

Postgres Materialized Views, The Timescale Way
How PostgreSQL Views and Materialized Views Work and How They Influenced TimescaleDB Continuous Aggregates
Soon after I graduated from college, I was working on starting a business and moved into a house near campus with five friends. The house was a bit run down, but the rent was cheap, and the people were great.
I lived there for a couple of years, and we developed a tradition: whenever someone would move out, we would ask them to share three pieces of wisdom with the group. Some were silly, some were serious, some were profound, none seemed remotely related to PostgreSQL or materialized views at the time, but one really has stuck with me. My friend Jason, who’d just finished his Ph.D. in Applied Physics, said the wisdom he’d learned was “Don’t squander your ignorance.” He explained that once you learn something, you end up taking it for granted and it becomes so much harder to overcome your tacit knowledge and ask simple, but important, questions.
A few months ago, I started a new role managing Engineering Education here at Timescale, and as I’ve started teaching more, Jason’s advice has never been more relevant. Teaching is all about reclaiming squandered ignorance; it’s about constantly remembering what it was like to first learn something, even when you’ve been working on it for years. The things that felt like revelations when we first learned them feel normal as we continue in the field.
So it’s been common for me that things I’ve worked most closely on can be the hardest to teach. Continuous aggregates are one of the most popular features of TimescaleDB and one of the ones I’m most proud of, partially because I helped design them.
We were recently working on a revamp of continuous aggregates, and as we were discussing the changes, I realized that whenever I’ve explained continuous aggregates, I’ve done it with all of this context about PostgreSQL views and materialized views in my head.
I was lucky enough to learn this by trial and error; I had problems that forced me to learn about views and materialized views and figure out all the ways they worked and didn’t work, and I was able to bring that experience to their design when I joined Timescale, but not everyone has that luxury.
This post is an attempt to distill a few lessons about what views and materialized views in PostgreSQL are, what they’re good at, where they fall short, and how we learned from them to make continuous aggregates incredible tools for time-series data analysis. If you need a summary of the main concepts around this topic, check out our Guide on PostgreSQL views.
This post also comes out of our ongoing Foundations of PostgreSQL and TimescaleDB YouTube series, so please, those of you who are encountering this for the first time, don’t squander your ignorance! Send me questions, no matter how basic they seem—I’d really appreciate it because it will help me become a better teacher. I’ve set up a forum post where you can ask them, or, if you’d prefer, you can ask on our Community Slack!
Getting Started With Views and Materialized Views
To get an understanding of PostgreSQL views, materialized views, and TimescaleDB continuous aggregates, we’re going to want to have some data to work with to demonstrate the concepts and better understand where each of them is most useful.
I’ve used the data from our getting started tutorial so that if you’d like to, you can follow along (you may need to change some of the dates in WHEREclauses, though). Our tutorial deals with financial data, but many of the insights are very broadly applicable.
Also, I won’t go through the whole thing here, but you should know that we have a company table and a stocks_real_time hypertable, defined like so:
CREATE TABLE company (
symbol text NOT NULL,
name text NOT NULL
);
CREATE TABLE stocks_real_time (
time timestamp with time zone NOT NULL,
symbol text NOT NULL,
price double precision,
day_volume integer
);
CREATE INDEX ON stocks_real_time (symbol, time);
SELECT create_hypertable('stocks_real_time', 'time');
Once you’ve set that up, you can import data, and you should be able to follow along with the rest if you’d like.
What Are PostgreSQL Views? Why Should I Use Them?
One thing we might want to explore with this dataset is being able to get the name of our company. You’ll note that the name column only exists in the company table, which can be joined to the stocks_real_time table on the symbol column so we can query by either like so:
CREATE VIEW stocks_company AS
SELECT s.symbol, s.price, s.time, s.day_volume, c.name
FROM stocks_real_time s
INNER JOIN company c ON s.symbol = c.symbol;
Once I’ve created a view, I can refer to it in another query:
SELECT symbol, price
FROM stocks_company
WHERE time >= '2022-04-05' and time <'2022-04-06';
But what is that actually doing under the hood? As I mentioned before, the view acts as an alias for the stored query, so PostgreSQL replaces the view stocks_company with the query it was defined with and runs the full resulting query. That means the query to the stocks_company view is the same as:
SELECT symbol, price
FROM (
SELECT s.symbol, s.price, s.time, s.day_volume, c.name
FROM stocks_real_time s
INNER JOIN company c ON s.symbol = c.symbol) sc
WHERE time >= '2022-04-05' and time <'2022-04-06';
We’ve manually replaced the view with the same query that we defined it with.
How can we tell that they are the same? The EXPLAINcommand tells us how PostgreSQL executes a query, and we can use it to see if the query to the view and the query that just runs the query in a subselect produce the same output.
Note, I know that EXPLAIN plans can initially seem a little intimidating. I’ve tried to make it so you don’t need to know a whole lot about EXPLAIN plans or the like to understand this post, so if you don’t want to read them, feel free to skip over them.
