

Storing IoT Data: 8 Reasons Why You Should Use PostgreSQL

It’s no secret that the so-called “Internet of Things” isn’t about the Things but the data. And it is a lot of sensor data. Every day, more of the physical world— manufacturing operations, food production systems, trains we commute on — is connected to the Internet and automated, creating more and more streams of sensor data.
Multiply the millions of things by the amount of data per device, and you get an exponentially growing torrent of information being used to make better business decisions, provide better end-user experiences, and produce more while wasting less.
Most engineering teams (including ours, early on in our company history) working on these initiatives end up storing all of this data in multiple databases: metadata in a relational database and time-series data in a NoSQL store. Yet each of these databases operates differently; running a polyglot database architecture adds unnecessary operational and application complexity.
You don’t need to do this.
In this post, we’ll show you how to keep all of your IoT relational and time-series data together in PostgreSQL (yes, even at scale) and how that leads to simpler operations, more useful contextualized data, and greater ease of use. We’ll also highlight other awesome PostgreSQL features relevant to IoT, like query power, flexible data types, geospatial support, and a rich ecosystem.
By the end, if you’re convinced that PostgreSQL + Timescale (our PostgreSQL but faster alternative) is the ideal database for your IoT project, you can find out more about Timescale on our documentation page.
1. Scaling PostgreSQL for Sensor Data (With Timescale)
We’ll start with the most common question we hear:
“Will PostgreSQL scale to support my IoT data rates?”
Scale is the number one concern that developers have about PostgreSQL. And that’s completely valid. IoT backends need to support high data ingest rates, while writes on PostgreSQL can often slow to a crawl as your dataset grows.
But it turns out that for time-series data, if your database is architected the right way, you can scale PostgreSQL to ingest millions of rows per second, storing billions of rows, even on a single node with a modest amount of RAM.
How do we know this? Because we did it. 😎 For one of our features, we scaled PostgreSQL to >350 TB of data (and counting; it's over 500 TB currently), with over 10 billion new records per day. We flew past one trillion raw records in a single table recently.
This kind of scale was what led us to develop Timescale in the first place, a supercharged, mature PostgreSQL cloud platform for time series, events, analytics, and demanding workloads. At the core of Timescale, you'll find TimescaleDB, which achieves significant performance improvements by automatically partitioning data across time and space behind the scenes while presenting the illusion of a single, continuous table (called a “hypertable”) across all partitions to the user. Once you've got data in a hypertable, you can compress it, efficiently materialize it, and even tier it to object storage to slash costs.
We benchmarked TimescaleDB against PostgreSQL by inserting one billion rows of data and then ran a set of queries 100 times each against the respective database. The data, indexes, and queries were the same for both databases.
The only difference is that the TimescaleDB queries use the time_bucket() function for doing arbitrary interval bucketing, whereas the PostgreSQL queries use the new date_bin() function, introduced in PostgreSQL 13.
