

Why PostgreSQL Is the Bedrock for the Future of Data

One of the biggest trends in software development today is the emergence of PostgreSQL as the de facto database standard. There have been a few blog posts on how to use PostgreSQL for Everything, but none yet on why this is happening (and more importantly, why this matters). Until now.
Updated May 8th: Wow, this post generated over 500,000 impressions! Clearly, it touched a nerve. I’ve updated the post at the end with some of the responses and feedback.
PostgreSQL Is Becoming the De Facto Database Standard
Over the past several months, “PostgreSQL for Everything” has become a growing war cry among developers:
“PostgreSQL isn’t just a simple relational database; it’s a data management framework with the potential to engulf the entire database realm. The trend of “Using Postgres for Everything” is no longer limited to a few elite teams but is becoming a mainstream best practice.” (source)
“One way to simplify your stack and reduce the moving parts, speed up development, lower the risk and deliver more features in your startup is “Use Postgres for everything.” Postgres can replace—up to millions of users—many backend technologies, Kafka, RabbitMQ, Mongo and Redis among them.” (source)
“When I first heard about Postgres (at a time when MySQL absolutely dominated), it was described to me as "that database made by those math nerds," and then it occurred to me: yeah, those are exactly the people you want making your database.” (Source)
“It has made a remarkable comeback. Now that NoSQL is dead and Oracle owns MySQL, what else is there?” (Source)
“Postgres is not just a relational DB. It's a way of life.” (Source)
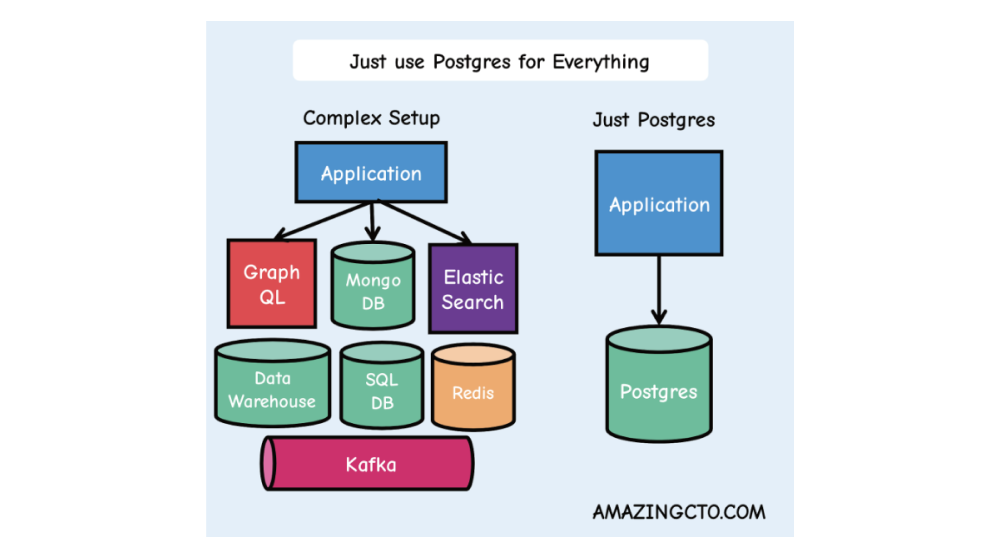
Thanks to its rock-solid foundation, plus its versatility through native features and extensions, developers can now use PostgreSQL for Everything, replacing complex, brittle data architectures with straightforward simplicity:
This might help explain why PostgreSQL last year took the top spot from MySQL in the rankings for most popular database among professional developers (60,369 respondents):
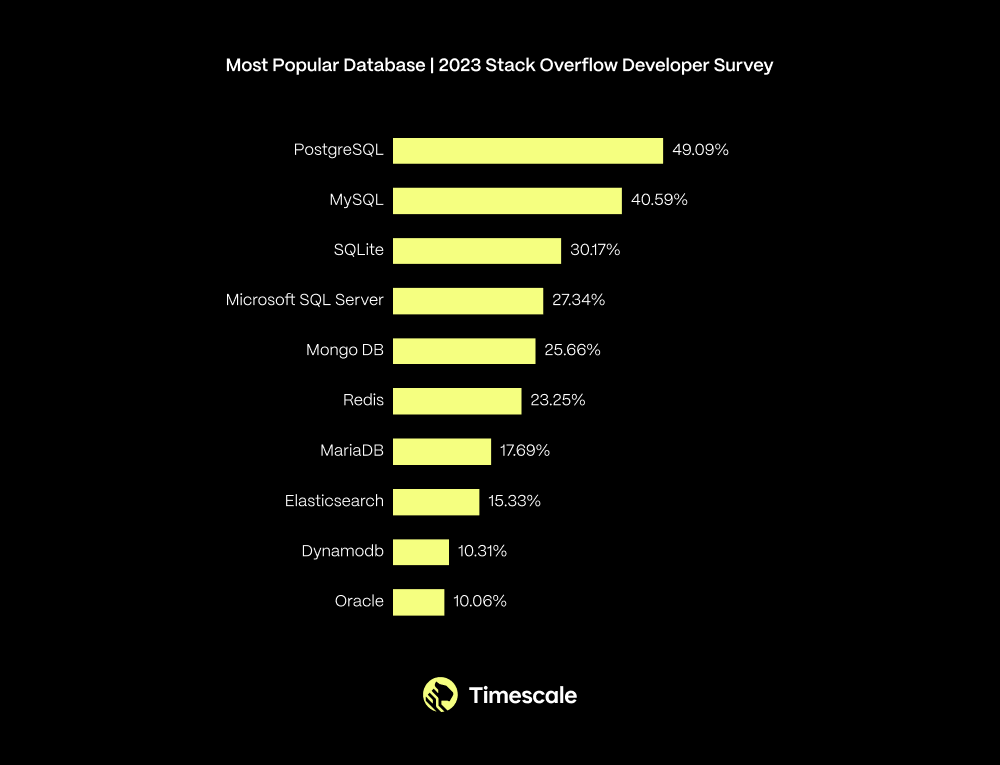
Those results are from the 2023 Stack Overflow Developer Survey. If you look across time, you can see the steady increase in PostgreSQL adoption over the past few years:
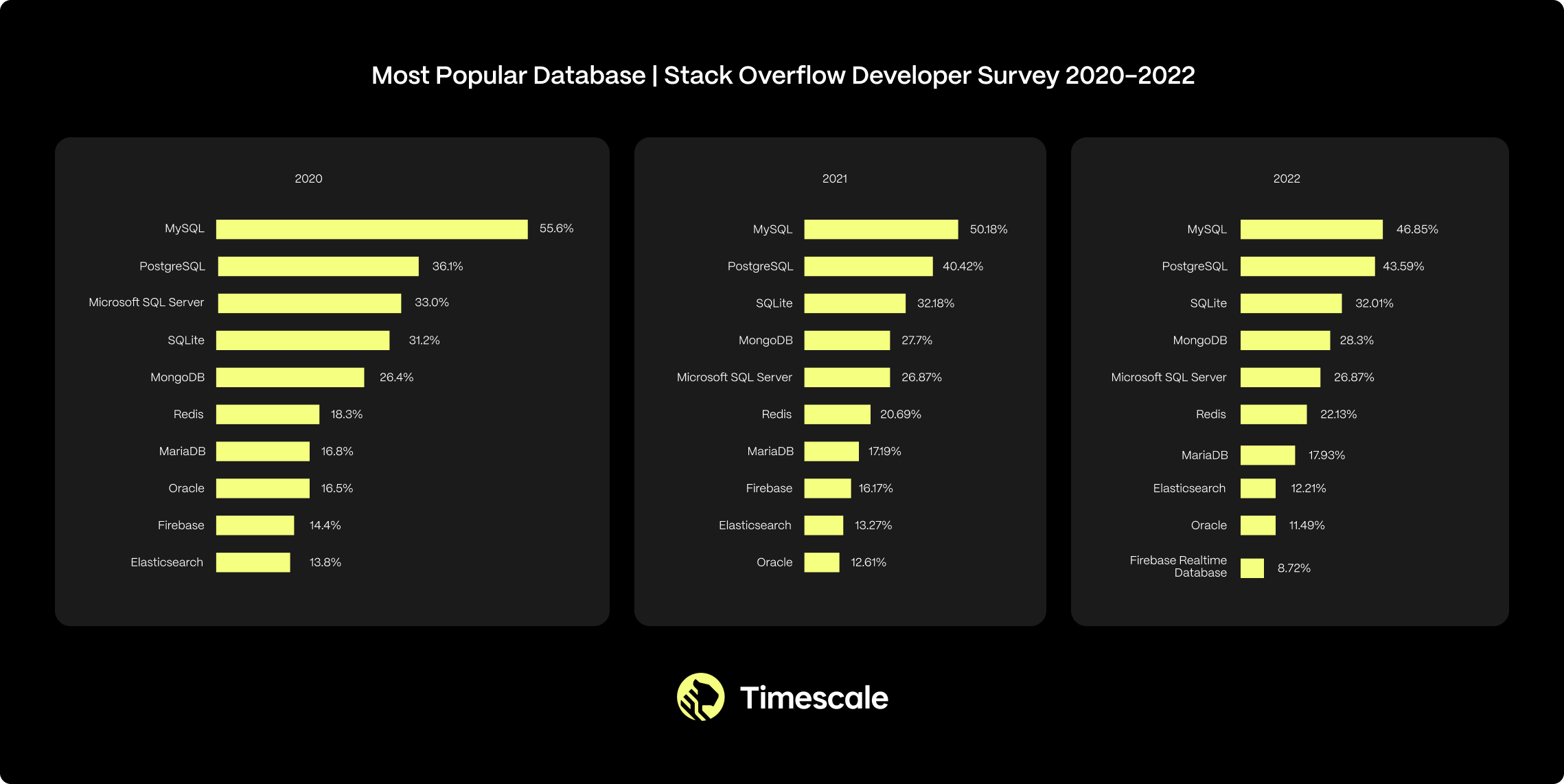
This is not just a trend among small startups and hobbyists. In fact, PostgreSQL usage is increasing across organizations of all sizes:
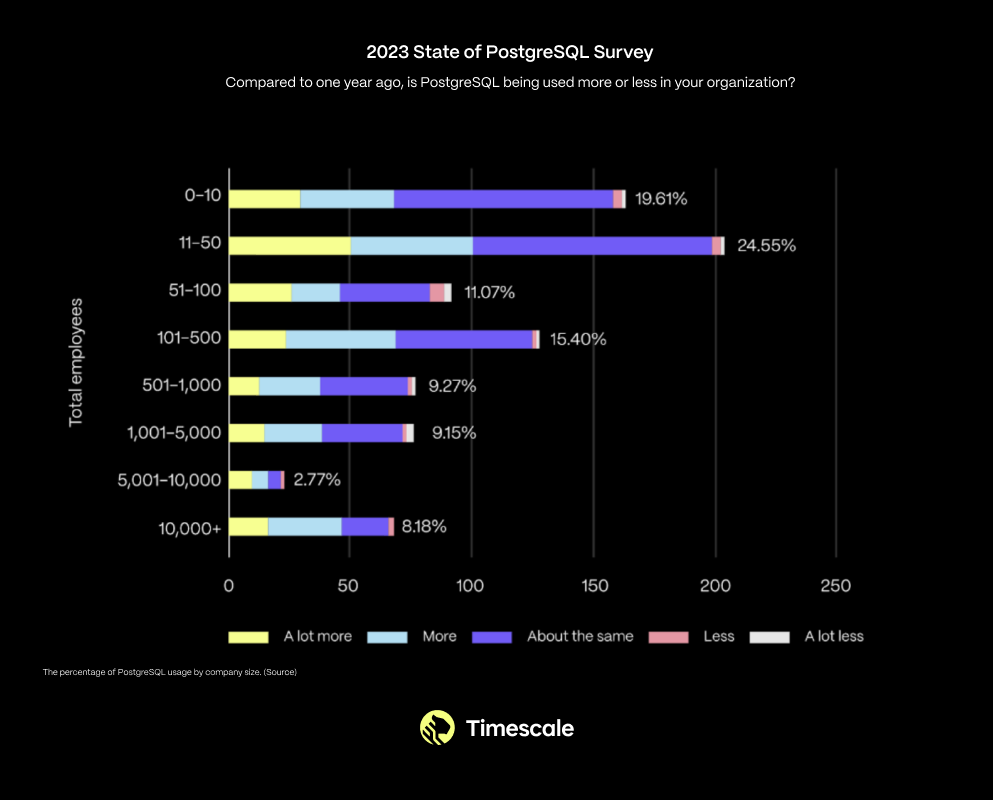
At Timescale, this trend is not new to us. We have been PostgreSQL believers for nearly a decade. That’s why we built our business on PostgreSQL, why we are one of the top contributors to PostgreSQL, why we run the annual State of PostgreSQL survey (referenced above), and why we support PostgreSQL meetups and conferences. Personally, I have been using PostgreSQL for over 13 years (when I switched over from MySQL).