And if we run both:
EXPLAIN (ANALYZE ON, BUFFERS ON)
SELECT symbol, price
FROM stocks_company
WHERE time >= '2022-04-05' and time <'2022-04-06';
--AND
EXPLAIN (ANALYZE ON, BUFFERS ON)
SELECT symbol, price
FROM (
SELECT s.symbol, s.price, s.time, s.day_volume, c.name
FROM stocks_real_time s
INNER JOIN company c ON s.symbol = c.symbol) sc
WHERE time >= '2022-04-05' and time <'2022-04-06';
We can see that they both produce the same query plan (though the timings might be slightly different, they’ll even out with repeated runs).
Hash Join (cost=3.68..16328.94 rows=219252 width=12) (actual time=0.110..274.764 rows=437761 loops=1)
Hash Cond: (s.symbol = c.symbol)
Buffers: shared hit=3667
-> Index Scan using _hyper_5_2655_chunk_stocks_real_time_time_idx on _hyper_5_2655_chunk s (cost=0.43..12488.79 rows=438503 width=12) (actual time=0.057..125.607 rows=437761 loops=1)
Index Cond: (("time" >= '2022-04-05 00:00:00+00'::timestamp with time zone) AND ("time" < '2022-04-06 00:00:00+00'::timestamp with time zone))
Buffers: shared hit=3666
-> Hash (cost=2.00..2.00 rows=100 width=4) (actual time=0.034..0.035 rows=100 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 12kB
Buffers: shared hit=1
-> Seq Scan on company c (cost=0.00..2.00 rows=100 width=4) (actual time=0.006..0.014 rows=100 loops=1)
Buffers: shared hit=1
Planning:
Buffers: shared hit=682
Planning Time: 1.807 ms
Execution Time: 290.851 ms
(15 rows)
The plan joins the company to the relevant chunk of the stocks_real_time hypertable and uses an index scan to fetch the right rows. But you don’t really need to understand exactly what’s going on here to understand that they’re doing the same thing.
Views hide complexity
The JOIN in our view is very simple, which means the aliased query is relatively simple, but you can imagine that as the views get more complex, it can be very helpful to have a much simpler way for a user to query the database, where they don’t have to write all the JOINs themselves. (You can also use special views like security barrier views to grant access to data securely, but that’s more than we can cover here!).
Unfortunately, hiding the complexity can also be a problem. For instance, you may or may not have noticed in our example that we don’t actually need the JOIN! The JOIN gets us the name column from the company table, but we’re only selecting the symbol and price columns, which come from the stocks_real_time table! If we run the query directly on the table, it can go about twice as fast by avoiding the JOIN:
Index Scan using _hyper_5_2655_chunk_stocks_real_time_time_idx on _hyper_5_2655_chunk (cost=0.43..12488.79 rows=438503 width=12) (actual time=0.021..72.770 rows=437761 loops=1)
Index Cond: (("time" >= '2022-04-05 00:00:00+00'::timestamp with time zone) AND ("time" < '2022-04-06 00:00:00+00'::timestamp with time zone))
Buffers: shared hit=3666
Planning:
Buffers: shared hit=10
Planning Time: 0.243 ms
Execution Time: 140.775 ms
If I’d written out the query, I might have seen that I didn’t need the JOIN (or never written it in the first place). Whereas the view hides that complexity. So they can make things easier, but that can lead to performance pitfalls if we’re not careful.
If we actually SELECT the name column, then we could say we’re using the view more for what it was meant for like so:
SELECT name, price, symbol
FROM stocks_company
WHERE time >= '2022-04-05' AND time <'2022-04-06';
So to sum up this section on views:
- Views are a way to store an alias for a query in the database.
- PostgreSQL will replace the view name with the query you use in the view definition.
Views can be good for reducing complexity for the user, so they don’t have to write out complex JOINs, but can also lead to performance problems if they are overused and because hiding the complexity can make it harder to identify potential performance pitfalls.
One thing you’ll notice is that views can improve the user interface, but they won’t really ever improve performance, because they don’t actually run the query, they just alias it. If you want something that runs the query, you’ll need a materialized view.
What PostgreSQL Materialized Views Are and When to Use Them
When I create a materialized view, it actually runs the query and stores the results. In essence, this means the materialized view acts as a cache for the query. Caching is a common way to improve performance in all sorts of computing systems. The question we might ask is: will it be helpful here? So let’s try it out and see how it goes.
Creating a materialized view is quite easy, I can just add the MATERIALIZED keyword to my create view command:
CREATE MATERIALIZED VIEW stocks_company_mat AS
SELECT s.symbol, s.price, s.time, s.day_volume, c.name
FROM stocks_real_time s INNER JOIN company c ON s.symbol = c.symbol;
CREATE INDEX on stocks_company_mat (symbol, time DESC);
CREATE INDEX on stocks_company_mat (time DESC);
You’ll also notice that I created some indexes on the materialized view (the same ones I have on stocks_real_time)! That’s one of the cool things about materialized views, you can create indexes on them because under the hood they’re just tables that store the results of a query (we’ll explain that more later).
