How Timescale Replication Works: Enabling HA in PostgreSQL
In March 2022, we released early access to a highly requested feature: database replication in Timescale. One of our guiding principles as a company is that boring is awesome and that your database should be boring: we believe that you should be able to focus on your applications rather than on the infrastructure on which they’re running.
Replicas is a feature commonly available in most databases, and we’re surfacing that functionality in an easy-to-use experience within Timescale. As with all things Timescale, we build on top of the proven functionality available in PostgreSQL, the foundation of TimescaleDB.
Database replication in Timescale is as easy as pressing a button. By enabling a replica, you will increase the availability of your data, assuring that you will only experience a few seconds of downtime if your database fails—but that’s not all. In Timescale, enabling replicas can also improve performance, as you can easily direct your heavy read queries to the replica, which frees up resources in your main database for higher ingest rates, more advanced continuous aggregates, or additional read queries.
Read on to learn more about replicas in Timescale, how we make them work under the hood, and how you can use database replication to increase data availability and liberate load in your Timescale database.
If you’re new to Timescale, try it for free. Once you’re up and running, join our community of 8,000+ developers passionate about TimescaleDB, PostgreSQL, time-series data, and all its applications! You can find us in the Timescale Community Forum and our Community Slack.
How Replicas Work
Replicas are duplicates of your main database, which in this context is called “primary.” When you enable a replica, it will stay up-to-date as new data is added, updated, or deleted from your primary database. This is a major difference between a replica and a fork, which Timescale also supports: a fork is a snapshot of your database at a particular moment in time, but once created, it is independent of your primary. After forking, the data in your forked service won’t reflect the changes in the primary.
PostgreSQL (and thus TimescaleDB) offers several methods for replication. However, setting up replication for a self-hosted database is a difficult task that includes many steps—from choosing which options suit you best to actually spinning up a new server and adjusting configuration files, tweaking configurations, and building a full infrastructure that monitors the health of your primary and automatically failing-over to a replica when needed. All the while avoiding “split-brain” scenarios in which two separate services both believe they are primaries, leading to data inconsistency issues.
Timescale automates the process for you: we do the hard work, so you don’t have to.
Adding a replica to your Timescale service is extremely simple (more on that later). But as a more technical deep dive for the interested reader, the following paragraphs cover three design choices we’ve taken for replicas: (i) the choice of asynchronous commits, (ii) their ability to act as hot standbys, and (iii) their use of streaming replication.
Timescale replicas are asynchronous
The primary database will commit a transaction as soon as they are applied to its local database, at which point it responds to a requesting client successfully. In particular, it does not wait until the transaction is replicated and remotely committed by the replica (as would be the case with synchronous replicas).
Instead, the transaction is asynchronously replicated to the replica by the primary shipping its Write-Ahead Log (WAL) files, hence the “quasi-real-time” synchronicity between primary and replica.
We chose this design pattern for two important reasons. The first one, perhaps surprisingly, is high availability: with a single synchronous replica, the database service would stop accepting new writes if the replica fails, even if the primary remains available. The second is performance, as database writes are both lower latency (no round trip to the replica before responding) and can achieve higher throughput. And that’s important for time-series use cases, where ingest rates are often quite high and can be bursty as well.
In the future, when we add support for multiple replicas, we plan to introduce the ability to configure quorum synchronous replication, where a transaction is committed once written to at least some replicas, but not necessarily all. This addresses one trade-off with asynchronous replication, where a primary failure may lead to the loss of a few of the latest transactions that have yet to be streamed to any replicas.
Timescale replicas act like hot standbys
A warm standby means that the replica (standby) is ready to take over operations as soon as the primary fails, as opposed to a “cold standby,” which might take a while to restore before it can begin processing requests. This is closely related to the high availability mentioned earlier. The process of the standby/replica becoming the primary is called failover, which is covered more below. Since Timescale replicas are also read replicas—i.e., they can also be used for read-only queries—they are considered hot standbys instead of just warm standbys.
As we will talk about in later sections, allowing you to read from your replicas gives you the option to direct some of your read-only workloads to your replica, freeing capacity in your primary. This means that in Timescale, you will not only have a replica ready to take over at any moment if the primary happens to fail, but you can also get value from it beyond availability, even if there’s no failure.
Timescale replicas use streaming replication
Streaming replication helps ensure there is little chance of data loss during a failover event. Streaming replication refers to how the database’s Write-Ahead Log—which records all transactions on the primary—is shipped from the primary to the replica. One common approach for shipping this WAL is aptly named “log shipping.” Typically, log shipping is performed on a file-by-file basis, i.e., one WAL segment of 16 MB at a time. So, these files aren’t shipped until they reach 16 MB or hit a timeout.
The implication of log shipping, however, is that if a failure occurs, any unshipped WAL is lost. Instead of file-based log shipping, Timescale uses streaming replication to minimize potential loss. This means that individual records in the WAL are streamed to the replica as soon as they are written by the primary rather than waiting to ship as an entire segment. This method minimizes the potential data loss to the gap between a transaction committing and the corresponding WAL generation.
Timescale replicas use Patroni for the greater good
We haven’t yet examined the precise mechanism for managing switchovers/failovers. PostgreSQL lacks the built-in capabilities for this task. To accomplish it, interaction with our infrastructure layer is required, which involves Kubernetes running on EC2. PostgreSQL remains unaware of this infrastructure.
When a failover occurs, traffic must seamlessly transition to different nodes without requiring any reconfiguration within user applications. There is no secret sauce to this, just open source, so let's delve deeper into it.
We are using Patroni as our high availability orchestrator (Patroni calls itself “a template for high availability (HA) PostgreSQL solutions”). Its power resides in its ability to integrate with different distributed configuration databases, allowing every member of a PostgreSQL cluster to know their role and adjust it whenever it’s necessary.
We are using Kubernetes on EC2 to run databases on the Timescale cloud. Kubernetes serves as the platform-as-a-service (PaaS) layer on top of Amazon Web Services, which is convenient for automation and defines much of our tech stack.
One of the few things you need to know about Kubernetes is that it can run processes on a distributed cluster of nodes (EC2 instances). Those processes run inside so-called pods. Kubernetes can interact with the underlying cloud provider to allow pods to be reached from anywhere in the world over the internet.
Since Kubernetes uses Etcd as its configuration store, it can also be viewed as a distributed configuration store. Patroni can use the Kubernetes API in that capacity to keep members of PostgreSQL clusters synced. Have a look at the Patroni documentation to know more about this integration.
For databases running in our cloud, Patroni is configured to use endpoints to synchronize the state of cluster members. The original purpose of endpoints in Kubernetes is to work as connections between pods and the rest of the world.
By changing endpoint parameters, Patroni can instruct Kubernetes to move traffic from one pod to another or completely cut off a pod from the network. That’s why primary and replica URLs always magically point to the database of a corresponding role even though they move between nodes and change roles between each other.
Apart from keeping all cluster members in sync, Patroni directly manages PostgreSQL processes and configurations. When a pod with a database is started, Patroni is the first process inside it, joining the cluster and figuring out its role.
Patroni knows how to configure the underlying PostgreSQL process only after this occurs. It then monitors the state of underlying PostgreSQL processes, as well as the states of other cluster members. If it detects PostgreSQL fails or any significant changes to other members (for instance, a leader goes away), it takes action to adjust the state of underlying PostgreSQL to the new cluster topology.
King of the hill
Members of the cluster use metadata of the same endpoint object named after a cluster (a.k.a., service ID) to store information about the current leader and the time when the leader status was last renewed.
The life of each Patroni cluster starts with a race in which all cluster members play the “king of the hill" game. Whoever manages to write its name in the endpoint first becomes the leader. Patroni ensures that only the leader is promoted to the primary: that's how it avoids a split-brain.
After that happens, the cluster remains in dynamic equilibrium. By default, the leader confirms its status once every 10 seconds, and all other members check to see if the leader is still updating its status because each of them wants to become a leader.