There have been a few blog posts on how to use PostgreSQL for everything, but none yet on why this is happening (and, more importantly, why this matters).
Until now.
But to understand why this is happening, we have to understand an even more foundational trend and how that trend is changing the fundamental nature of human reality.
Everything Is Becoming a Computer
Everything—our cars, our homes, our cities, our farms, our factories, our currencies, our things—is becoming a computer. We, too, are becoming digital. Every year, we digitize more of our own identity and actions: how we buy things, how we entertain ourselves, how we collect art, how we find answers to our questions, how we communicate and connect with each other, how we express who we are.
Twenty-two years ago, this idea of “ubiquitous computing” seemed audacious. Back then, I was a graduate student at the MIT AI Lab, working on my thesis on Intelligent Environments. My research was supported by MIT Project Oxygen, which had a noble, bold goal: to make computing as pervasive as the air we breathe. To put that time period in perspective: we had our own server rack in a closet.
A lot has changed since then. Computing is now ubiquitous: on our desks, in our pockets, in our things, and in our “cloud.” That much we predicted.
But the second-order effects of those changes were not what most of us expected:
- Ubiquitous computing has led to ubiquitous data. With each new computing device, we collect more information about our reality: human data, machine data, business data, environmental data, and synthetic data. This data is flooding our world.
- The data flood has led to a Cambrian explosion of databases. All these new sources of data have required new places to store them. Twenty years ago, there were maybe five viable database options. Today there are several hundred, most of them specialized for specific use cases or data, with new ones emerging each month.
- More data and more databases has led to more software complexity. Choosing the right database for your software workload is no longer easy. Instead, developers are forced to cobble together complex architectures that might include: a relational database (for its reliability), a non-relational database (for its scalability), a data warehouse (for its ability to serve analysis), an object store (for its ability to cheaply archive old data). This architecture might even have more specialized components, like a time-series or vector database.
- More complexity means less time to build. Complex architectures are more brittle, require more complex application logic, offer less time for development, and slow down development. Complexity is not a benefit but a real cost.
As computing has become more ubiquitous, our reality has become more entwined with computing. We have brought computing into our world and ourselves into its world. We are no longer just our offline identities but a hybrid of what we do offline and online.
Software developers are humanity’s vanguard in this new reality. We are the ones building the software that shapes this new reality.
But developers are now flooded with data and drowning in database complexity.
This means that developers—instead of shaping the future—are spending more and more of their time managing the plumbing.
How did we get here?
Part 1: Cascading computing waves
Ubiquitous computing has led to ubiquitous data. This did not happen overnight but in cascading waves over several decades:
- Mainframes (1950s+)
- Personal Computers (1970s+)
- Internet (1990s+)
- Mobile (2000s+)
- Cloud Computing (2000s+)
- Internet of Things (2010s+)
With each wave, computers have become smaller, more powerful, and more ubiquitous. Each wave also built on the previous one: personal computers are smaller mainframes; the Internet is a network of connected computers; smartphones are even smaller computers connected to the Internet; cloud computing democratized access to computing resources; the Internet of Things is smartphone components reconstructed as part of other physical things connected to the Cloud.
But in the past two decades, computing advances have not just occurred in the physical world but also in the digital one, reflecting our hybrid reality:
- Social networks (2000+)
- Blockchains (2010s+)
- Generative AI (2020s+)
With each new wave of computing, we get new sources of information about our hybrid reality: human digital exhaust, machine data, business data, and synthetic data. Future waves will create even more data. All this data fuels new waves, the latest of which is Generative AI, which in turn further shapes our reality.
Computing waves are not siloed but cascade like dominoes. What started as a data trickle soon became a data flood. And then the data flood has led to the creation of more and more databases.
Part 2: Incremental database growth
All these new sources of data have required new places to store them—or databases.
Mainframes started with the Integrated Data Store (1964) and later System R (1974), the first SQL database. Personal computers fostered the rise of the first commercial databases: Oracle (1977), inspired by System R; DB2 (1983); and SQL Server (1989), Microsoft’s response to Oracle.
The collaborative power of the Internet enabled the rise of open-source software, including the first open-source databases: MySQL (1995), PostgreSQL (1996). Smartphones led to the proliferation of SQLite (initially created in 2000).
The Internet also created a massive amount of data, which led to the first non-relational, or NoSQL, databases: Hadoop (2006); Cassandra (2008); MongoDB (2009). Some called this the era of “Big Data.”
Part 3: Explosive database growth
Around 2010, we started to hit a breaking point. Up until that point, software applications would primarily rely on a single database—e.g., Oracle, MySQL, PostgreSQL—and the choice was relatively easy.
But “Big Data” kept getting bigger: the Internet of Things led to the rise of machine data; smartphone usage started growing exponentially thanks to the iPhone and Android, leading to even more human digital exhaust; cloud computing democratized access to compute and storage, amplifying these trends. Generative AI very recently made this problem worse with the creation of vector data.
As the volume of data collected grew, we saw the rise of specialized databases: Neo4j for graph data (2007), Redis for a basic key-value store (2009), InfluxDB for time-series data (2013), ClickHouse for high-scale analytics (2016), Pinecone for vector data (2019), and many, many more.
Twenty years ago, there were maybe five viable database options. Today, there are several hundred, most of them specialized for specific use cases, with new ones emerging each month. While the earlier databases promise general versatility, these specialized ones offer specific trade-offs, which may or may not make sense depending on your use case.
