

How We Made PostgreSQL a Better Vector Database
Introducing Timescale Vector, PostgreSQL++ for production AI applications. Timescale Vector enhances pgvector with faster search, higher recall, and more efficient time-based filtering, making PostgreSQL your new go-to vector database. Timescale Vector is available today in early access on Timescale’s cloud data platform. Keep reading to learn why and how we built it. Then take it out for a ride: try Timescale Vector for free today, with a 90-day extended trial.
The Rise of AI and Vector Embeddings
AI is eating the world. The rise of large language models (LLMs) like GPT-4, Llama 2, and Claude 2 is driving explosive growth in AI applications. Every business is urgently exploring how to use LLM’s new, game-changing capabilities to better serve their customers—either by building new applications with AI or adding AI capabilities to their existing products.
Vector data is at the heart of this Cambrian explosion of AI applications. In the field of LLMs, vector embeddings are mathematical representations of phrases that capture their semantic meaning as a vector of numerical values. Embeddings give you new superpowers for a key computing application: search.
Embeddings enable search based on semantics (i.e., finding items in your database that are closest in meaning to the query) even if the words used are very different. They differ from lexicographical search, where you search for the use of similar words. (We covered vector embeddings in more detail in a recent blog post on finding nearest neighbors.)
In addition to traditional semantic search applications, vector embeddings are crucial for making LLMs work with data the model wasn’t pre-trained on, like private information (e.g., company policies), or pre-trained on in-depth (e.g., your product documentation and capabilities), along with new information that’s emerged in the meantime (e.g., news, chat history).
They are also at the core of generative AI techniques like Retrieval Augmented Generation (RAG) to find relevant information to pass as context to an LLM. Other applications include everything from knowledge base search to classification and giving long-term memory to LLMs and AI agents.
Vector Databases and the Paradox of Choice
To power next-generation AI systems, developers need to efficiently store and query vectors. There are a myriad of vector databases in the market, with new ones popping up seemingly every week. This leaves developers facing a paradox of choice. Do they adopt new, niche databases built specifically for vector data? Or do they use familiar, general-purpose databases, like PostgreSQL, extended with vector support?
At Timescale, we have seen this dynamic before in other markets, namely time-series data. Despite the existence of niche time-series databases, like InfluxDB and AWS Timestream, millions of developers chose to use a general-purpose database in PostgreSQL with TimescaleDB, an extension for time series.
PostgreSQL's robustness, familiarity, and ecosystem outweighed switching to a completely new database. Additionally, data does not live in a silo, and the ability to join data of different modalities efficiently is often crucial for enabling interesting applications.
With vector data, developers face a similar choice. And while developer needs for LLM applications are still being molded, we think PostgreSQL will come out on top and become the foundational database for complex, production-grade AI applications, just as it has been in applications over the past decades.
Promises and Pitfalls of Specialized Vector Databases
Niche databases for vector data like Pinecone, Weaviate, Qdrant, and Zilliz benefited from the explosion of interest in AI applications. They come purpose-built for storing and querying vector data at scale—with unique features like indexes for Approximate Nearest Neighbor (ANN) search and hybrid search. But as developers started using them for their AI applications, the significant downsides of building with these databases became clear:
- Operational complexity: Continued maintenance of a separate database just for vector data adds another layer of operational overhead, requiring teams to duplicate, synchronize, and keep track of data across multiple systems. Not to mention backups, high availability, and monitoring.
- Learning curve: Engineering teams lose time learning a new query language, system internals, APIs, and optimization techniques.
- Reliability: Building a robust database from scratch is a monumental challenge. Most niche vector databases are unproven, nascent technologies with questionable long-term stability and reliability.
In the words of one developer we interviewed:
"Postgres is more production-ready, more configurable, and more transparent in its operation than almost any other vector store." - Software Engineer at LegalTech startup
PostgreSQL as a Vector Database
PostgreSQL is the most loved database in the world, according to the Stack Overflow 2023 Developer Survey. And for a good reason: it’s been battle-hardened by production use for over three decades, it’s robust and reliable, and it has a rich ecosystem of tools, drivers, and connectors.