Now I can run EXPLAIN ANALYZE on a slightly different query, where I’m trying to get the data for ‘AAPL’ for four days on both to understand how much this caching helps our query:
EXPLAIN (ANALYZE ON, BUFFERS ON) SELECT name, price FROM stocks_company_mat WHERE time >= '2022-04-05' AND time <'2022-04-09' AND symbol = 'AAPL';
Bitmap Heap Scan on stocks_company_mat (cost=1494.93..56510.51 rows=92196 width=17) (actual time=11.796..46.336 rows=95497 loops=1)
Recheck Cond: ((symbol = 'AAPL'::text) AND ("time" >= '2022-04-05 00:00:00+00'::timestamp with time zone) AND ("time" < '2022-04-09 00:00:00+00'::timestamp with time zone))
Heap Blocks: exact=14632
Buffers: shared hit=14969
-> Bitmap Index Scan on stocks_company_mat_symbol_time_idx (cost=0.00..1471.88 rows=92196 width=0) (actual time=9.456..9.456 rows=95497 loops=1)
Index Cond: ((symbol = 'AAPL'::text) AND ("time" >= '2022-04-05 00:00:00+00'::timestamp with time zone) AND ("time" < '2022-04-09 00:00:00+00'::timestamp with time zone))
Buffers: shared hit=337
Planning:
Buffers: shared hit=5
Planning Time: 0.102 ms
Execution Time: 49.995 ms
EXPLAIN (ANALYZE ON, BUFFERS ON) SELECT name, price FROM stocks_company WHERE time >= '2022-04-05' AND time <'2022-04-09' AND symbol = 'AAPL';
Nested Loop (cost=919.95..30791.92 rows=96944 width=19) (actual time=6.023..75.367 rows=95497 loops=1)
Buffers: shared hit=13215
-> Seq Scan on company c (cost=0.00..2.25 rows=1 width=15) (actual time=0.006..0.018 rows=1 loops=1)
Filter: (symbol = 'AAPL'::text)
Rows Removed by Filter: 99
Buffers: shared hit=1
-> Append (cost=919.95..29820.23 rows=96944 width=12) (actual time=6.013..67.491 rows=95497 loops=1)
Buffers: shared hit=13214
-> Bitmap Heap Scan on _hyper_5_2655_chunk s_1 (cost=919.95..11488.49 rows=49688 width=12) (actual time=6.013..22.334 rows=49224 loops=1)
Recheck Cond: ((symbol = 'AAPL'::text) AND ("time" >= '2022-04-05 00:00:00+00'::timestamp with time zone) AND ("time" < '2022-04-09 00:00:00+00'::timestamp with time zone))
Heap Blocks: exact=6583
Buffers: shared hit=6895
(... elided for space)
Planning:
Buffers: shared hit=30
Planning Time: 0.465 ms
Execution Time: 78.932 ms
Taking a look at these plans, we can see that it helps less than one might think! It sped it up a little, but really, they’re doing almost the same amount of work! How can I tell? Well, they scan approximately the same number of 8KB buffers (see Lesson 0 of the Foundations series to learn more about those), and they scan the same number of rows.
When materialized view performance doesn't materialize
Why is this? Well, our JOIN didn’t reduce the number of rows in the query, so the materialized view stocks_company_mat actually has the same number of rows in it as the stocks_real_time hypertable!
SELECT
(SELECT count(*) FROM stocks_company_mat) as rows_mat,
(SELECT count(*) FROM stocks_real_time) as rows_tab;
rows_mat | rows_tab
----------+----------
7375355 | 7375355
So, not a huge benefit, and we have to store the same number of rows over again. So we’re getting little benefit for a pretty large cost in terms of how much storage we have to use. Now this could have been a large benefit if we were running a very expensive function or doing a very complex JOIN in our materialized view definition, but we’re not, so this doesn’t save us much.