Part 4: More databases, more problems
Faced with this flood and with specialized databases with a variety of trade-offs, developers had no choice but to cobble together complex architectures.
These architectures typically include a relational database (for reliability), a non-relational database (for scalability), a data warehouse (for data analysis), an object store (for cheap archiving), and even more specialized components like a time-series or vector database for those use cases.
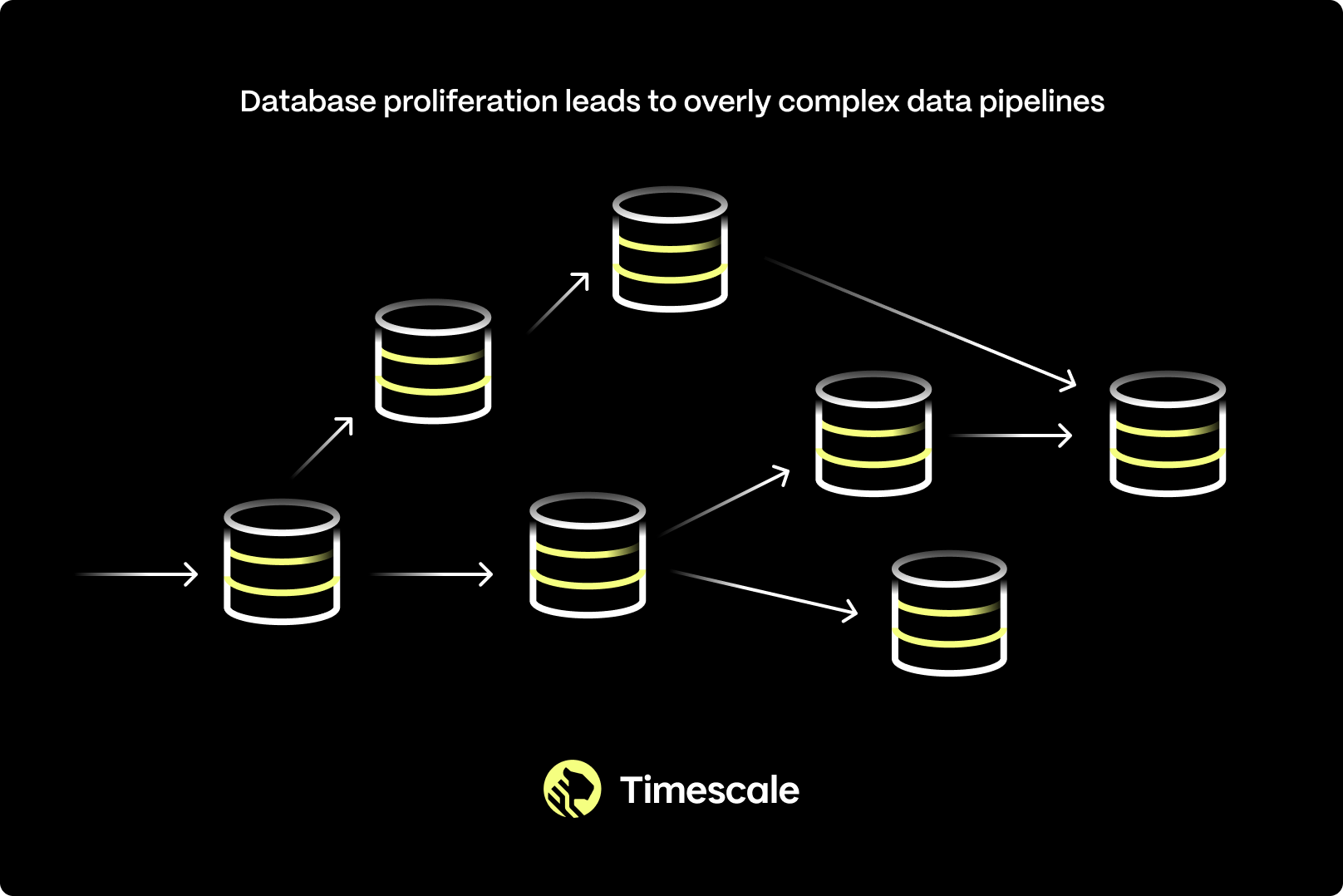
But more complexity means less time to build. Complex architectures are more brittle, require more complex application logic, offer less time for development, and slow down development.
This means that instead of building the future, software developers find themselves spending far too much time maintaining the plumbing. This is where we are today.
There is a better way.
The Return of PostgreSQL
This is where our story takes a twist. Our hero, instead of being a shiny new database, is an old stalwart, with a name only a mother core developer could love: PostgreSQL.
At first, PostgreSQL was a distant number two behind MySQL. MySQL was easier to use, had a company behind it, and a name that anyone could easily pronounce. But then MySQL was acquired by Sun Microsystems (2008), which was then acquired by Oracle (2009). And software developers, who saw MySQL as the free savior from the expensive Oracle dictatorship, started to reconsider what to use.
At that same time, a distributed community of developers, sponsored by a handful of small independent companies, was slowly making PostgreSQL better and better. They quietly added powerful features, like full-text search (2008), window functions (2009), and JSON support (2012). They also made the database more rock-solid, through capabilities like streaming replication, hot standby, in-place upgrade (2010), logical replication (2017), and by diligently fixing bugs and smoothing rough edges.
PostgreSQL is now a platform
One of the most impactful capabilities added to PostgreSQL during this time was the ability to support extensions: software modules that add functionality to PostgreSQL (2011). Extensions enabled even more developers to add functionality to PostgreSQL independently, quickly, and with minimal coordination.
Thanks to extensions, PostgreSQL started to become more than just a great relational database. Thanks to PostGIS, it became a great geospatial database; thanks to TimescaleDB, it became a great time-series database; hstore, a key-value store; AGE, a graph database; pgvector, a vector database. PostgreSQL became a platform.
Now, developers can use PostgreSQL for its reliability, scalability (replacing non-relational databases), data analysis (replacing data warehouses), and more.
What about Big Data?
At this point, the smart reader should ask, “What about big data?”. That’s a fair question. Historically, “big data” (e.g., hundreds of terabytes or even petabytes)—and the related analytics queries—has been a bad fit for a database like PostgreSQL that doesn’t scale horizontally on its own.