And amidst the sea of new, niche vector databases, there is an undeniable appetite for using PostgreSQL as a vector database—look no further than the numerous tutorials, integrations, and tweets about pgvector, the open-source PostgreSQL extension for vector data.
One of the many great features of PostgreSQL is that it is designed to be extensible. These “PostgreSQL extensions” add extra functionality without slowing down or adding complexity to core development and maintenance. It’s what we leveraged for building TimescaleDB and how pgvector came about as well.
While pgvector is a wonderful extension (and is offered as part of Timescale Vector), it is just one piece of the puzzle in providing a production-grade experience for AI application developers on PostgreSQL. After speaking with numerous developers at nimble startups and established industry giants, we saw the need to enhance pgvector to cater to the performance and operational needs of developers building AI applications.
Enter Timescale Vector: PostgreSQL++ for AI Applications
Today, we launch Timescale Vector to enable you, the developer, to build production AI applications at scale with PostgreSQL.
- Timescale Vector speeds up ANN search on millions of vectors, enhancing pgvector with a state-of-the-art ANN index inspired by the DiskANN algorithm, in addition to offering pgvector’s hierarchical navigable small world (HNSW) and inverted file (IVFFlat) indexing algorithms. Our benchmarking shows that Timescale Vector achieves 243% faster search speed at 99% recall than Weaviate, a specialized vector database, and between 39.39% and 363.48% faster search speed than previously best-in-class PostgreSQL search indexes (pgvector’s HNSW and pg_embedding, respectively) on a dataset of one million OpenAI embeddings.

- Timescale Vector optimizes hybrid time-based vector search, leveraging the automatic time-based partitioning and indexing of Timescale’s hypertables to efficiently find recent embeddings, constrain vector search by a time range or document age, and store and retrieve LLM response and chat history with ease.
# Create client object
TIME_PARTITION_INTERVAL = timedelta(days=7)
vec = client.Async(TIMESCALE_SERVICE_URL,
TABLE_NAME,
EMBEDDING_DIMENSIONS,
time_partition_interval=TIME_PARTITION_INTERVAL)
# create table
await vec.create_tables()
# similarity search with time-based filtering
records_time_filtered = await vec.search(query_embedding,
limit=3,
uuid_time_filter=client.UUIDTimeRange(start_date, end_date))
- Timescale Vector simplifies the AI application stack, giving you a single place for the vector embeddings, relational data, time series, and event data that powers your next-generation AI applications. You don’t need to manage yet another piece of infrastructure, and it minimizes the operational complexity of data duplication, synchronization, and keeping track of updates across multiple systems. Because Timescale Vector is still PostgreSQL, it inherits its 30+ years of battle testing, robustness, and reliability, giving you more peace of mind about your database of choice for data that’s critical to great user experience.
- Timescale Vector simplifies handling metadata and multi-attribute filtering, so you can leverage all PostgreSQL data types to store and filter metadata, JOIN vector search results with relational data for more contextually relevant responses, and write full SQL relational queries incorporating vector embeddings. In future releases, Timescale Vector will also further optimize rich multi-attribute filtering, enabling even faster similarity searches when filtering on metadata. (We are actively seeking feedback on use cases for complex filtering, so please reach out if you have such a use case.)
In addition to unique capabilities for handling vector data at scale, Timescale Vector sits atop Timescale’s production-grade cloud PostgreSQL platform, complete with:
- Flexible and transparent pricing: Timescale decouples compute and storage, enabling you to scale resources independently as you grow. Only pay for what you use with usage-based storage pricing.
- Production PostgreSQL platform features: Push to prod with the confidence of automatic backups, failover, and high availability. Use read-replicas to scale query load. Take advantage of one-click database forking for testing new embeddings and LLMs.
- Enterprise-grade security and data privacy: Timescale is SOC2 Type II- and GDPR-compliant and keeps your data secure and private with data encryption at rest and in motion, VPC peering to your Amazon VPC, secure backups, and multi-factor authentication.
- Free support from PostgreSQL experts: Timescale runs production PostgreSQL databases for more than a thousand customers. And we offer consultative support to guide you as you grow at no extra cost.
Developers are excited
Since we opened up a waitlist for Timescale Vector, we have spoken to numerous developers at companies large and small about their AI applications and use of vector data. We want to publicly thank each and every one of them for informing our roadmap and helping shape the initial product direction.
