How Prometheus Querying Works (and Why You Should Care)

🍿 This post is an adaptation of a talk presented by Harkishen Singh at Prometheus Day Europe 2022. Click here to watch the recording.
Have you ever wondered why a simple PromQL query (like the one below) takes more time to execute the more instances you monitor, even if the number of instances is not included in the query? And why does the performance slow down every time you run the query with an increased time range?
node_cpu_seconds{job=”prom”}
The answer has to do with one thing: how Prometheus queries data.
Getting familiar with the Prometheus query execution flow will help you understand your PromQL queries better. After reading this post, you will know more about how Prometheus stores data, its indexing strategies, and why your PromQL queries perform as they do. You will also get tips on what to look for when optimizing your query performance.
Prometheus Storage: The Data Model
Let’s start by describing the basics of the Prometheus data model. Prometheus uses a simple model based on labels, values, and timestamps—the labels collectively form a series with multiple samples. Each sample is a pair of timestamp and value. If a label name or value changes in a previously defined series, Prometheus will consider it an entirely new series.

Prometheus stores this data in its internal time-series database.
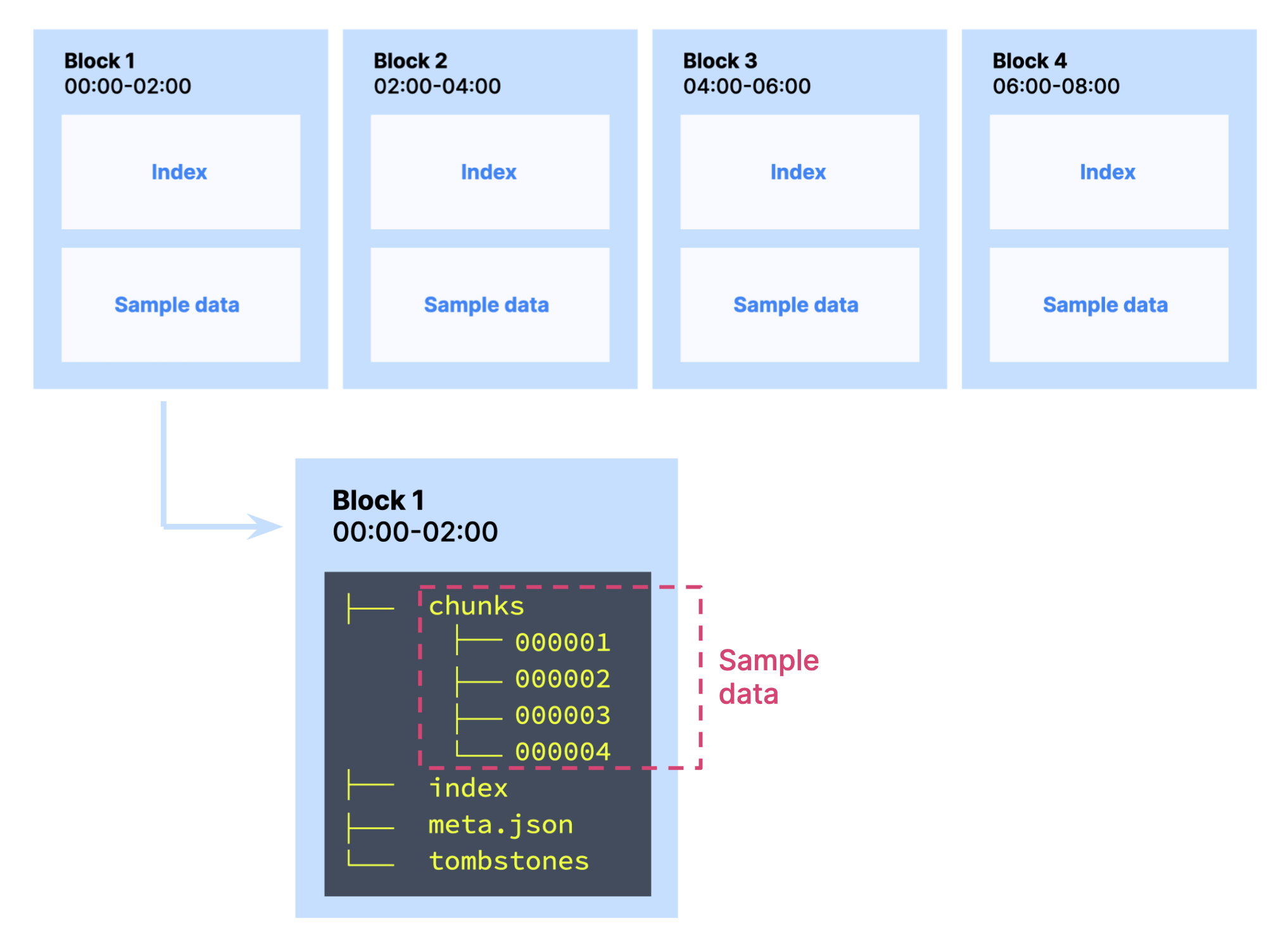
Prometheus' database is partitioned into basic units of storage called blocks that contain the data corresponding to a particular time range (for example, two hours). Blocks store two important elements:
- Sample data: the actual metric values and associated timestamps, monitored from targets.
- Indexes: the mechanism through which Prometheus can access the data.
Blocks also contain a meta.json file (with metadata about the block) and tombstones (which have deleted series alongside information about them).
Inside blocks, the sample data is stored in a secondary unit of partitioning called chunks. A chunk is a collection of samples in a time range for a particular series. A chunk will contain data from one series only.
Prometheus Storage: Indexing Strategies
Let’s now look at the index file more closely.
Inside this index file, Prometheus stores two types of indexes:
- The postings index represents the relationship between labels and the set of series that contain that label. For example, the label
__name__="up"could be contained in two series,{__name__="up",job=”prom”, instance=”:9090”}and{__name__=”up”,job=”prom”, instance=”:9090”}. - The series index indicates which chunks belong to a particular series. For example, the series
{__name__=”up”,job=”prom”,instance=”:9090”}could be stored in two chunks{chunk-1.1, chunk-1.2}. Remember that none of these chunks are shared between two series; each chunk is specific to one series only.
Prometheus Queries: Execution
So, how is the data retrieved when we run a query in Prometheus?
Prometheus query execution flow involves four basic steps:
- Identifying which blocks correspond to the query’s time range.
- Using the postings index to find the series that match the labels.
- Using the series index to identify which chunks correspond to each series.
- Retrieving the sample data from the chunks.