That, too, is changing. Last November, we launched “tiered storage,” which automatically tiers your data between disk and object storage (S3), effectively creating the ability to have an infinite table.
So while “Big Data” has historically been an area of weakness for PostgreSQL, soon, no workload will be too big.
PostgreSQL is the answer. PostgreSQL is how we free ourselves and build the future.
Free Yourself, Build the Future, Embrace PostgreSQL
Instead of futzing with several different database systems, each with its own quirks and query languages, we can rely on the world’s most versatile and, possibly, most reliable database: PostgreSQL. We can spend less time on the plumbing and more time on building the future.
And PostgreSQL keeps getting better. The PostgreSQL community continues to make the core better. There are many more companies contributing to PostgreSQL today, including the hyperscalers.
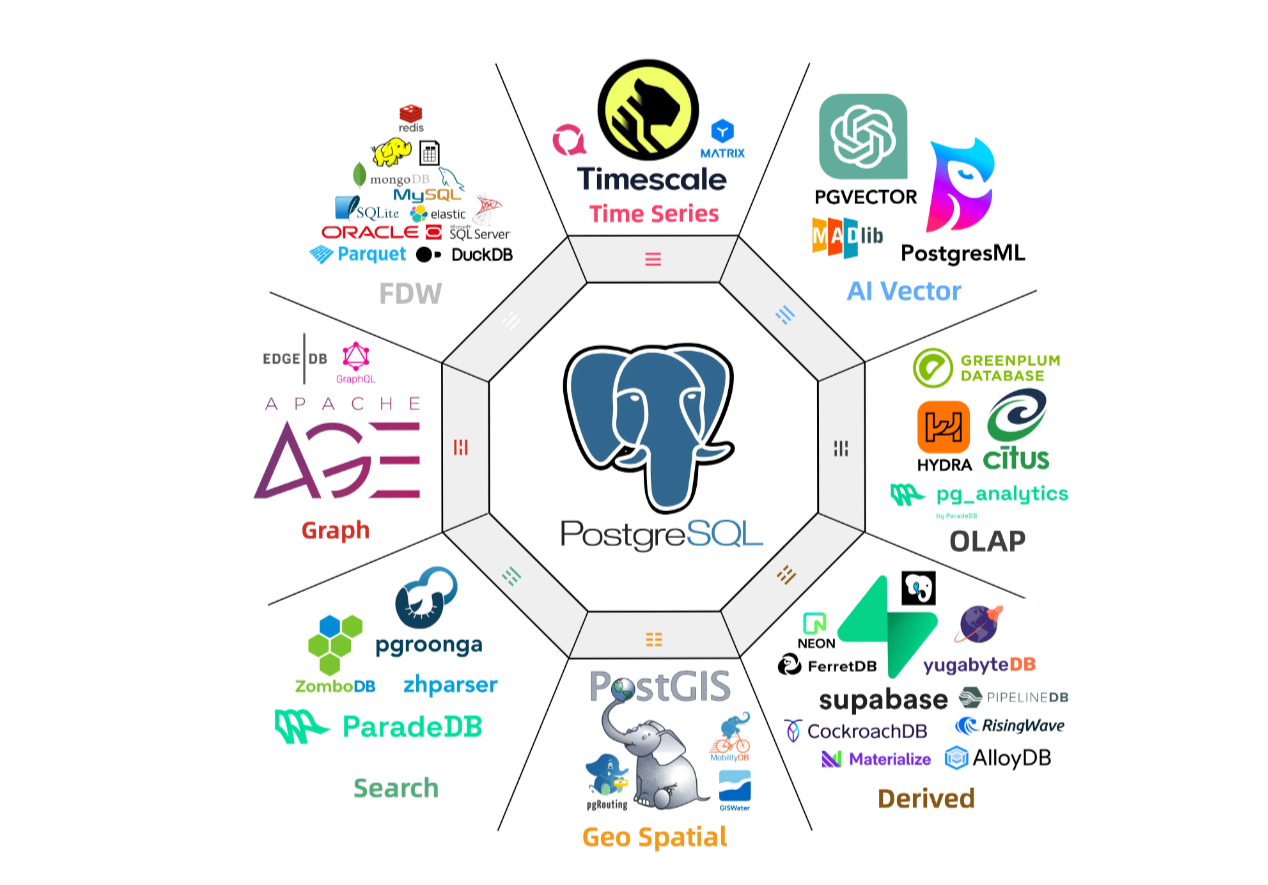
There are also more innovative, independent companies building around core to make the PostgreSQL experience better: Supabase (2020) is making PostgreSQL into a viable Firebase alternative for web and mobile developers; Neon (2021) and Xata (2022) are both making PostgreSQL scale-to-zero for intermittent serverless workloads; Tembo (2022) is providing out-of-the-box stacks for various use cases; Nile (2023) is making PostgreSQL easier for SaaS applications; and many more.
And, of course, there’s us, Timescale (2017).
Timescale Started as “PostgreSQL for Time Series”
The Timescale story will probably sound a little familiar: we were solving some hard sensor data problems for IoT customers, and we were drowning in data. To keep up, we built a complex stack that included at least two different database systems (one of which was a time-series database).
One day, we reached our breaking point. In our UI, we wanted to filter devices by both device_type and uptime. This should have been a simple SQL join. But because we were using two different databases, it instead required writing glue code in our application between our two databases. It was going to take us weeks and an entire engineering sprint to make the change.
Then, one of our engineers had a crazy idea: Why don’t we just build a time-series database right in PostgreSQL? That way, we would just have one database for all our data and would be free to ship software faster. Then we built it, and it made our lives so much easier. Then we told our friends about it, and they wanted to try it. And we realized that this was something that we needed to share with the world.
So, we open-sourced our time-series extension, TimescaleDB, and announced it to the world on April 4, 2017. Back then, PostgreSQL-based startups were quite rare. We were one of the first.
In the seven years since, we’ve heavily invested in both the extension and in our PostgreSQL cloud service, offering a better and better PostgreSQL developer experience for time-series and analytics: 350x faster queries, 44 % higher inserts via hypertables (auto-partitioning tables); millisecond response times for common queries via continuous aggregates (real-time materialized views); 90 %+ storage cost savings via native columnar compression; infinite, low-cost object storage via tiered storage; and more.