Here are the results:
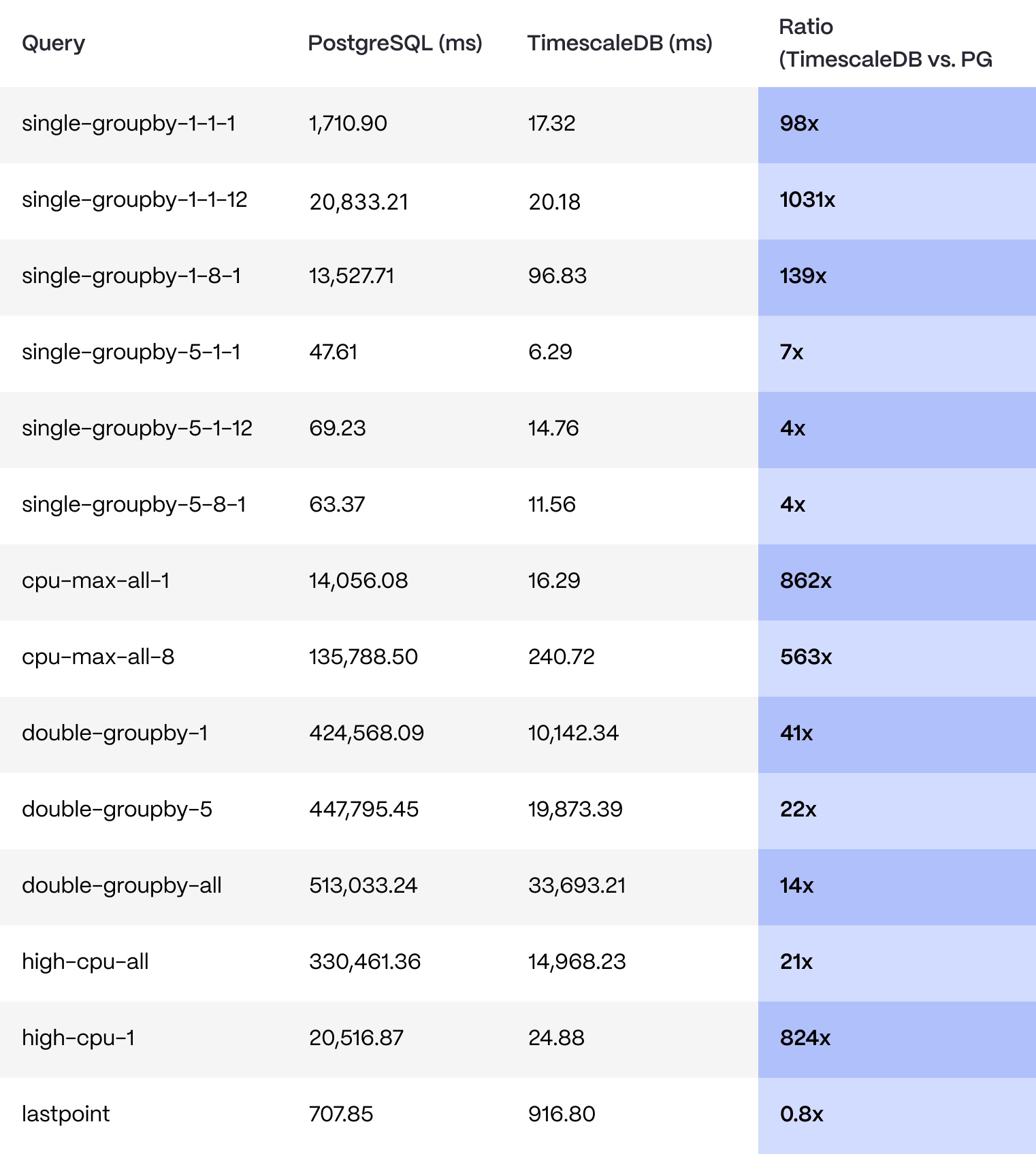
In short, for one billion rows of data spanning one month of time (with four-hour partitions), TimescaleDB consistently outperformed a vanilla PostgreSQL database running 100 queries at a time, sometimes as much as 1,031 times.
