

How Newtrax Is Using TimescaleDB and Hypertables to Save Lives in Mines While Optimizing Profitability
This is an installment of our “Community Member Spotlight” series, where we invite our customers to share their work, shining a light on their success and inspiring others with new ways to use technology to solve problems.
In this edition, Jean-François Lambert, lead data engineer at Newtrax, shares how using TimescaleDB has helped the IoT leader for underground mines to optimize their clients’ profitability and save lives by using time-series data in hypertables to prevent human and machine collisions.
About the Company
Newtrax believes the future of mining is underground, not only because metals and minerals close to the surface are increasingly rare but because underground mines have a significantly lower environmental footprint. To accelerate the transition to a future where 100 percent of mining is underground, we eliminate the current digital divide between surface and underground mines.
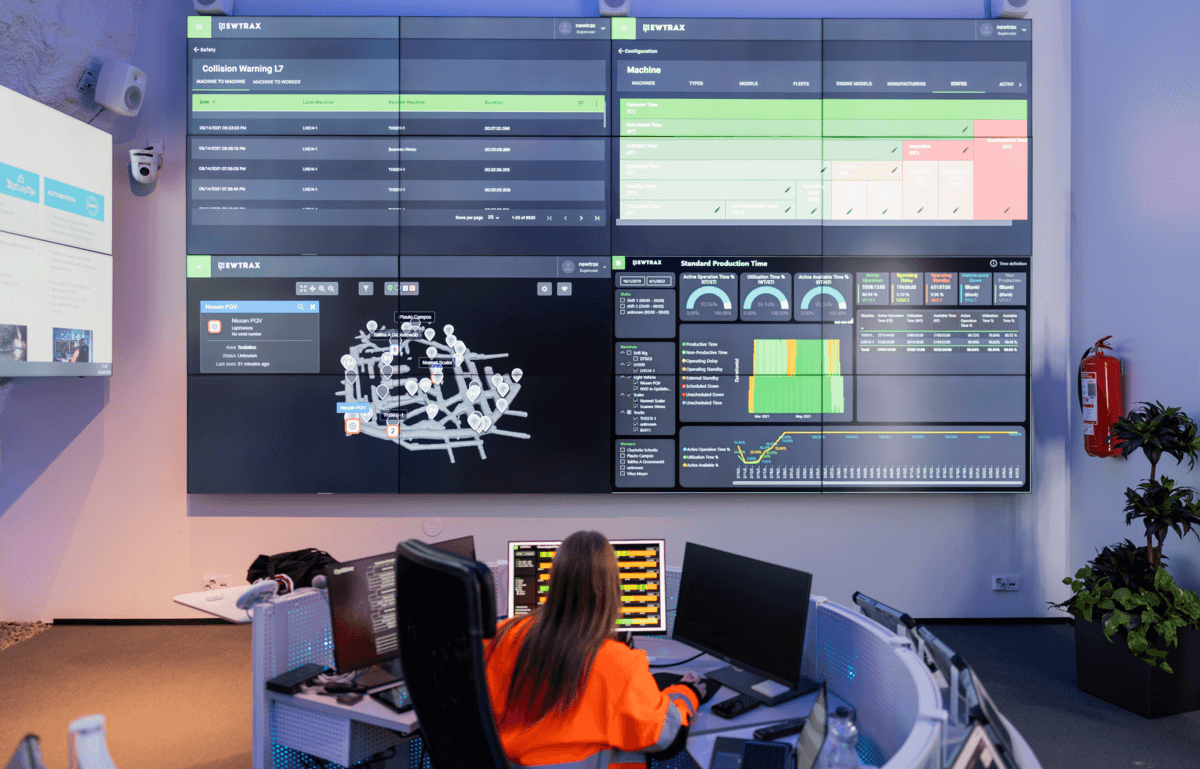
To achieve this goal, Newtrax integrates the latest IoT and analytics technologies to monitor and provide real-time insights on underground operations, including people, machines, and the environment. Newtrax customers are the largest producers of metals in the world, and their underground mines rely on our systems to save lives, reduce maintenance costs, and increase productivity. Even an increase of 5 percent in overall equipment effectiveness can translate to millions in profits.
We collect data directly from the working face by filling the gaps in existing communications infrastructures with a simple and easy-to-deploy network extension. With that, we enable underground hard rock mines to measure key performance indicators they could not measure in real time to enable short-interval control of operations during the shift.
Our headquarters are based in Montreal, Canada, and we have regional offices around the globe, totaling 150 employees, including some of the most experienced engineers and product managers specializing in underground hard rock mining. Our solutions have been deployed to over 100 mine sites around the world.
About the Team
The Newtrax Optimine Mining Data Platform (MDP) is the first AI-powered data aggregation platform enabling the underground hard rock mining industry to connect all IoT devices into a single data repository. Our team consists of software developers, data scientists, application specialists, and mining process experts, ensuring our customers get the exact solutions they require.