Timescale Expanded Beyond Time Series
That’s where we started, in time-series data, and also what we are most known for.
But last year we started to expand.
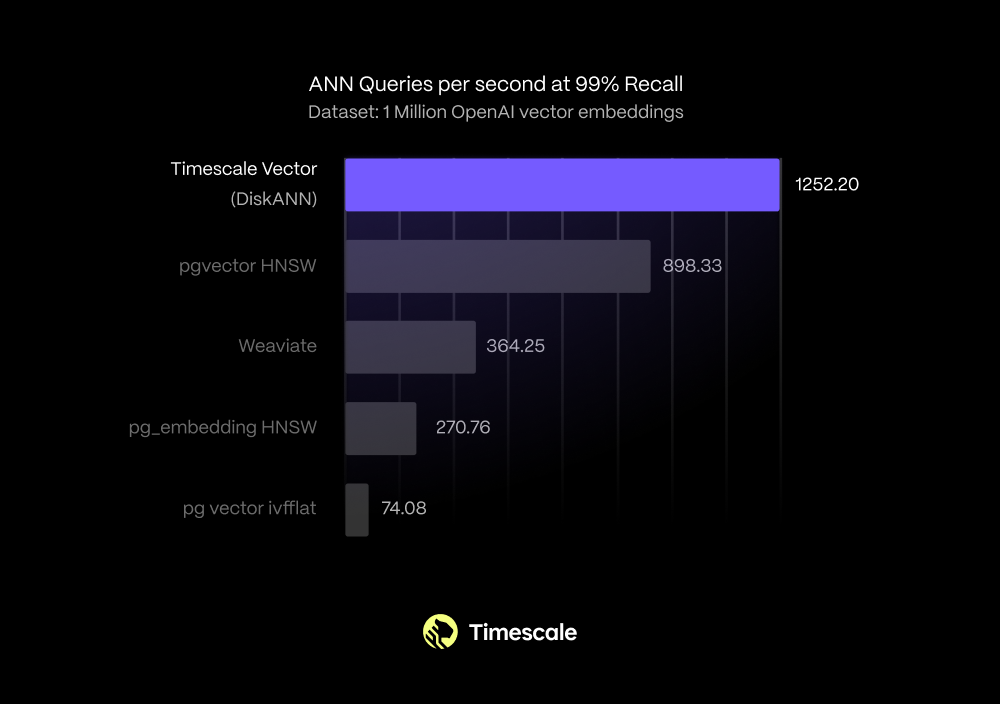
Timescale Vector
We launched Timescale Vector (“PostgreSQL++ for AI applications”), which makes PostgreSQL an even better vector database. Timescale Vector scales to over 100 million vectors, building on pgvector with even better performance. Innovative companies and teams are already using Timescale Vector in production at a massive scale, including OpenSauced, a GitHub events insights platform, at 100+ million vectors; VieRally, a social virality prediction platform, at 100+ million vectors; and MarketReader, a financial insights platform, at 30+ million vectors.
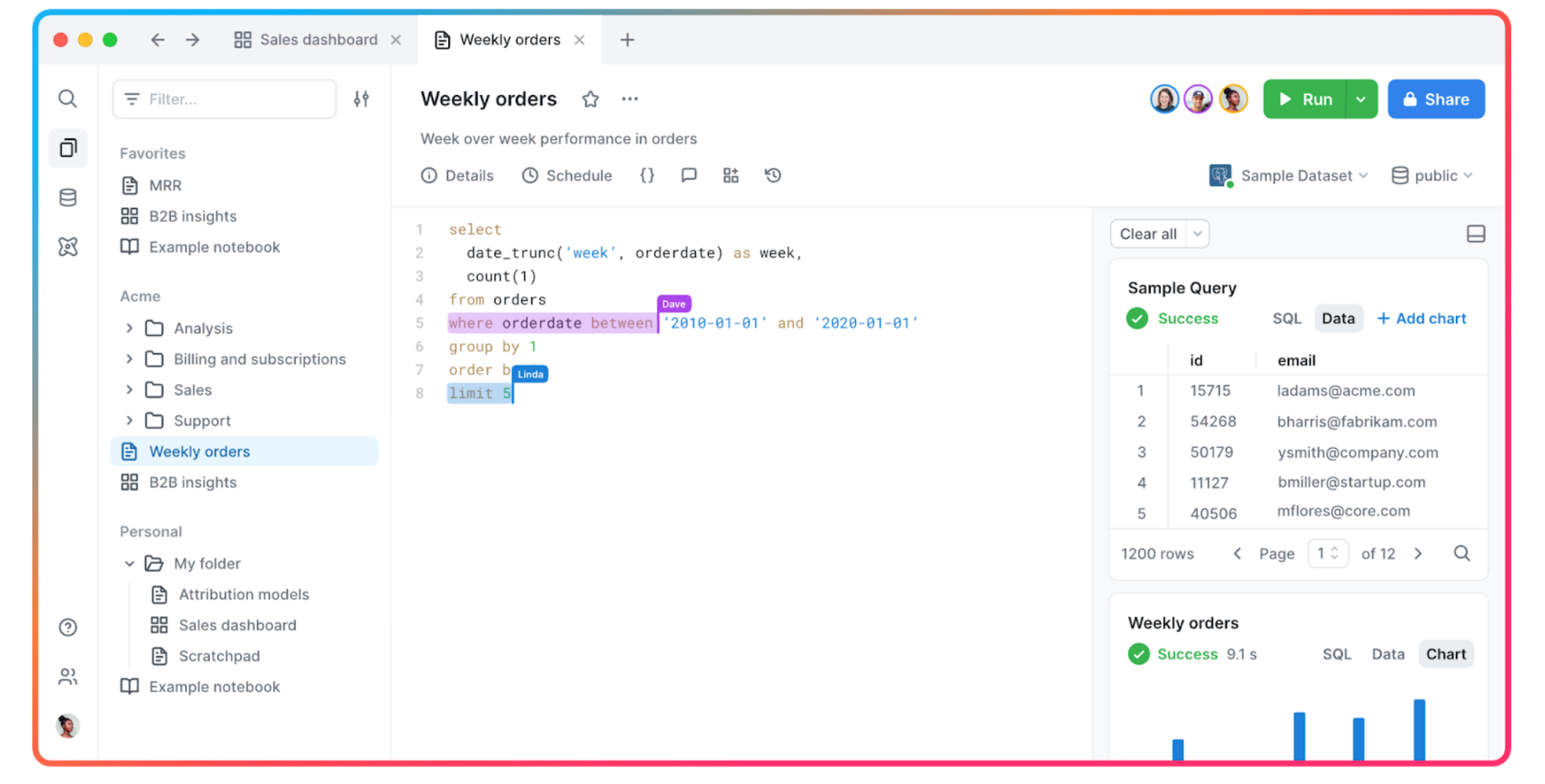
PopSQL
Recently, we also acquired PopSQL to build and offer the best PostgreSQL UI. PopSQL is the SQL editor for team collaboration, with autocomplete, schema exploration, versioning, and visualization. Hundreds of thousands of developers and data analysts have used PopSQL to work with their data, whether on PostgreSQL, Timescale, or other data sources like Redshift, Snowflake, BigQuery, MySQL, SQL Server, and more.