Here’s what they had to say about Timescale Vector:
- “The simplicity and scalability of Timescale Vector's integrated approach to use Postgres as a time-series and vector database allows a startup like us to bring an AI product to market much faster. Choosing TimescaleDB was one of the best technical decisions we made, and we are excited to use Timescale Vector.” – Nicolas Bream, CEO at PolyPerception.
- “Being able to utilize conditions on vectors for similarity, alongside traditional time and value conditions simplifies our data pipelines and allows us to lean on the strengths of PostgreSQL for searching large datasets very quickly. Timescale Vector allows us to efficiently search our system for news related to assets, minimizing our reliance on tagging by our sources.” – Web Begole, CTO at MarketReader.
- “Using Timescale Vector allows us to easily combine PostgreSQL’s classic database features with storage of vector embeddings for Retrieval Augmented Generation (RAG). Timescale’s easy-to-use cloud platform and good support keep our team focused on imaging solutions to solve customer pains not on building infrastructure." - Alexis de Saint Jean, Innovation Director at Blueway Software.
- “Postgres is obviously battle-tested in a way that other vector stores aren't. Timescale Vector benefits from Timescale’s experience offering cloud PostgreSQL, and our organization is excited to use it to confidently and quickly get our LLM-based features into production.” - Software Engineer at a LegalTech company.
How to access Timescale Vector
Timescale Vector is available today in early access on Timescale, the PostgreSQL cloud platform, for new and existing customers. The easiest way to access Timescale Vector is via the Timescale Vector Python client library, which offers a simple way to integrate PostgreSQL and Timescale Vector into your AI applications.
To get started, create a new database on Timescale, download the .env file with your database credentials, and run:
pip install timescale-vector
Then, see the Timescale Vector docs for instructions or learn the key features of Timescale Vector by following this tutorial.
Try Timescale Vector for free today on Timescale.
- Three-month free trial for new customers: We’re giving new Timescale customers an extended 90-day trial. This makes it easy to test and develop your applications with Timescale Vector, as you won’t be charged for any cloud PostgreSQL databases you spin up during your trial period.
- Special early access pricing: Because we can’t wait for you to try Timescale Vector, during the early access period, Timescale Vector will be free to use for all Timescale new and existing customers. We’ll disclose our final pricing for Timescale Vector in the coming weeks. Stay tuned for details.
Why early access❓Our goal is to help developers power production AI applications, and we have a high bar for the quality of such a critical piece of infrastructure as a database. So, during this early access period, we’re inviting developers to test and give feedback on Timescale Vector so that they can shape the future of the product as we continue to improve, building up to a general availability release.

This is the first of several exciting announcements as part of Timescale AI Week. You can find something new to help you build AI applications every day at timescale.com/ai. Read on to learn more about why we built Timescale Vector, our new DiskANN-inspired index, and how it performs against alternatives.
Speeding Up Vector Search in PostgreSQL With a DiskANN-Inspired Index
As part of Timescale Vector, we are excited to introduce a new indexing technique to PostgreSQL that improves vector search speed and accuracy.
ANN search on vector data is a bustling field of research. Fresh methodologies and algorithms emerge annually. For a glimpse into this evolution, one can peruse the proceedings of NeurIPS 2022.
It is exciting to note that PostgreSQL-based vector stores, in particular, are at the forefront of this evolution. We previously discussed how to use pgvector’s IVFFlat index type to speed up search queries for ANN queries, but it has performance limitations at the scale of hundreds of thousands of vectors. Since then, teams across the PostgreSQL community are implementing more index types based on the latest research.
For instance, pgvector just released support for HNSW (a graph-based index type for vector data). Neon’s pg_embedding was also recently released with support for HNSW.
And as part of Timescale Vector, we’re announcing support for a new graph-based index, tsv drawing inspiration from Microsoft’s DiskANN. Its graph-construction approach differs from HNSW, allowing for different trade-offs and unique advantages.