Let’s break it down using a query example:
up{job=”prom”, instance=”:9090”}
start=00:00, end=00:30.
Step 1: Identifying which blocks correspond to the query’s time range
PromQL queries contain labels ( __name__=”up”, job=”prom”, and instance=”:9090”) and a time range (start=00:00, end=00:30). To execute the query, Prometheus will first identify which blocks should be evaluated to satisfy the query’s time range.
Step 2: Using the postings index to find the series that match the labels
Next, each block (from step one) will be scanned to find the series that matches the labels. The postings index, located within the index file, contains this information.
In our example query, we have three labels:
__name__=”up”job=”prom”instance=”:9090”
This query will be given to the index reader, which will scan the postings index for each of the blocks identified in step one and look for a match between the query’s labels and those inside the postings table.
Suppose that three series match the first label for a particular block: series 1, series 2, series 3. For the second label, there are two series that match: series 2, series 3. And for the third label, there is only one match: series 3. Since the PromQL expression implies an AND condition, Prometheus will be looking for the series that contains the three labels: in this case, series 3.
Imagine the following for a particular block:
- For the first label:
series 1,series 2,series 3match - For the second label:
series 2,series 3match - For the third label:
series 3matches
If we see the PromQL query, it needs a series that has the first, second, and third labels. So, there is an AND condition. Hence, we take the results intersection of the three labels. We get series 3 as the output.
The process will repeat for each block identified in step one.
Step 3: Using the series index to identify which chunks correspond to each series
Prometheus now has a series set that satisfies the query’s label for each block. The next step is to identify the chunks that correspond to each series. To get that information, Prometheus looks at the series index within the index file.
Step 4. Retrieving the sample data from the chunks
After step three, Prometheus has a set of chunks that store the data we’re looking for. The data is returned, and the query is completed.

The process starts with blocks, continues with labels and series, and finishes with chunks. This means that a delay in one of the steps will have a multiplying effect on the following steps, which helps us answer the questions at the start of this blog post.
Why does the performance of a query like {job=”prom”} slow down every time we run the query with an increased time range?
Hopefully, you now understand that a query with a long time range implies that there will be more blocks to consider in evaluating a particular query. This will cause performance to slow down, as Prometheus will have to go through each one of the index files within each block, reading the postings indexes, the series indexes, and finally retrieving a set of chunks.
Something similar happens if you have high cardinality. This relates to our second question:
Why does {job=”prom”}take more time to execute the more instances you monitor, even if the number of instances is not included in the query?
We mentioned how every new value attached to a label creates a whole new series in Prometheus. When a particular label has many values attached, it directly translates to a high number of series.
Now that you know how the query execution process works, you can see how having high cardinality (i.e., a high number of series) slows things down. Under high cardinality, Prometheus’ index reader has to go through a huge postings table, retrieving a long list of series. For step three alone, Prometheus will need to look at each of the series to retrieve a set of chunks, which by now is surely long.
Long story short, having high cardinality leads to the sort of multiplicative slow-down effect we described earlier.
3 Tips to Optimize Your Prometheus Queries
Before wrapping up, we can highlight some best practices based on our lessons:
1. Avoid unnecessary label values
More label values for a particular label will lead to more cardinality, affecting the PromQL query performance. Hence, you should avoid storing ephemeral values in a label, such as storing logs as label values.
If your target exposes ephemeral labels, you can consider dropping them using the drop action in relabel_config in Prometheus scrape_config.
2. Keep your scrape interval high—you can use downsampling for this
The scrape interval is the interval in which Prometheus scrapes a metric target. If scrape intervals are low (for example, one second), it can lead to lots of chunks in the Prometheus block. Looping through chunks will be intense, and queries over a long time range can get slow.
To solve this issue, you can try to downsample your data using recording rules. Take into account, however, that recording rules will only work on data ingested after the recording rules are created.
It's a Wrap!
By understanding how Prometheus indexes work, you now have an intuitive understanding of how your PromQL queries will perform, making it easier to keep an eye on the parameters that may affect your performance.
If you're looking for a time-series database to store your Prometheus metrics, check out Timescale. You will especially love it if you're using PostgreSQL. Timescale supercharges PostgreSQL, giving it the boost it needs to handle large volumes of metrics, keeping your writes and queries fast via automatic partitioning, query planner enhancements, improved materialized views, columnar compression, and much more.
Try Timescale today: create a free account.