In case that wasn't enough, Timescale also used 95 % less storage for the benchmark:
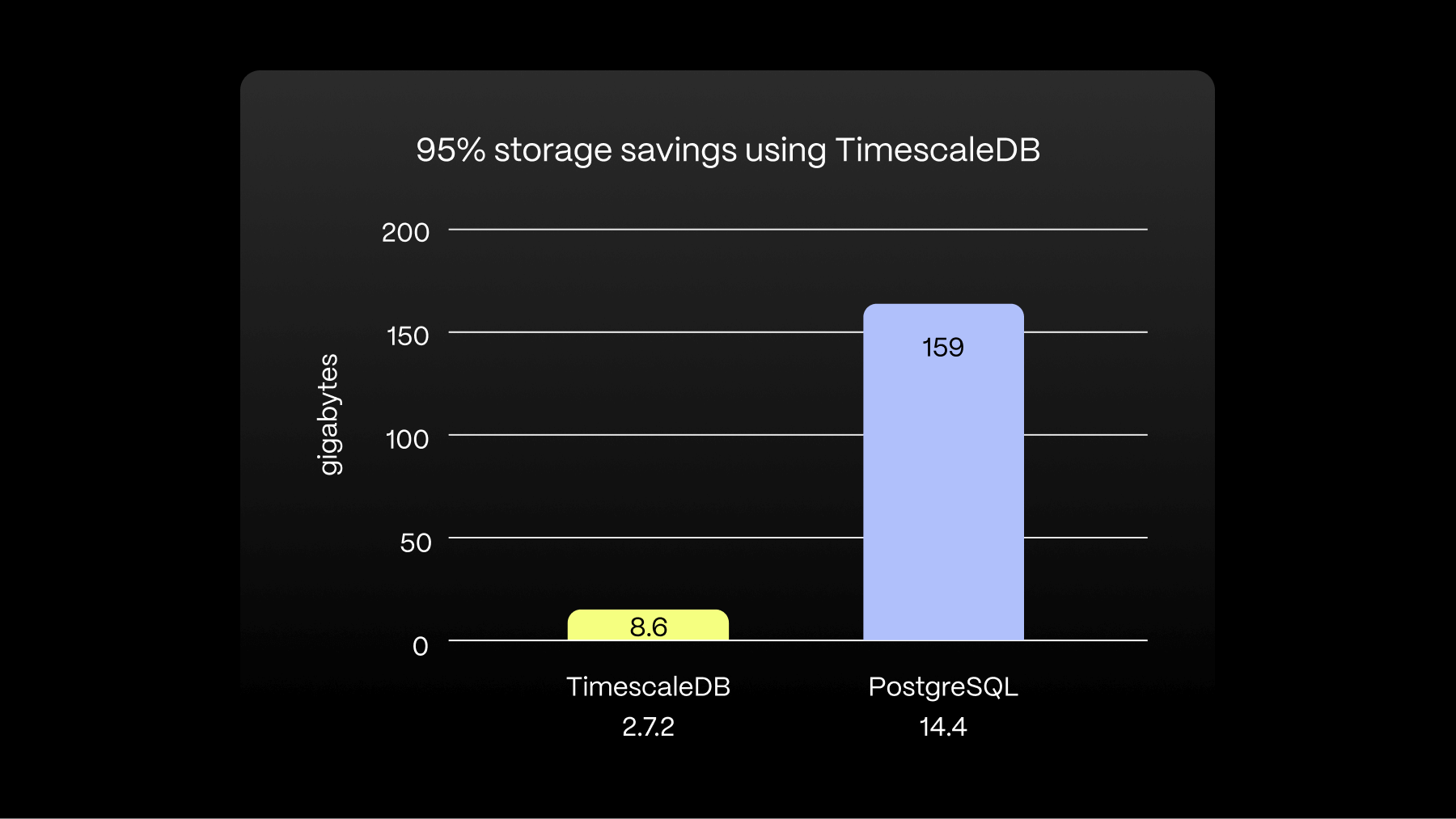
But what about data retention? Because time-series data volumes grow quickly, at some point, you may want to delete old time-series data that you no longer need. And PostgreSQL does not handle massive deletions well. This is another problem that our time/space partitioning solves: when you need to eliminate old data, instead of deleting rows (and undergoing expensive vacuuming operations), TimescaleDB just drops the partition. And, of course, this is all tucked away behind a data retention API.
If you can't afford to get rid of your data due to regulations, for example, Timescale allows you to scale PostgreSQL cheaply with Tiered Storage, our multi-tiered storage architecture. This means you can store your older, infrequently accessed data in a low-cost storage tier while still being able to access it—and without sacrificing performance for your frequently accessed data.
2. A Simplified Stack: One IoT Database vs. Two
We just saw how Timescale scales PostgreSQL for large workloads, including IoT. Now, let’s see what it lets us do.