You can create a timescale-vector index on the column containing your vector embeddings using our Python client as follows:
# Create a timescale vector (DiskANN) search index on the embedding column
await vec.create_embedding_index(client.TimescaleVectorIndex())
And using SQL to create the timescale-vector index looks like:
CREATE INDEX ON <table name> USING tsv(<vector_column_name>);
We'll delve deeper into why the algorithms used by this index are particularly advantageous in PostgreSQL. We are staunch proponents of offering diverse options to the PostgreSQL community, leading us to design an index distinct from those already available in the ecosystem.
Our decision to house our index in a standalone extension from pgvector was influenced by our use of Rust (for context, pgvector is written in C). Yet, we aimed to simplify its adoption by avoiding introducing a new vector data type. Hence, our index works with the vector data type provided by pgvector. This allows users to easily experiment with different index types by creating different indexes on the same table contents.
The timescale-vector DiskANN-inspired index offers several compelling benefits:
Optimized for SSDs
Much of the research on graph-based ANN algorithms focuses on graphs designed for in-memory use. In contrast, DiskANN is crafted with SSD optimization in mind. Its unique on-disk layout of graph nodes clusters each node vector with its neighboring links.
This ensures that each node's visit during a search preloads the data required for the subsequent step, aligning seamlessly with Postgres' page caching system to minimize SSD seeks. The absence of graph layers (unlike HNSW) further augments the cache's efficiency, ensuring that only the most frequently accessed nodes are retained in memory.
Quantization optimization compatible with PostgreSQL
DiskANN gives users the option to quantize vectors within the index. This process reduces the vector size, consequently shrinking the index size significantly and expediting searches.
While this might entail a marginal decline in query accuracy, PostgreSQL already stores the full-scale vectors in the heap-table. This allows for correcting the diminished accuracy from the indexed data using heap data, refining the search results. For instance, when searching for k items, the index can be prompted for 2k items, which can then be re-ranked using heap data to yield the closest k results.
In our benchmarking, we saw a 10x index size reduction by enabling product quantization, reducing the index size from 7.92 GB to just 790 MB.

To use the timescale-vector index with product quantization (PQ) enabled, you can create the index as follows:
CREATE INDEX ON <table name> USING tsv(<column name>) WITH (use_pq=true);
Filtering additional dimensions
Frequently referred to as hybrid search, this feature enables the identification of the k-nearest neighbors to a specific query vector while adhering to certain criteria on another column. For instance, vectors could be classified based on their source (such as internal documentation, external references, blog entries, and forums). A query from an external client might exclude internal documents, whereas others might limit their search to only blog entries and forums.
Timescale Vector already supports hybrid search, but the current version does not optimize the search in all cases. The exciting thing is that the DiskANN authors have outlined a blueprint for a filtered DiskANN, and we plan to add this optimization before Timescale Vector reaches GA.
Performing hybrid search using the Timescale Vector Python client can be done as follows:
records_filtered = await vec.search(query_embedding, filter={"author": "Walter Isaacson"})
In sum, the introduction of the new timescale-vector index type inspired by DiskANN benefits developers in the following ways:
- It increases the speed (both latency and throughput) of queries.
- It improves the accuracy of results.
- It decreases resource requirements.
- It supports more types of queries (in particular, queries that filter on multiple attributes, not just vectors).
Benchmarking ANN Search: Methodology and Results
Now for some numbers. Let’s look at how Timescale Vector’s approximate nearest neighbor search performance compares to a specialized vector database, in this case, Weaviate, and existing PostgreSQL search index algorithms.
What we compared
We compared the approximate nearest neighbor search performance of the following index types:
- Timescale Vector’s DiskANN-inspired index
- Weaviate’s HNSW search index
- Pgvector’s recently released HNSW index
- Neon’s pg_embedding HNSW index
- Pgvector’s IVFFlat index
Metrics tracked
We tracked a variety of metrics provided by the ANN benchmarking suite, but the ones we’ll cover in-depth are the following:
- Queries per second: how many approximate nearest neighbor search queries per second can be processed using the index.
- Accuracy: what percentage of the returned approximate nearest neighbors are actually the true nearest neighbors of the given query vector? This is also known as the recall. (Measured as a value between 0 and 1, with 1 being 100%).
- Index size: how large is the index, which we convert to a value in gigabytes (GB).
- Index build time: how much time does it take to build the index? This is measured in seconds, but we convert it to minutes in the table below for easier understanding.