The thing about our example is that it only gets worse from here. One of the things we might want to do with our view or materialized view is being able to use a WHERE clause to filter not just on symbol but on the company name. (Maybe I don’t remember the stock symbol for a company, but I do remember its name.) Remember that the name column is the one we joined on, so let’s run that query on both the view and materialized view and see what happens:
EXPLAIN (ANALYZE ON, BUFFERS ON) SELECT name, price from stocks_company_mat WHERE time >= '2022-04-05' and time <'2022-04-06' AND name = 'Apple' ;
Index Scan using stocks_company_mat_time_idx on stocks_company_mat (cost=0.43..57619.99 rows=92196 width=17) (actual time=0.022..605.268 rows=95497 loops=1)
Index Cond: (("time" >= '2022-04-05 00:00:00+00'::timestamp with time zone) AND ("time" < '2022-04-09 00:00:00+00'::timestamp with time zone))
Filter: (name = 'Apple'::text)
Rows Removed by Filter: 1655717
Buffers: shared hit=112577
Planning:
Buffers: shared hit=3
Planning Time: 0.116 ms
Execution Time: 609.040 ms
EXPLAIN (ANALYZE ON, BUFFERS ON) SELECT name, price from stocks_company WHERE time >= '2022-04-05' and time <'2022-04-06' AND name = 'Apple' ;
Nested Loop (cost=325.22..21879.02 rows=8736 width=19) (actual time=5.642..56.062 rows=95497 loops=1)
Buffers: shared hit=13215
-> Seq Scan on company c (cost=0.00..2.25 rows=1 width=15) (actual time=0.007..0.018 rows=1 loops=1)
Filter: (name = 'Apple'::text)
Rows Removed by Filter: 99
Buffers: shared hit=1
-> Append (cost=325.22..21540.78 rows=33599 width=12) (actual time=5.633..48.232 rows=95497 loops=1)
Buffers: shared hit=13214
-> Bitmap Heap Scan on _hyper_5_2655_chunk s_1 (cost=325.22..9866.59 rows=17537 width=12) (actual time=5.631..21.713 rows=49224 loops=1)
Recheck Cond: ((symbol = c.symbol) AND ("time" >= '2022-04-05 00:00:00+00'::timestamp with time zone) AND ("time" < '2022-04-09 00:00:00+00'::timestamp with time zone))
Heap Blocks: exact=6583
Buffers: shared hit=6895
…
Planning:
Buffers: shared hit=30
Planning Time: 0.454 ms
Execution Time: 59.558 ms
This time, my query on the regular view is much better! It hits far fewer buffers and returns 10x faster! This is because we created an index on (symbol, time DESC) for the materialized view, but not on (name, time DESC), so it has to fall back to scanning the full timeindex and removing the rows that don’t match.
The normal view, however, can use the more selective (symbol, time DESC) on the stocks_real_time hypertable because it’s performing the JOIN to the company table, and it joins on the symbol column, which means it can still use the more selective index. We “enhanced” the materialized view by performing the JOIN and caching the results, but then we’d need to create an index on the joined column too.
So we’re learning that this query isn’t a great candidate for a materialized view, because it’s not a crazy complex time-consuming JOIN and doesn’t reduce the number of rows. But if we had a query that we wanted to run that would reduce the number of rows, then that would be a great candidate for a materialized view.
When materialized views perform well
As it turns out, there’s a very common set of queries on stock data like this that does reduce the number of rows, they’re called Open-High-Low-Close queries (OHLC), and they look something like this:
CREATE VIEW ohlc_view AS
SELECT time_bucket('15 min', time) bucket, symbol, first(price, time), max(price), min(price), last(price, time)
FROM stocks_real_time
WHERE time >= '2022-04-05' and time <'2022-04-06'
GROUP BY time_bucket('15 min', time), symbol;
CREATE MATERIALIZED VIEW ohlc_mat AS
SELECT time_bucket('15 min', time) bucket, symbol, first(price, time), max(price), min(price), last(price, time)
FROM stocks_real_time
GROUP BY time_bucket('15 min', time), symbol ;
CREATE INDEX on ohlc_mat(symbol, bucket);
CREATE INDEX ON ohlc_mat(bucket);
Here I’m aggregating a lot of rows together, so I end up storing a lot fewer in my materialized view. (The view doesn’t store any rows, it’s just an alias for the query.) I still created a few indexes to help speed lookups, but they’re much smaller as well because there are many fewer rows in the output of this query. So now, if I select from the normal view and the materialized view, I see a huge speedup!
Normal view:
EXPLAIN (ANALYZE ON, BUFFERS ON)
SELECT bucket, symbol, first, max, min, last
FROM ohlc_view
WHERE bucket >= '2022-04-05' AND bucket <'2022-04-06';
Finalize GroupAggregate (cost=39098.81..40698.81 rows=40000 width=44) (actual time=875.233..1000.171 rows=3112 loops=1)
Group Key: (time_bucket('00:15:00'::interval, _hyper_5_2655_chunk."time")), _hyper_5_2655_chunk.symbol
Buffers: shared hit=4133, temp read=2343 written=6433
-> Sort (cost=39098.81..39198.81 rows=40000 width=92) (actual time=875.212..906.810 rows=5151 loops=1)
Sort Key: (time_bucket('00:15:00'::interval, _hyper_5_2655_chunk."time")), _hyper_5_2655_chunk.symbol
Sort Method: quicksort Memory: 1561kB
Buffers: shared hit=4133, temp read=2343 written=6433
-> Gather (cost=27814.70..36041.26 rows=40000 width=92) (actual time=491.920..902.094 rows=5151 loops=1)
Workers Planned: 1
Workers Launched: 1
Buffers: shared hit=4133, temp read=2343 written=6433
-> Partial HashAggregate (cost=26814.70..31041.26 rows=40000 width=92) (actual time=526.663..730.168 rows=2576 loops=2)