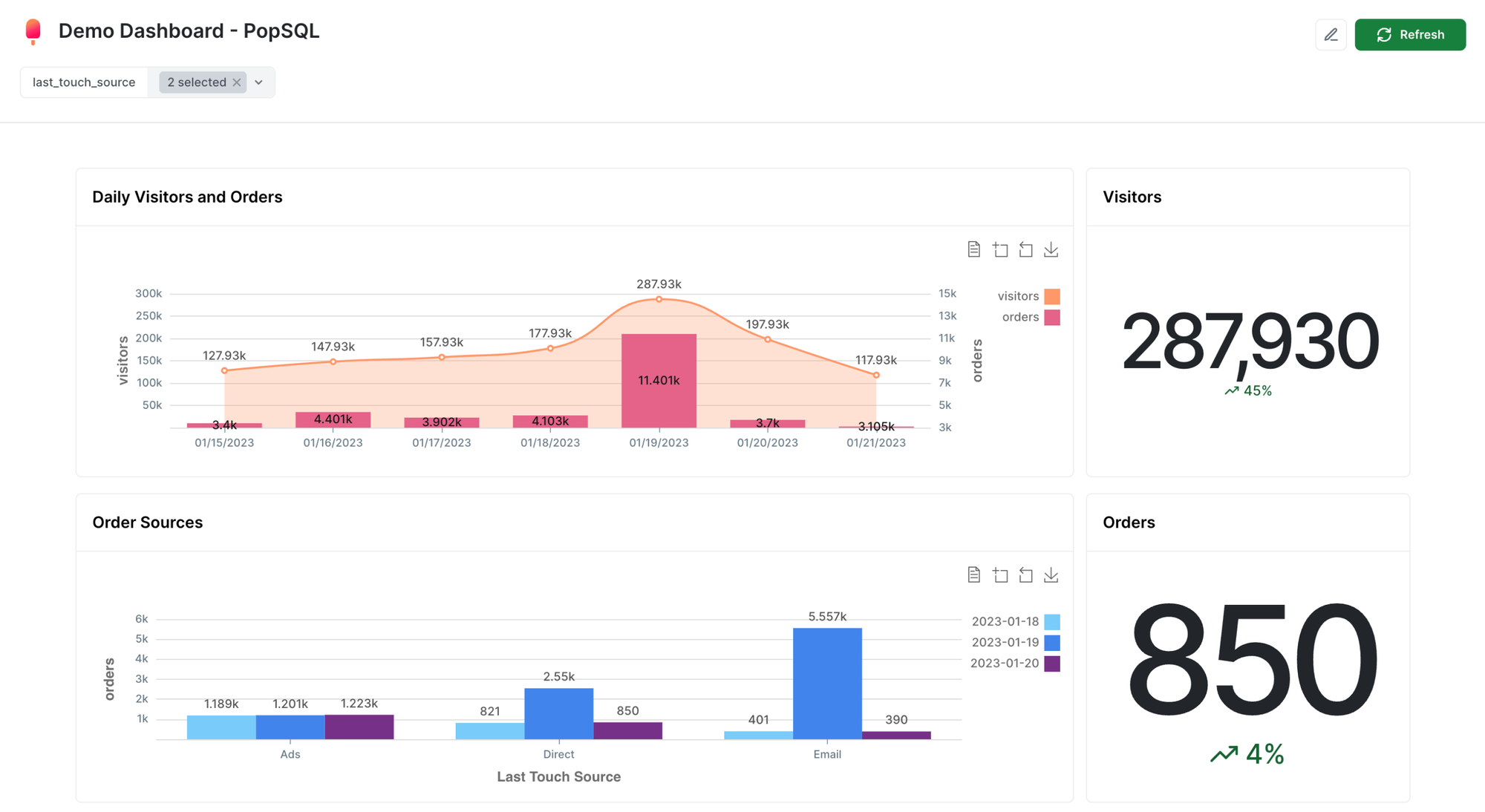
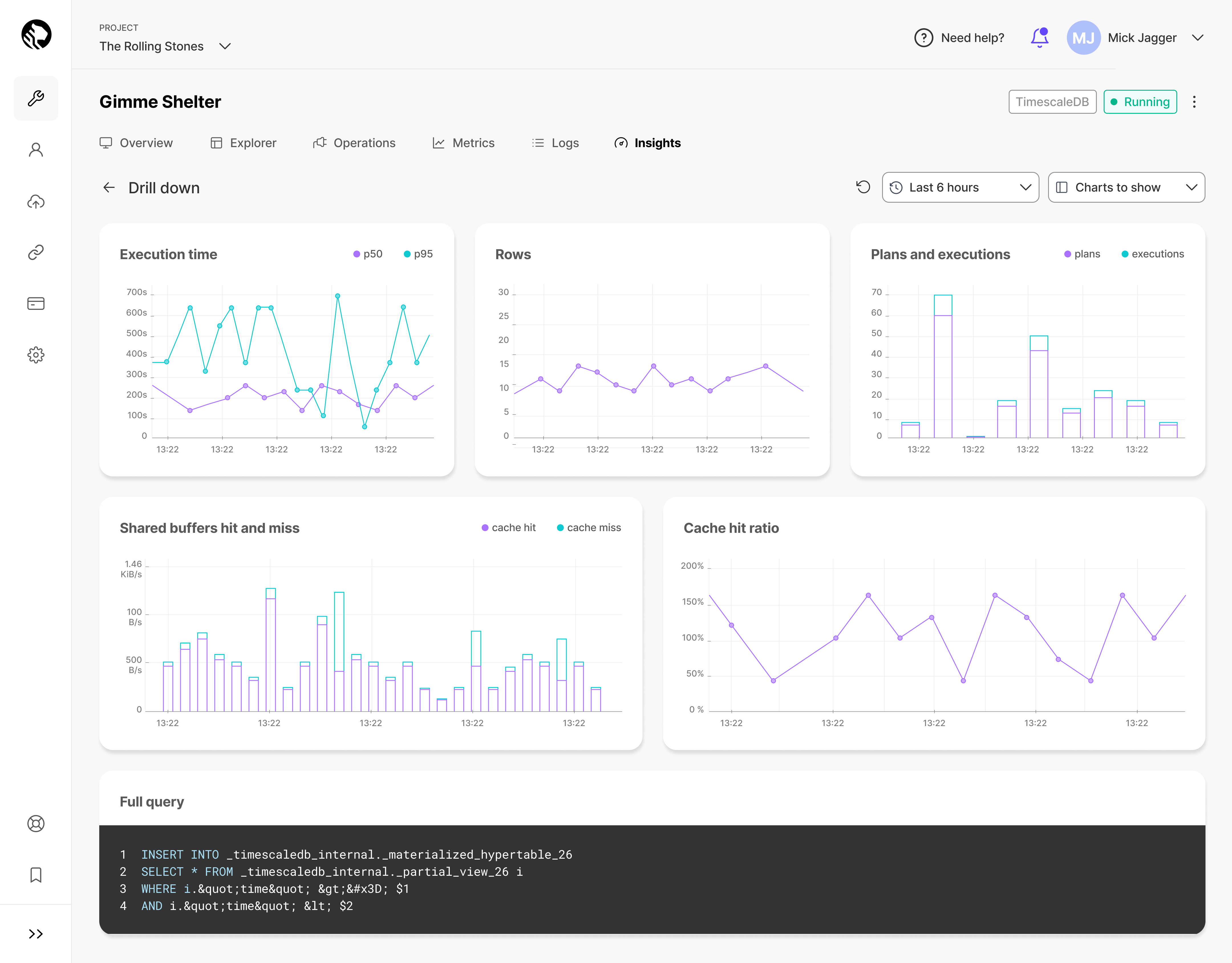
Insights
We also launched “Insights,” the largest dogfooding effort we’ve ever undertaken, which tracks every database query to help developers monitor and optimize database performance. Insights overcomes several limitations of pg_stat_statements (the official extension to see statistics from your database). The scale has been massive and is a testament to our product’s (and team’s) capability: over one trillion normalized queries (i.e., queries whose parameter values have been replaced by placeholders) have been collected, stored, and analyzed, with over 10 billion new queries ingested every day.
Timescale is now “PostgreSQL made Powerful”
Today, Timescale is PostgreSQL made Powerful—at any scale. We now solve hard data problems—that no one else does—not just in time series but in AI, energy, gaming, machine data, electric vehicles, space, finance, video, audio, web3, and much more.

We believe that developers should be using PostgreSQL for everything, and we are improving PostgreSQL so that they can.
Customers use Timescale not just for their time-series data but also for their vector data and general relational data. They use Timescale so that they can use PostgreSQL for Everything. You can too: get started here for free.
Coda: Yoda?
Our human reality, both physical and virtual, offline and online, is filled with data. As Yoda might say, data surrounds us, binds us. This reality is increasingly governed by software, written by software developers, by us.

It’s worth appreciating how remarkable that is. Not that long ago, in 2002, when I was an MIT grad student, the world had lost faith in software. We were recovering from the dotcom bubble collapse. Leading business publications proclaimed that “IT Doesn’t Matter.” Back then, it was easier for a software developer to get a good job in finance than in tech—which is what many of my MIT classmates did, myself included.
But today, especially now in this world of generative AI, we are the ones shaping the future. We are the future builders. We should be pinching ourselves.
