each compressed chunk. It functions similarly to the SQL ORDER BY clause, helping to organize data in a way that optimizes compression efficiency and query performance.
compress_segmentby is used for grouping data within the compressed chunks. It's especially useful for queries that frequently access certain columns, as it ensures that these columns are stored together, enhancing the efficiency of data retrieval.
Let’s look at a practical example to understand how compress_orderby and compress_segmentby influence compression. Consider this example hypertable:
Now, let’s compress the previous hypertable with compress_segmentby = null and compress_orderby = timestamp desc:
ALTER TABLE example_hypertable SET (
timescaledb.compress,
timescaledb.compress_orderby = 'timestamp DESC'
);
SELECT add_compression_policy('example_hypertable', INTERVAL '7 days');
By applying ORDER BY according to timestamp desc, we’re sorting the records from the most recent to the oldest based on the timestamp column—something like this:
Then, the compression engine would merge the rows into an array format, giving the compressed chunk its columnar look:
When the ORDER BY timestamp desc is applied without setting the compress_segmentby parameter, the resulting arrays for each column contain values that appear random and are not grouped by any specific category or attribute—this won’t result in very efficient compression ratios.
The compress_segmentby parameter can be utilized to enhance the efficiency of Timescale compression. Setting this parameter would allow the compression engine to group rows based on certain columns, leading to arrays with more similar values, which is more conducive to efficient compression.
For instance, segmenting by device_id would group similar device records together, potentially offering better compression outcomes. Let’s see how this would look by compressing the hypertable with compress_segmentby = device_id and compress_orderby = timestamp desc:
ALTER TABLE example_hypertable SET (
timescaledb.compress,
timescaledb.compress_orderby = 'timestamp DESC',
timescaledb.compress_segmentby = 'device_id'
);
SELECT add_compression_policy('example_hypertable', INTERVAL '7 days');
This configuration will first order the data by timestamp in descending order and then segment it by device_id. This means that within each compressed chunk, records will be organized first by time and then grouped according to theirdevice_id, leading to potentially more efficient compression as similar device records are clustered together.
Our compressed chunk would now look like this:
This reorganization results in each device_id having its own set of arrays for cpu, disk_io, and timestamp. Such clustering makes the data more homogeneous within each segment, which is beneficial for compression algorithms. Queries that filter based on device_id will be more efficient due to this logical grouping and the relative homogeneity of values within each segment leads to a better compression ratio—as similar values are more effectively compressed when stored adjacently.
Best Practices for Timescale Compression
To optimize storage reduction with Timescale compression, consider these best practices:
- Ensure each hypertable chunk has a significant number of records, and adjust the
chunk_time_intervalsettings accordingly. - Set up a compression policy that aligns with your query patterns. Uncompressed chunks are better for frequent updates and shallow-and-wide queries on recent data, while compressed chunks are more efficient for aggregates and analytical queries.
- Use compress_segmentby columns in WHERE clauses for more efficient queries, allowing decompression to occur after filtering.
- When selecting
compress_segmentbyfields, avoid primary key columns, as they represent unique values and are less amenable to compression. - Avoid too many
compress_segmentbycolumns: this can reduce the number of items per compressed column, diminishing compression effectiveness. Aim for at least 1,000 rows per segment in each chunk. - Leveraging data similarity—adjacent rows with similar values or trends compress better. Use
compress_orderbyto organize data effectively.
Conclusion
If you’re struggling with the size of your PostgreSQL database, Timescale—with its effective columnar compression engine—is the right tool for you.
We have the numbers to back it up: Timescale’s individual chunk (partition) compression in a hybrid row-columnar format and clever use of different compression algorithms consistently surpassed the compression powers of TOAST in our comparison, further cementing our theory: while effective in storing large data values in PostgreSQL, TOAST seems unable to respond to the compression demands of modern applications.
Now that you’ve seen the figures and learned more about how Timescale’s compression works and how to enable it, go test it out! You can create a Timescale account for free and start experimenting with compressing your PostgreSQL databases today.