Note: pgvector is packaged as part of Timescale Vector, so developers have the flexibility to choose the right index type, whether it’s DiskANN, HNSW, or IVFFlat—or opt to use exact KNN search for their use case.
Benchmarking tool
We used the popular set of tools from ANN Benchmarks to benchmark the performance of the different algorithms against each other on the same dataset. We do experiments using two modes: a parallel (--batch) mode, where multiple queries are executed at once, and a single-threaded mode, where queries are executed one at a time.
Dataset
We benchmarked the performance of the various algorithms on a dataset of one million OpenAI vector embeddings. Each vector has 1,536 dimensions and was created using OpenAI’s text-embedding-ada-002 embedding model. (Fun fact: the dataset is based on embedding content from Wikipedia articles). Shout-out to Kumar Shivendu for making that dataset easily available and adding it to ANN benchmarks.
Machine configuration
We used the following setup:
- Versions: we tested the initial version of Timescale Vector, pgvector 0.5.0 for both HNSW and IVFFlat, pg_embedding 0.3.5, and Weaviate 1.19.0-beta.1.
- Instance details: both the benchmark client and the database server ran on the same AWS EC2 virtual machines running Ubuntu 22.04.2 LTS with 8 vCPU, 32 GB Memory, and a 300 GB EBS volume. Note that this configuration is available on the Timescale cloud platform.
Algorithm parameters
We varied the following parameters over different runs to test their impact on the performance vs. accuracy trade-off. We tried to use parameters already present in ANN Benchmarks (often suggested by the index creators themselves) whenever possible.
Timescale Vector (DiskANN):
num_neighborsvaried between 50 and 64, which sets the maximum number of neighbors per node. Defaults to 50. Higher values increase accuracy but make the graph traversal slower.search_list_sizewas varied between 10 and 100: this is the S parameter used in the greedy search algorithm used during construction. Defaults to 100. Higher values improve graph quality at the cost of slower index builds.max_alphavaried between 1.0 and 1.2:max_alphais the alpha parameter. Defaults to 1.0. Higher values improve graph quality at the cost of slower index builds.query_search_list_sizevaried between 10 and 250: this is the number of additional candidates considered during the graph search at query time. Defaults to 100. Higher values improve query accuracy while making the query slower.- We also compared Timescale Vector’s index performance with and without product quantization enabled. When PQ was enabled, we set
num_clustersto 256.num_clusterssets the number of clusters (and centroids) used for every segment’s quantizer. Higher values improve accuracy at the cost of slower index builds and queries.
If you want to dive deeper into the timescale vector indexing algorithm, its parameters, and how it works, we discuss it in more depth in the “Under the Hood” section.
pgvector HNSW:
mvaried between 12 and 36:mrepresents the maximum number of connections per layer. Think of these connections as edges created for each node during graph construction. Increasingmincreases accuracy but also increases index build time and size.ef_constructionvaried between 40 and 128:ef_constructionrepresents the size of the dynamic candidate list for constructing the graph. It influences the trade-off between index quality and construction speed. Increasingef_constructionenables more accurate search results at the expense of lengthier index build times.ef_searchvaried between 10 and 600:ef_searchrepresents the size of the dynamic candidate list for search. Increasingef_searchincreases accuracy at the expense of speed.
Weaviate HNSW:
maxConnectionsvaried between 8 and 72. This parameter is explained undermin the pgvector section above.efConstructionvaried between 64 and 512. This parameter is explained byef_constructionin the pgvector section above.efvaried between 16 and 768. This parameter is explained byef_searchin the pgvector section above.
pg_embedding HNSW:
dimswas set to 1,536, the number of dimensions in our data.mvaried between 12 and 36.efconstructionvaried between 40 and 128.efsearchvaried between 10 and 600.
pgvector IVFFlat:
listsvaried from 100 to 4000:listsrepresents the number of clusters created during index building (It’s called lists because each centroid has a list of vectors in its region). Increasinglistsreduces the number of vectors in each list and results in smaller regions, but it can introduce more errors as some points are excluded.probesvaried from 1 to 100:probesrepresents the number of regions to consider during a query. Increasingprobesmeans more regions can be searched and improves accuracy at the expense of query speed.- For more on IVFFlat parameters, see this IVFFlat explainer blog post.