Group Key: time_bucket('00:15:00'::interval, _hyper_5_2655_chunk."time"), _hyper_5_2655_chunk.symbol
Planned Partitions: 128 Batches: 129 Memory Usage: 1577kB Disk Usage: 19592kB
Buffers: shared hit=4133, temp read=2343 written=6433
Worker 0: Batches: 129 Memory Usage: 1577kB Disk Usage: 14088kB
-> Result (cost=0.43..13907.47 rows=257943 width=28) (actual time=0.026..277.314 rows=218880 loops=2)
Buffers: shared hit=4060
-> Parallel Index Scan using _hyper_5_2655_chunk_stocks_real_time_time_idx on _hyper_5_2655_chunk (cost=0.43..10683.19 rows=257943 width=20) (actual time=0.025..176.330 rows=218880 loops=2)
Index Cond: (("time" >= '2022-04-05 00:00:00+00'::timestamp with time zone) AND ("time" < '2022-04-06 00:00:00+00'::timestamp with time zone))
Buffers: shared hit=4060
Planning:
Buffers: shared hit=10
Planning Time: 0.615 ms
Execution Time: 1003.425 ms
Materialized view:
EXPLAIN (ANALYZE ON, BUFFERS ON)
SELECT bucket, symbol, first, max, min, last
FROM ohlc_mat
WHERE bucket >= '2022-04-05' AND bucket <'2022-04-06';
Index Scan using ohlc_mat_bucket_idx on ohlc_mat (cost=0.29..96.21 rows=3126 width=43) (actual time=0.009..0.396 rows=3112 loops=1)
Index Cond: ((bucket >= '2022-04-05 00:00:00+00'::timestamp with time zone) AND (bucket < '2022-04-06 00:00:00+00'::timestamp with time zone))
Buffers: shared hit=35
Planning:
Buffers: shared hit=6
Planning Time: 0.148 ms
Execution Time: 0.545 ms
Well, that helped! We hit far fewer buffers and scanned far fewer rows with the materialized case, and we didn’t need to perform the GROUP BY and aggregate, which removes a sort, etc. All of that means that we sped up our query dramatically! But, it’s not rainbows and butterflies for materialized views. Because we didn’t cover one of their big problems, they get out of date!
So, if you think about a table like our stocks table, it’s a typical time-series use case which means it looks something like this:

We have a materialized view that we created, and it has been populated at a certain time with our query.

But then, as time passes, and we’re, say, 15 minutes later, and we’ve inserted more data, the view is out of date! We’re time_bucketing by 15-minute increments, so there’s a whole set of buckets that we don’t have!
Essentially, materialized views are only as accurate as the last time they ran the query they are caching. You need to run REFRESH MATERIALIZED VIEW to ensure they are up to date.
Once you run REFRESH MATERIALIZED VIEW, we’ll end up with the new data in our materialized view, like so:

The thing is, REFRESHing a view can be expensive, and to understand why we should understand a bit more about how they work and why they get out of date. And that can be expensive.
How Materialized Views Work (and Why They Get Out of Date)
To understand how materialized views get out of date and what refresh is doing, it helps to understand a little about how they work under the hood. Essentially, when you create a materialized view, you are creating a table and populating it with the data from the query. For the ohlc_mat view we’ve been working with, it’s equivalent to:
CREATE TABLE ohlc_tab AS
SELECT time_bucket('15 min', time) bucket, symbol, first(price, time), max(price), min(price), last(price, time)
FROM stocks_real_time
GROUP BY time_bucket('15 min', time), symbol;
Now, what happens when I insert data into the underlying table?
So, our materialized view ohlc_mat is storing the results of the query run when we created it.
INSERT INTO stocks_real_time VALUES (now(), 'AAPL', 170.91, NULL);

The regular view (ohlc_view) will stay up to date because it’s just running the queries directly on the raw data in stocks_real_time. And if we’re only inserting data close to now(), and only querying much older data, then the materialized view will seem like it’s okay. We’ll see no change for our query from a month or two ago, but if we try to query a more recent time, we won’t have any data. If we want it up to date with more recent data, we’ll need to run:
REFRESH MATERIALIZED VIEW ohlc_mat;
When we do this, what is actually happening under the hood is that we truncate (remove all the data) from the table, and then run the query again and insert it into the table.


If we were using the ohlc_tab table from above, the equivalent operations would be something like:
TRUNCATE TABLE ohlc_tab;
INSERT INTO ohlc_tab
SELECT time_bucket('15 min', time) bucket, symbol, first(price, time), max(price), min(price), last(price, time)
FROM stocks_real_time
GROUP BY time_bucket('15 min', time), symbol;
(This works slightly differently when you run REFRESH MATERIALIZED VIEW with the CONCURRENTLY option, but fundamentally, it always runs the query over the entire data set, and getting into the details is beyond the scope of this post.)
The database, much like with a view, stores the query we ran so that when we run our REFRESH it just knows what to do, which is great, but it’s not the most efficient. Even though most of the data didn’t change, we still threw out the whole data set, and re-run the whole query.
While that might be okay when you’re working with, say OLTP data that PostgreSQL works with, and your updates/deletes are randomly spread around your data set, it starts to seem pretty inefficient when you’re working with time-series data, where the writes are mostly in the most recent period.