Being able to store time-series data alongside relational data is incredibly powerful. For one, it leads to a simpler stack. Instead of two databases (NoSQL for sensor data, relational for sensor metadata), with all kinds of glue code in between—not to mention the operational headaches of having two databases—you only need one database:
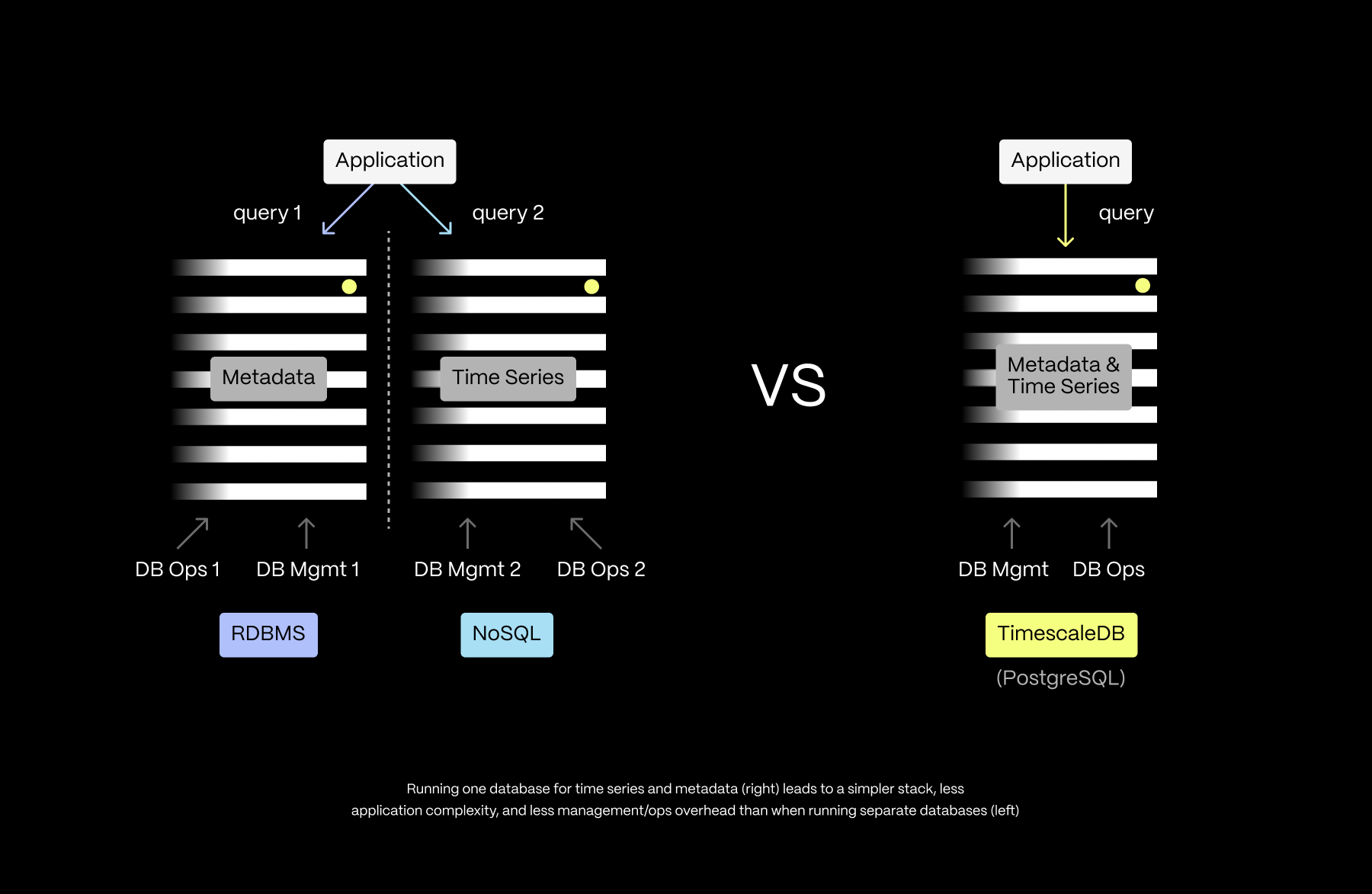
For example, let’s look at backups. Running two different databases means two different backup processes (and longer downtimes). Also, if the systems are backed up independently, then you run the risk of data integrity issues.