As the lead data engineer, it is my responsibility to define, enhance and stabilize our data pipeline, from mobile equipment telemetry and worker positioning to PowerBI-driven data warehousing via RabbitMQ, Kafka, Hasura, and of course, TimescaleDB.
About the Project

Our Mining Data Platform (MDP) platform incorporates proprietary and third-party software and hardware solutions that focus on acquiring, persisting, and analyzing production, safety, and telemetry data at more than one hundred underground mine sites across the world.
From the onset, we have had to deal with varying degrees of data bursts at completely random intervals. Our original equipment manufacturer-agnostic hardware and software solutions can acquire mobile equipment telemetry, worker positioning, and environmental monitoring across various open platforms and proprietary backbones. WiFi, Bluetooth, radio-frequency identification (RFID), long-term evolution (LTE), leaky feeder, Controller Area Network (CAN) bus, Modbus—if we can decode it, we can integrate it.
“We have saved lives using TimescaleDB”
Regardless of skill sets, programming languages, and transportation mechanisms, all of this incoming data eventually makes it to PostgreSQL, which we have been using since version 8.4 (eventually 15, whenever TimescaleDB supports it!). For the past 10 years, we have accumulated considerable experience with this world-class open-source relational database management system.
✨ Editor’s Note: Stay tuned as we’ll announce support for PostgreSQL 15 very soon, in early 2023.
While we are incredibly familiar with the database engine itself and its rich extension ecosystem, partitioning data-heavy tables was never really an option because native support left to be desired, and third-party solutions didn’t meet all of our needs.
Choosing (and Using!) TimescaleDB
I have been using PostgreSQL since I can remember. I played around with Oracle and MSSQL, but PostgreSQL has always been my go-to database. I joined Newtrax over 12 years ago, and we’ve used it ever since.
In 2019, we found out about TimescaleDB (1.2.0 at the time) and started closely following and evaluating the extension, which promised to alleviate many of our growing pains, such as partitioning and data retention policies.
Not only did TimescaleDB resolve some of our long-standing issues, but its documentation, blog posts, and community outlets (Slack, GitHub, Stack Overflow) also helped us make sense of this “time-series database” world we were unknowingly part of.
“One of our first tech debt reductions came via the use of thetime_bucket_gapfillandlocffunctions, which allowed us to dynamically interpolate mobile equipment telemetry data points that could be temporarily or permanently missing”
A tipping point for choosing TimescaleDB was the NYC TLC tutorial which we used as a baseline. After comparing with and without TimescaleDB, it became clear that we would stand to gain much from a switch: not only from the partitioning/hypertable perspective but also with regards to the added business intelligence API functionality, background jobs, continuous aggregates, and various compression and retention policies.
Beyond that, we only ran basic before/after query analysis, because we know that a time-based query will perform better on a hypertable than a regular table, just by virtue of scanning fewer chunks. Continuous aggregates and hyperfunctions easily saved us months of development time which is equally, if not more important, than performance gains.

More importantly, in order for our solutions (such as predictive maintenance and collision avoidance) to provide contextualized and accurate results, we must gather and process hundreds of millions of data points per machine or worker, per week or month, depending on various circumstances. We use hypertables to handle these large datasets and act upon them. We have saved lives using TimescaleDB.
Beyond the native benefits of using hypertables and data compression/retention policies, one of our first tech debt reductions came via the use of the time_bucket_gapfill and locffunctions (see an example later), which allowed us to dynamically interpolate mobile equipment telemetry data points that could be temporarily or permanently missing. Since then, we have been acutely following any and all changes to the hyperfunction API.
✨ Editor’s Note: Read how you can write better queries for time-series analysis using just SQL and hyperfunctions.
Current Deployment & Future Plans
As far as deployment is concerned, the mining industry is incredibly conservative and frequently happens to be located in the most remote areas of the world, so we mostly deploy TimescaleDB on-premises through Kubernetes. The main languages we use to communicate with TimescaleDB are C#, Golang, and Python, but we also have an incredible amount of business logic written as pure SQL in triggers, background jobs, and procedures.
While all of our microservices are typically restricted to their own data domains, we have enabled cross-database queries and mutations through Hasura. It sits nicely on top of TimescaleDB and allows us to expose our multiple data sources as a unified API, complete with remote relationships, REST/GraphQL API support, authentication, and permission control.
Our use of TimescaleDB consists of the following:
- We greatly appreciate
timescaledb-tuneautomatically tweaking the configuration file based on the amount of memory and number of CPUs available. In fact, Newtrax has contributed to this tool a few times. - We deploy the
timescaledb-haimage (which we also contributed to) because it adds multiple extensions other than TimescaleDB (for example,pg_stat_statements,hypopg, andpostgis), and it comes with useful command-line tools likepgtop. - Our developers are then free to use hypertables or plain tables. Still, when it becomes obvious that we’ll want to configure data retention or create continuous aggregates over a given data set, hypertables are a no-brainer.