So, to sum up, we found a case where the materialized view really helps us because the output from the query is so much smaller than the number of rows we have to scan to calculate it. In our case, it was an aggregate. But we also noticed that, when we used a materialized view, the data gets out of date because we’re storing the output of the query, rather than rerunning it at query time as you do with a view.
In order to get the materialized view to be up to date, we learned that we need to REFRESH it, but for time-series use cases, a) you have to refresh it frequently (in our case, approximately every 15 minutes or so at least) for it to be up to date, and b) the refresh is inefficient because we have to delete and re-materialize all the data, maybe going back months, to get the new information from just the previous 15 minutes. And that’s one of the main reasons we developed continuous aggregates at Timescale.
What Are Continuous Aggregates? Why Should I Use Them?
Continuous aggregates function as incremental, automatically updated materialized views. They scan and update the results of your query in the background, ensuring that new data is incorporated and old data is adjusted based on your refresh policy. Check out an example here. Keep in mind that this does not prevent you from retrieving data typically.
During a refresh, only the data that has changed since the last refresh is updated. This eliminates the need to rerun the entire query to retrieve data that you already have. This is also known as real-time aggregation; all continuous aggregates use real-time aggregation.
Real-time aggregates
Real-time aggregates address the problem of maintaining the most current data using continuous aggregates. Here's an example: if you have a 15-minute refresh policy and the last refresh occurred five minutes ago, there's already a gap in your data. Real-time aggregation tackles this by filling this gap with the latest raw data from your table. Real-time aggregation extracts the most recent yet-to-be-materialized raw data from the source table or view and adds it to the recently retrieved raw data from your table or view. This gives you an up-to-date view of your data for real-time analytics.
How Continuous Aggregates Work and How They Were Inspired by the Best of Views and Materialized Views
We’ll build up to how exactly continuous aggregates work in this section, piece by piece.
Fundamentally, when we create a continuous aggregate, we’re doing something very similar to what happens when we create a materialized view. That’s why we use a slightly modified version of the interface for creating a materialized view:
CREATE MATERIALIZED VIEW ohlc_cont
WITH (timescaledb.continuous) AS
SELECT time_bucket('15 min', time) bucket, symbol, first(price, time), max(price), min(price), last(price, time)
FROM stocks_real_time
GROUP BY time_bucket('15 min', time), symbol;
Once we’ve done that, we end up in a very similar situation to what we have with a materialized view. We have the data that was around when created the view, but as new data gets inserted, the view will get out of date.

In order to keep a continuous aggregate up to date, we need a scheduled aggregation.
Scheduled aggregation of new data
We saw two main problems with materialized views that we wanted to address with scheduled aggregations:
- We have to manually refresh a materialized view when we want it to remain up to date.
- We don’t want to re-run the query on all the old data unnecessarily; we should only run it on the new data.
To schedule aggregations, we need to create a continuous aggregate policy:
SELECT add_continuous_aggregate_policy('ohlc_cont'::regclass, start_offset=>NULL, end_offset=>'15 mins'::interval, schedule_interval=>'5 mins'::interval);
Once we’ve scheduled a continuous aggregate policy, it will run automatically according to the schedule_interval we’ve specified. In our case, it runs every five minutes. When it runs, it looks at the data we’ve already materialized and the new inserts and looks to see if we’ve finished at least one 15-minute bucket. If we have, it will run the query on just that next 15-minute portion and materialize the results in our continuous aggregate.

This means that the continuous aggregate now automatically has data from the next 15-minute period without user intervention.
And it was much more efficient. Unlike running REFRESH MATERIALIZED VIEW, we didn’t drop all the old data and recompute the aggregate against it, we just ran the aggregate query against the next 15-minute period and added that to our materialization. And as we move forward in time, this can keep occurring as each successive 15-minute period (or whatever period we chose for the time_bucket in the continuous aggregate definition) gets filled in with new data and then materialized.
One thing to note about this is that we keep track of where we’ve materialized up to by storing what we call a watermark, represented here by the dotted line. (NB: It’s named after the high watermark caused by a flood, not the watermark on a bank check.) So before the scheduled aggregation runs, the watermark is right after all the data we’ve materialized:

That helps us locate our next bucket and ensure it’s all there before we run the aggregation. Once we have, we move the watermark:

So our watermark represents the furthest point we’ve materialized up until now.
But, you might notice that our continuous aggregates still aren’t fully up to date and wouldn’t give us the same results as a view that ran the same query. Why?
- Scheduled aggregates will have some gap between when the next bucket has all of its data and when the job runs to materialize it.
- We only materialize data once the next bucket is full by default, so we’re missing the partial bucket where inserts are happening right now. We might want to get partial results for that bucket (this is especially true when we’re using larger buckets).
To address this, we made real-time views.
Real-time views
Real-time views combine the best of materialized views and normal views to give us a more up-to-date view of our data. They’re the default for continuous aggregates, so I don’t need to change how I made my continuous aggregate at all. However, I will admit that I elided a few things in the previous picture about how continuous aggregates work under the hood.
Real-time continuous aggregates have two parts:
- A materialized hypertable, where our already computed aggregates are stored.