In general, we want to evaluate the accuracy versus speed trade-off between the various approximate nearest neighbor algorithms.
Benchmarking Results
Queries per second
Single-threaded experiment
First, let’s take a look at the results of the single-threaded mode experiment, where queries are executed one at a time.

The single-threaded experiment shows that Timescale Vector’s new index type inspired by DiskANN comes out on top in terms of query performance at 99% accuracy. It outperforms Weaviate, a specialized vector database, by 122.05%. It also outperforms all existing PostgreSQL ANN indexes, beating pgvector’s HNSW algorithm by 29.24%, pg_embedding by 257.56%, and pgvector’s IVFFLAT by 1,383.26%.
Note that if you’re willing to lower accuracy to less than 99%, say ~95%, you can get much faster query throughput. For example, at 96% accuracy, Timescale Vector’s DiskANN-inspired index can process 425 queries per second, and pgvector HNSW can process 376 queries per second.
We achieved the above results with the following parameters:
- Timescale Vector: num_neighbors=64, search_list_size=100, max_alpha=1.0 query_search_list_size=100.
- pgvector HNSW: m=36, ef_construction=128, ef_search=100.
- Weaviate: ef=48, maxConnections=40, efConstruction=256.
- pg_embedding: m=24, efconstruction=40, query_ef_search=600.
- pgvector IVFFlat: lists=2000, probes=100.
Next, let’s look at the results from the parallel (--batch) mode experiments, where multiple queries are executed at once.
Multi-threaded experiment
It is important to ensure that search algorithms scale with the number of CPUs, so let’s look at the results comparing the queries per second of the different vector search indexes when they are run in parallel:

Key Takeaways
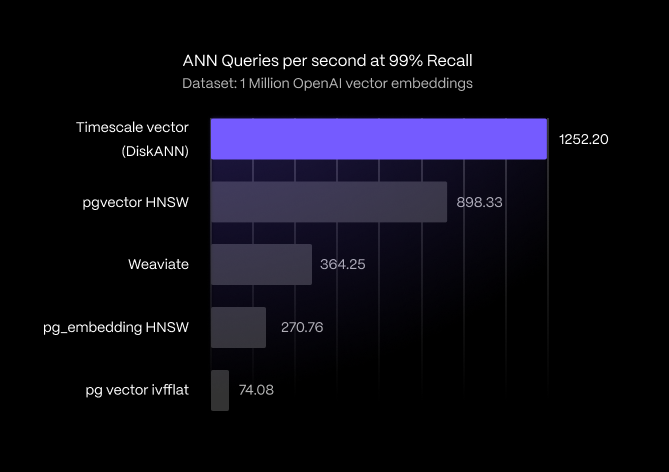
The multi-threaded experiment shows that Timescale Vector’s new index again comes out on top for queries per second at 99% accuracy:
- Timescale Vector outperforms Weaviate, a specialized vector database, by 243.77%.
- Timescale Vector also outperforms all existing PostgreSQL indexes, beating pgvector’s HNSW by 39.39%, pg_embedding’s HNSW by 362.48%, and pgvector’s IVFFlat by 1,590%.
Apart from Weaviate, we didn’t test other specialized databases, but we can get an idea of how this result extends to other specialized vector databases like Qdrant by doing a loose comparison to Qdrant benchmarks, which were also performed using ANN benchmarks on the same dataset of one million OpenAI embeddings, and used the same machine spec (8 CPU, 32 GB RAM) and experiment method (batch queries).
With 1,252.20 queries per second at 99% recall, Timescale Vector surpasses Qdrant’s 354 queries per second by more than 250%. In the future, we plan to test Timescale Vector against more specialized vector databases and benchmark the results.
While not depicted on the graph above, Timescale Vector with PQ enabled reaches 752 queries per second at 99% recall, giving it 106.61% better results than Weaviate, and 177.94% better results than pg_embedding. In terms of overall performance, it would rank 3rd in our benchmark behind Timescale Vector without PQ enabled and pgvector HNSW. These results are all the more impressive considering the index size reduction that enabling PQ yields, as discussed below.