- Even if hypertables are not present in a database, we may still use background jobs to automate various operations instead of installing another extension like
pg_cron. - Hypertables can be exposed as-is through Hasura, but we may also want to provide alternative viewpoints through continuous aggregates or custom views and functions.
✨ Editor’s Note: The TimescaleDB tuning tool helps make configuring TimescaleDB a bit easier. Read our documentation to learn how.
As mentioned earlier, incoming data can be erratic and incomplete. We might be missing some data points or values. Using a combination of the following code will create a function mine_data_gapfill, which can be tracked with Hasura and enable consumers to retrieve consistent data series based on their own needs. And you could easily use interpolate instead of locf to provide interpolated values instead of the last one received.
CREATE TABLE mine_data
(
serial TEXT,
timestamp TIMESTAMPTZ,
values JSONB NOT NULL DEFAULT '{}',
PRIMARY KEY (serial, timestamp)
);
SELECT CREATE_HYPERTABLE('mine_data', 'timestamp');
INSERT INTO mine_data (serial, timestamp, values) VALUES
('123', '2020-01-01', '{"a": 1, "b": 1, "c": 1}'),
('123', '2020-01-02', '{ "b": 2, "c": 2}'),
('123', '2020-01-03', '{"a": 3, "c": 3}'),
('123', '2020-01-04', '{"a": 4, "b": 4 }'),
('123', '2020-01-06', '{"a": 6, "b": 6, "c": 6}');
CREATE FUNCTION mine_data_gapfill(serial TEXT, start_date TIMESTAMPTZ, end_date TIMESTAMPTZ, time_bucket INTERVAL = '1 DAY', locf_prev INTERVAL = '1 DAY')
RETURNS SETOF mine_data AS $$
SELECT $1, ts, JSONB_OBJECT_AGG(key_name, gapfilled)
FROM (
SELECT
serial,
TIME_BUCKET_GAPFILL(time_bucket, MT.timestamp) AS ts,
jsondata.key AS key_name,
LOCF(AVG((jsondata.value)::REAL)::REAL, treat_null_as_missing:=TRUE, prev:=(
SELECT (values->>jsondata.key)::REAL
FROM mine_data
WHERE values->>jsondata.key IS NOT NULL AND serial = $1
AND timestamp < start_date AND timestamp >= start_date - locf_prev
ORDER BY timestamp DESC LIMIT 1
)) AS gapfilled
FROM mine_data MT, JSONB_EACH(MT.values) AS jsondata
WHERE MT.serial = $1 AND MT.timestamp >= start_date AND MT.timestamp <= end_date
GROUP BY ts, jsondata.key, serial
ORDER BY ts ASC, jsondata.key ASC
) sourcedata
GROUP BY ts, serial
ORDER BY ts ASC;
$$ LANGUAGE SQL STABLE;
SELECT * FROM mine_data_gapfill('123', '2020-01-01', '2020-01-06', '1 DAY');
You can find this code snippet on GitHub too.
Roadmap
We need to start looking into the timescaledb-toolkit extension, which is bundled in the timescaledb-ha Docker image. It promises to “ease all things analytics when using TimescaleDB, with a particular focus on developer ergonomics and performance,” which is music to our ears.
“Honestly, the TimescaleDocs had most of the resources we needed to make a decision between switching to TimescaleDB or continuing to use plain PostgreSQL (this article in particular)”
Another thing on our backlog is to investigate using Hasura’s streaming subscriptions as a Kafka alternative for specific workloads, such as new data being added to a hypertable.
Advice & Resources
Honestly, the TimescaleDocs had most of the resources we needed to make a decision between switching to TimescaleDB or continuing to use plain PostgreSQL (this article in particular). But don’t get too swayed or caught up in all the articles claiming outstanding performance improvements: run your own tests and draw your own conclusions.
We started by converting some of our existing fact tables and got improvements ranging from modest to outstanding. It all depends on your use cases, implementations, and expectations. Some of your existing structures may not be compatible right out of the box, and not everything needs to become a hypertable either! Make sure to consider TimescaleDB’s rich API ecosystem in your decision matrix.
Sign up for our newsletter for more Developer Q&As, technical articles, tips, and tutorials to do more with your data—delivered straight to your inbox twice a month.
We’d like to thank Jean-François and all of the folks at Newtrax for sharing their story on how they’re bringing digital transformation to a conservative industry—all while saving lives along the way, thanks to TimescaleDB and hypertables.
We’re always keen to feature new community projects and stories on our blog. If you have a story or project you’d like to share, reach out on Slack (@Ana Tavares), and we’ll go from there.