Imagine this scenario: your time-series data has a backup from the last hour, but your relational data was backed up yesterday, so you now have time-series data referring to new devices whose metadata is lost (by the way, Timescale handles backups for you).
Prioritizing simplicity leads to other advantages: A simpler stack is even useful at the edge, where running one database, let alone two, is hard enough (due to resource constraints). Only needing a single database makes IoT prototyping easier. It also helps reduce the complexity of large, sprawling IoT projects.
As we recently heard from the CTO of a Unicorn IoT startup: “Aggressively consolidating our tech stack lets us sharpen our engineering team’s focus.”
3. More Context for Your IoT Data
A single database for time-series data and metadata does more than just simplify your stack: it also lets you add context to your sensor data. Because what is the point of collecting data if you don’t know what you’re measuring?
Here’s an example: one company we are working with is developing an IoT application to monitor manufacturing processes. This application involves close examination of assembly line data to catch defects and ensure a high-quality product.
Most of the assembly line data is time-series in nature: {machine_id, timestamp, measurement}. Yet that data is meaningless by itself without all the other operational metadata: the machine settings at that time, the line information, the shift information, etc. They have experimented with denormalizing their data, but that added an unreasonable amount of data bloat on each measurement.
With TimescaleDB and PostgreSQL, they can keep their metadata normalized and add the necessary context to their time-series data at query time (via a SQL JOIN). For example, via a query like this:
-- Show me the average temperature by machine, for machines of a
-- given type on a particular line, by 5 minute intervals
SELECT time_bucket('5 minutes', measurements.time) as five_min,
machine_id, avg(temperature)
FROM measurements
JOIN machines ON measurements.machine_id = machines.id
JOIN lines ON machines.line_id = lines.id
WHERE machines.type = 'extruder' AND lines.name = 'production'
AND measurements.time > now() - interval '36 hours'
GROUP BY five_min, machine_id
ORDER BY five_min, machine_id;[Show the average temperature by machine, for machines of a given type on a particular line, by 5-minute intervals.]
4. Power and Ease of Use
Let’s take a step back and keep in mind the value of an IoT project: to collect, analyze, and act on data to improve utility/efficiencies, reduce downtime/waste, and provide better products and services. In other words, you need more than a data store: you also need an easy way to wring actionable insights out of your data.
This is where SQL comes in. While it’s been quite fashionable in the past several years to denounce SQL and praise NoSQL, the truth is that SQL is quite powerful and is starting to make a comeback (which is one reason why “NoSQL” is now getting “backronymed” to “Not only SQL”).
SQL includes quite a few useful features, e.g., multiple complex WHERE predicates (backed by secondary indexes), multiple aggregations and orderings, window functions, libraries of mathematical and statistical functions, and more.
-- Plot the change in temperature for ceiling sensors
-- on linear and logarithmic scales, by 10 second intervals
SELECT ten_second,
temperature / lead(temperature) OVER data AS temperature_rise_linear,
log(temperature / lead(temperature) OVER data) AS temperature_rise_log
FROM (
SELECT time_bucket('10 seconds', time) as ten_second,
last(temperature, time) as temperature
FROM measurements JOIN sensors ON measurements.sensor_id = sensors.id
WHERE sensors.type = 'ceiling' AND measurements.time >= '2017-06-01'
GROUP BY 1
ORDER BY 1
) sub window data AS (ORDER BY ten_second asc);[Plot the change in temperature for ceiling sensors on linear and logarithmic scales by 10-second intervals.]
TimescaleDB augments SQL by adding new functions necessary for time-series analysis, e.g., as shown with time_bucket and last in the query above.
SQL has another advantage: people across your organization already know it. You won’t need to train your engineers to learn a new specialized query language (or hire new ones), and non-technical users won’t need to rely as heavily on engineering (and engineering release cycles) to answer questions about the data.