Another interesting result is that pgvector’s HNSW implementation is 232% more performant as Neon's pg_embedding’s HNSW implementation and 146% more performant as Weaviate’s HNSW implementation when running queries in parallel. Finally, the graph-based methods (DiskANN or HNSW) all outperform the inverted file method (IVFFlat) by a wide margin.
The good news is—because Timescale Vector includes all of pgvector’s indexes (and other features)—you can create and test both Timescale Vector’s DiskANN and pgvector’s HNSW indexes on your data. Flexibility for the win!
We achieved the above results for the multi-threaded experiment with the following parameters:
- Timescale Vector: num_neighbors=50, search_list_size=100, max_alpha=1.0 query_search_list_size=100
- Timescale Vector with PQ: num_neighbors=64, search_list_size=100, max_alpha=1.0, num_clusters=256 query_search_list_size=100
- pgvector HNSW: m=36, ef_construction=128, ef_search=100
- Weaviate: ef=64, maxConnections=32, efConstruction=256
- pg_embedding: m=24, efconstruction=56, query_ef_search=250
- pgvector IVFFlat: lists=2000, probes=100
Index size
Let’s look at the index size for the respective runs that yielded the best performance in the multi-threaded experiment:

Timescale Vector without PQ comes in at 7.9 GB, as does pgvector HNSW, pg_embedding HNSW and pg_vector IVFFlat. However, by enabling PQ, Timescale Vector decreases its space usage for the index by 10x, leading to an index size of just 790 MB.
Note that we uncovered a bug in ANN Benchmarks which incorrectly reported the Weaviate index size in a previous version of this post. ANN Benchmarks reports the index size as psutil.Process().memory_info().rss / 1024 by default and that setting is not overridden for Weaviate. We've not reflected Weaviate on the graph above for that reason.
Index build time
Now, we compare the build times for the above results:

pgvector’s IVFFlat index comes out on top for index build time thanks to its simpler construction. Looking at the most performant indexes in terms of query performance, Timescale Vector is 75.41% faster to build than pgvector’s HNSW in this case. And Timescale Vector with PQ is 59.91% faster to build than pgvector HNSW.
Many developers we’ve spoken to are willing to trade off index build time with higher query speed, as it's an upfront time cost (since the index is only built once) rather than a recurring time cost and could potentially affect their users’ experience. Moreover, the Timescale Vector team is working on decreasing the index build time by using parallelism in upcoming releases.
If you’re looking for a fun weekend project, we encourage you to replicate these with these parameters to verify the results for yourself using the ANN benchmarks suite.
Under the Hood: How Timescale Vector’s New Index Works

Graph-based indexes usually work like this: each vector in a database becomes a vertex in a graph, which is linked to other vertices. When a query arises, the graph is greedily traversed from a starting point, leading us to the nearest neighboring node to the queried vector.
The example above shows that following the path with arrows from the graph entry point leads to the nearest neighbor.
Let's break down how the timescale-vector index works, focusing on the search and construction algorithms. We'll begin with the search, as it plays a pivotal role in the construction process.
Search algorithm
The objective of the greedy search is to pinpoint the nodes closest to a specific query vector. This algorithm operates in a loop until it reaches a fixed point. Within each loop iteration, the following happens:
- A vertex is "visited," meaning its distance and that of its neighboring vertices to the query vector are calculated and inserted into a list of candidates ranked by proximity.
- The nearest yet-to-be-visited candidate on this ranked list is the one that is visited.
- The loop concludes when the top 'S' candidates, in terms of proximity, have all been visited, ensuring that no neighbor of these 'S' candidates is nearer to the query than the candidates themselves.
When searching for k-nearest neighbors, you set 'S' as 'K' plus an added buffer B. The larger this buffer, the greater the number of candidates required for loop completion, rendering the search process slower but ensuring higher accuracy. At query time, you set the buffer size using the tsv.query_search_list_size GUC.
Construction algorithm
The construction phase commences with a singular starting vertex, chosen arbitrarily. The graph is built iteratively, adding one node at a time. For each added node, the following happens:
- A search is initiated for that yet-to-be-included vertex, noting the vertices visited during this search.
- These visited vertices are designated as neighbors of the newly integrated vertex.