- And a real-time view, which queries both the materialized hypertable and the raw hypertable (in the not-yet-aggregated region) and combines the results together.

So, if you look at the view definition of the continuous aggregate, it looks like this:
CREATE VIEW ohlc_cont AS SELECT _materialized_hypertable_15.bucket,
_materialized_hypertable_15.symbol,
_materialized_hypertable_15.first,
_materialized_hypertable_15.max,
_materialized_hypertable_15.min,
_materialized_hypertable_15.last
FROM _timescaledb_internal._materialized_hypertable_15
WHERE _materialized_hypertable_15.bucket < COALESCE(_timescaledb_internal.to_timestamp(_timescaledb_internal.cagg_watermark(15)), '-infinity'::timestamp with time zone)
UNION ALL
SELECT time_bucket('00:15:00'::interval, stocks_real_time."time") AS bucket,
stocks_real_time.symbol,
first(stocks_real_time."time", stocks_real_time.price) AS first,
max(stocks_real_time.price) AS max,
min(stocks_real_time.price) AS min,
last(stocks_real_time."time", stocks_real_time.price) AS last
FROM stocks_real_time
WHERE stocks_real_time."time" >= COALESCE(_timescaledb_internal.to_timestamp(_timescaledb_internal.cagg_watermark(15)), '-infinity'::timestamp with time zone)
GROUP BY (time_bucket('00:15:00'::interval, stocks_real_time."time")), stocks_real_time.symbol;
It’s two queries put together with a UNION ALL, the first just selecting the data straight out of the materialized hypertable where our bucket is below the watermark, the second running the aggregation query where our time column is above the watermark.
So you can see how this takes advantage of the best of both materialized views and normal views to create something that is much faster than a normal view but still up to date!
It’s not going to be as performant as just querying the already materialized data (though we do have an option to allow you to do that if you want to), but for most users, the last few months or even years of data is already materialized whereas only the last few minutes or days of raw data needs to be queried, so that still creates a huge speedup!
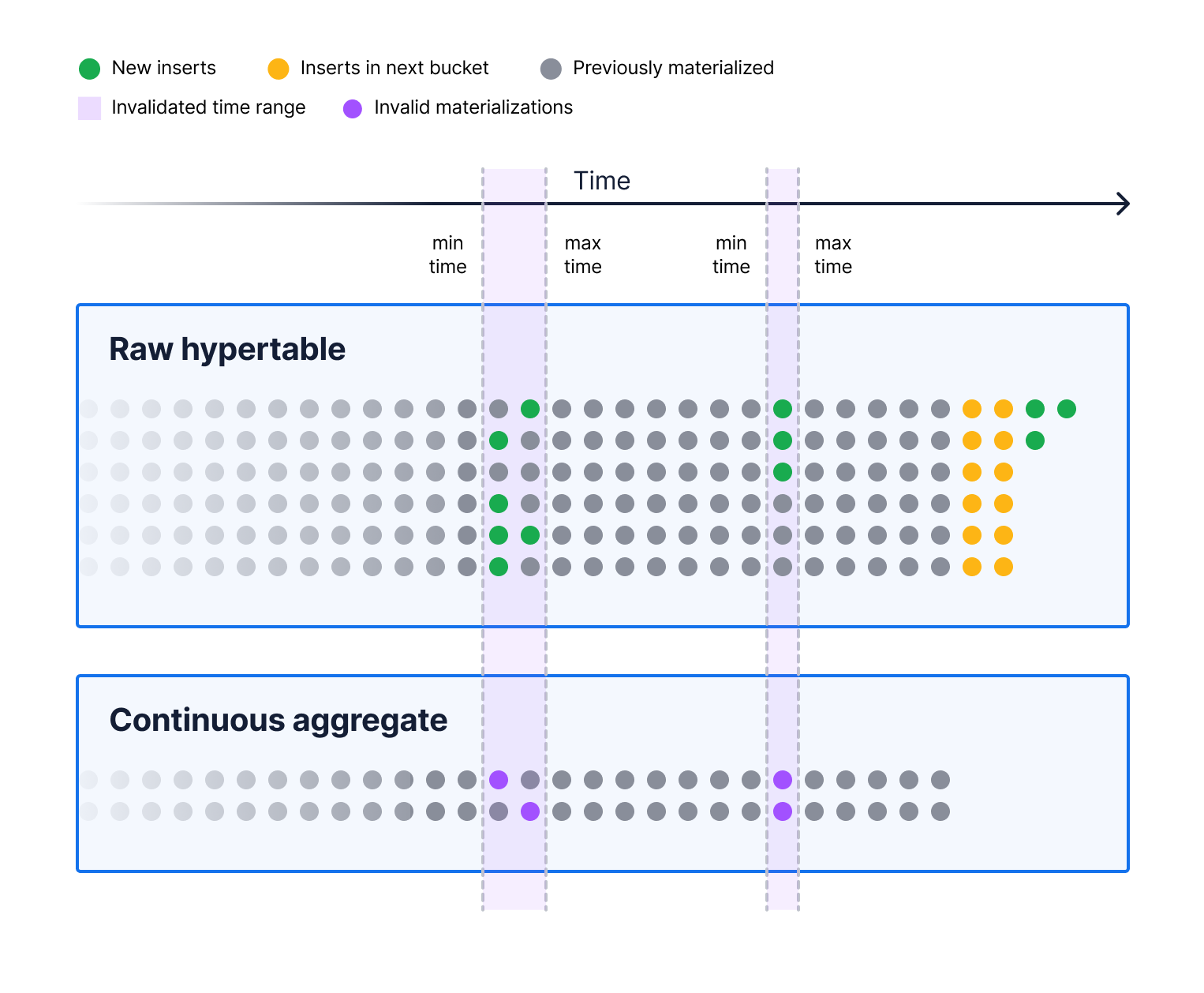
Invalidation of out-of-order data
You may have noticed that I was making a big assumption in all of my diagrams. I was assuming that all of our inserts happen in the most recent time period. For time-series workloads, this is mostly true. Most data comes in time order. But, most and all are very different things. Especially with time-series workloads, where we have so much data coming in, that even if 99 percent of the data is in time order, 1 percent of the data is still a lot!