In other words, by leveraging SQL, you can democratize your data, letting more people across your organization access it.

4. Broad Data Type Support (Including JSON)
JSON in a relational database? Eat your heart out, MongoDB.
When you start building your IoT product, you may not know what data you will care about, nor have a specific data schema in mind. Later on, you may need very specific data structures (e.g., arrays).
Fortunately, PostgreSQL supports a broad spectrum of data types. It allows for semi-structured data (via JSON / JSONB support) but also a variety of other data types, including many numeric types, geometric types, arrays, range types, and date/time types.
-- Storing and querying JSON data in PostgreSQL
SELECT time, sensor_id, type, readings
FROM measurements
ORDER BY time DESC, sensor_id LIMIT 50;
time | sensor_id | type | readings
---------------+-----------+------+----------------------------------
1499789565000 | 330 | 1 | {"occupancy": 0, "lights": 1}
1499789565000 | 440 | 2 | {"temperature": 74.0, "humidity": 0.81}
1499789565000 | 441 | 2 | {"temperature": 72.0, "humidity": 0.78}
1499789560000 | 330 | 1 | {"occupancy": 1, "lights": 1}
1499789560000 | 440 | 2 | {"temperature": 73.9, "humidity": 0.81}
1499789560000 | 441 | 2 | {"temperature": 72.1, "humidity": 0.79}
1499789555000 | 330 | 1 | {"occupancy": 1, "lights": 1}
1499789555000 | 440 | 2 | {"temperature": 73.9, "humidity": 0.80}
1499789555000 | 441 | 2 | {"temperature": 72.1, "humidity": 0.78}[Some of our IoT customers store sensor data in JSONB, which allows indexing.]
6. Geospatial Support for Your IoT Data
Often, there is a geospatial component in the data from connected devices —physical things exist in a particular space, after all. In particular, geospatial information is important when things are moving. One IoT use case we often see is asset tracking, e.g., tracking vehicles for fleet management, optimizing routes, reducing spoilage, etc.
You can run many PostgreSQL extensions in Timescale. One such powerful extension is PostGIS, which adds a wealth of geospatial support (including new data types, functions, etc.) to PostgreSQL. By combining PostGIS with TimescaleDB, you can combine your geospatial and time-series data, in effect creating a scalable spatiotemporal database.

7. Plenty of Integration Opportunities
Time-series databases don’t operate in a vacuum. They need connectors, for example, to data buses like Kafka, stream processing engines like Spark, or BI tools like Tableau. Most time-series databases are relatively new, and there hasn’t been enough time for an ecosystem to develop around them. On the other hand, PostgreSQL has been around for over 30+ years, and the community has built an expansive ecosystem around it.
Fortunately, TimescaleDB works just like PostgreSQL. In fact, customers often ask, “Does Timescale work with X?” And as a quick Google search typically shows, a PostgreSQL connector for X usually already exists, which will work with TimescaleDB out of the box.

8. Proven Reliability
To be annoyingly obvious, the database you choose for IoT needs to be reliable (and not wake you up at 3 a.m.). Unlike websites or mobile apps, IoT applications are typically deployed in high-value scenarios from the beginning. If you are using a database to monitor your factory line, then that database cannot go down.
This is where we rest on the shoulders of giants. In the past 30+ years, PostgreSQL has been battle-tested in various mission-critical applications across various industries. There is also another ecosystem of administrative tools that make reliability easier to achieve: streaming replication, hot standby, and more. TimescaleDB inherits this same level of reliability and ecosystem.
Try Timescale Today
There is a lot of noise in the IoT world right now, and deciding what database to use for your IoT project can be hard. But sometimes, the best option is the boring option: the database that just works. That’s PostgreSQL, which now (thanks to Timescale) finally scales to handle IoT workloads and optimizes SQL for time-series data.

If you’re building a new IoT project or currently wrestling with a complex IoT stack, choose PostgreSQL—but faster. Create a free Timecale account.
If you need help with anything, feel free to join our Community on Slack.