Everything is becoming a computer. This has largely been a good thing: our cars are safer, our homes are more comfortable, and our factories and farms are more productive. We have instant access to more information than ever before. We are more connected with each other. At times, it has made us healthier and happier.
But not always. Like the force, computing has both a light and dark side. There has been growing evidence that mobile phones and social media are directly contributing to a global epidemic of teen mental illness. We are still grappling with the implications of AI and synthetic biology. As we embrace our greater power, we should recognize that it comes with responsibility.
We have become the stewards of two valuable resources that affect how the future is built: our time and our energy.
We can either choose to spend those resources on managing the plumbing or embrace PostgreSQL for Everything and build the right future.
I think you know where we stand.
Thanks for reading. #Postgres4Life
Update: Reactions
Wow, this post generated over 500,000 impressions. It clearly touched a nerve. Here are some of the public reactions:


Emails / DMs:
“I really enjoyed your article and was wondering if I could translate it into Chinese for the PG China community here. Thanks again for the great post! 😊”
“I cannot agree more with this quote: ‘More complexity means less time to build. Complex architectures are more brittle, require more complex application logic, offer less time for development, and slow down development. Complexity is not a benefit but a real cost.’ It's really fascinating to witness how companies like Timescale enrich the PostgreSQL platform. Would like to wish your company even more success!”
“Congratulations on the work you have done for the Postgres community, we need more companies doing this work of sharing knowledge as Timescale has done.”
“Excellently written piece & extremely informative. I will make sure to pass it along to my small audience on here. Keep up the great work at Timescale! I have only heard good things and I am truly excited to see the company's growth and transformation in the future.”
Of course, not all feedback was positive:


That’s okay! Our goal here is to spark thoughtful dialogue.
Thank you, everyone, for participating in this discussion. More to come. 🙂
#PostgresForEverything