And the results of the aggregate would be wrong by a meaningful amount if we simply let the inserts (or updates or deletes) build up over time. This cache invalidation problem is a very common problem in computing and a very hard one! PostgreSQL materialized views solve this problem by dropping all the old data and re-materializing it every time, but we already said how inefficient that was.
The other way that many folks try to solve this sort of problem in a database like PostgreSQL is a trigger. A standard trigger would run for every row and update the aggregates for every row.
But in practice, it’s hard to get a per-row trigger to work very well, and it still would cause significant write amplification, meaning, we’d have to write multiple times for every row we insert.
In fact, we’d need to write at least once for each row for each continuous aggregate we had on the raw hypertable. It would also limit the aggregates we can use to those that can be modified by a trigger, which are fewer than we might like.
So instead, we created a special kind of trigger that tracks the minimum and maximum times modified across all the rows in a statement and writes out the range of times that were modified to a log table. We call that an invalidation log.

The next time the continuous aggregate job runs, it has to do two things: it runs the normal aggregation of the next 15 minutes of data, and it runs an aggregation over each of the invalidated regions to recalculate the proper value over that period.

Note that this makes our continuous aggregates eventually consistent for out-of-order modifications. However, real-time views make continuous aggregates more strongly consistent for recent data (because they use a view under the hood).
While we could make more strongly consistent aggregates by joining to our log table and rerunning the aggregation in real time for the invalidated regions, we talked to users and decided that eventual consistency was good enough for most cases here. After all, this data is already late coming in. Essentially, we think the performance impact of doing that wasn’t worth the consistency guarantees. And anyway, if ever a user wants to, they can trigger a manual refresh of the continuous aggregate for the modified region by running the manual refresh_continuous_aggregates procedure, which updates the data in the materialized hypertable right away.
Data retention
The final thing we wanted to accomplish with our continuous aggregates was a way to keep aggregated data around after dropping the raw data. This is impossible with both PostgreSQL views and materialized views because, for views, they work directly on the raw data—if you drop it, they can’t aggregate it.
With materialized views it’s a bit more complicated: until you run a refresh, they can have the old data around, but, once you run a refresh, to get the new data that you’ve added in more recent time periods, then the old data is dropped.
With continuous aggregates, the implementation is much simpler. We mentioned the invalidation trigger that fires when we modify data that we’ve already materialized. We simply ignore any events older than a certain time horizon, including the drop event.
We also can process any invalidations before dropping data so that you can have the correct data materialized from right before you dropped the oldest stuff. You can configure data retention by setting up your continuous aggregate policy correctly.
Does It Work?
So we’ve got this whole mashup of views and materialized views and triggers in order to try to make a good set of trade-offs that works well for time-series data. So the question is: does it work?
To test that, I recreated our continuous aggregate from above without data and a policy and ran the refresh_continuous_aggregate procedure so that it would have approximately a month’s worth of data in materialized in the aggregate, with about 30 minutes that need to go through the real-time view.
If we query for the aggregated data over the whole period from the continuous aggregate, it takes about 18 ms, which is slightly slower than the 5-6 ms for the fully materialized data in a materialized view, but it’s still 1,000x faster than the 15 s it takes from a normal view, and we get most of the up-to-date benefits of a normal view from it. I'd be pretty happy with that trade-off.
If you are new to TimescaleDB and would like to try this out, I invite you to sign up for Timescale. It's the easiest way to get started with Timescale. It’s 100 percent free for 30 days, no credit card required, and you’ll be able to spin up a database in seconds.
You can easily host PostgreSQL tables and TimescaleDB hypertables in your Timescale demo database, create views, materialized views, and continuous aggregates, and explore the differences in performance and developer experience between them. We've put together some extra directions in this guide on using incremental materialized views, a.k.a. continuous aggregates—we hope it helps!