- Connections between neighbors are established in both directions.
- As construction progresses, edges in the graph are pruned using an “alpha-aware RNG*” property that states that a neighbor of V is pruned if it is closer (by a factor alpha) to another neighbor of V than to V itself.
This is a brief overview of the mechanism of the DiskANN approach. In a future blog post, we’ll dive into the background of how graph indexes work and how the DiskANN approach differs from other algorithms in the space.
Enabling Efficient Time-based Filtering in Vector Search
A key use case that Timescale Vector uniquely enables is efficient time-based vector search. In many AI applications, time is an important metadata component for vector embeddings.
Documents, content, images, and other sources of embeddings have a time associated with them, and that time is commonly used as a filter for increasing the relevance of embeddings in an ANN search. Time-based vector search enables the retrieval of vectors that are not just similar but also pertinent to a specific time frame, enriching the quality and applicability of search results.
Time-based vector functionality is helpful for AI applications in the following ways:
- Chat history: storing and retrieving LLM response history, for example, chat history for chatbots.
- Finding recent embeddings: finding the most recent embeddings similar to a query vector. For instance, the most recent news, documents, or social media posts related to elections.
- Search within a time range: constraining similarity search to only vectors within a relevant time range. For example, asking time-based questions about a knowledge base (“What new features were added between January and March 2023?”) or conducting an image similarity search on vectors within a specified time range.
- Anomaly detection: you often want to find anomalous vectors within a specified time range.
Yet, traditionally, searching by two components’ “similarity” and “time” is challenging for approximate nearest neighbor indexes and makes the similarity-search index less effective, as similarity search alone can often return results not in the time window of interest.
One approach to solving this is partitioning the data by time and creating ANN indexes on each partition individually. Then, during the search, you can do the following:
- Step 1: filter our partitions that don’t match the time predicate.
- Step 2: perform the similarity search on all matching partitions.
- Step 3: combine all the results from each partition in step 2, rerank, and filter out results by time.
To solve this problem, Timescale Vector leverages TimescaleDB’s hypertables, which automatically partition vectors and associated metadata by a timestamp. This enables efficient querying on vectors by both similarity to a query vector and time, as partitions not in the time window of the query are ignored, making the search a lot more efficient by filtering out whole swaths of data in one go.
Hear from Web Begole, CTO at MarketReader, who aims to use Timescale Vector’s time-based search functionality to help find news stories related to stock market movements more efficiently:
“Being able to utilize conditions on vectors for similarity, alongside traditional time and value conditions, simplifies our data pipelines and allows us to lean on the strengths of PostgreSQL for searching large datasets very quickly. Timescale Vector allows us to efficiently search our system for news related to assets, minimizing our reliance on tagging by our sources.”
Here’s an example of using semantic search with time filters using the Timescale Vector Python client:
# define search query
query_string = "What's new with PostgreSQL 16?"
query_embedding = get_embeddings(query_string)
# Time filter variables for query
start_date = datetime(2023, 8, 1, 22, 10, 35) # Start date = 1 August 2023, 22:10:35
end_date = datetime(2023, 8, 30, 22, 10, 35) # End date = 30 August 2023, 22:10:35
# Similarity search with time filter
records_time_filtered = await vec.search(query_embedding,
limit=3,
uuid_time_filter=client.UUIDTimeRange(start_date, end_date))
Try Timescale Vector today
Timescale Vector is available today in early access on Timescale, the PostgreSQL++ cloud platform, for new and existing customers.
Try Timescale Vector for free today on Timescale.
- Documentation: Read the Timescale Vector docs for instructions on how to get started.
- Tutorial: Learn how to use Timescale Vector to perform semantic search, hybrid search, and time-based semantic search, and how to create indexes to speed up your queries.
And a reminder:
- Three-months free for new customers: We’re giving new Timescale customers an extended 90-day trial. This makes it easy to test and develop your applications with Timescale Vector, as you won’t be charged for any cloud PostgreSQL databases you spin up during your trial period.
- Special early access pricing: Because we can’t wait for you to try Timescale Vector, during the early access period, Timescale Vector will be free to use for all Timescale new and existing customers. We’ll disclose our final pricing for Timescale Vector in the coming weeks.