But life without drama is boring. That’s why the first failure is happening in our cluster. PostgreSQL, which is controlled by the Patroni leader, crashes, and Patroni immediately notices that. Not to waste precious time, it releases the lock and informs the other members that it’s time to join the race again.

Patroni, who controls one of the replicas, acquires the lock and becomes the leader. PostgreSQL, which Patroni controls, is promoted to primary. In the meantime, the former leader recovers and starts as a replica.

The cluster reaches a new state of dynamic equilibrium. The former primary is left dreaming when it will return to the lead.

However, failures can be much more critical than just a PostgreSQL crash. Let’s allow ourselves some freedom of imagination and unleash a tsunami on the exact availability zone where the new primary is running. It wipes off the whole data center, bringing to the bottom of the sea all the servers where Patroni, Postgres, and two members of Etcd clusters were running.
Here, we need to mention one thing about the Etcd cluster. Even though it might seem an insignificant implementation detail to understand how replicas work, we still rely on Etcd when we run Patroni with Kubernetes API as a configuration store. And like it usually happens in distributed configuration stores, the cluster expects to have a quorum of members to be able to function properly. It means that a cluster is aware of the number of members that are participating in the cluster and allows to write to the database only when the majority of cluster members can acknowledge the write.
The right part of the following picture is on the bottom of the sea, and even if the cluster wanted to write to the Etcd database, it wouldn’t be able to because a minority of Etcd cluster members happened to be there. The remaining three members of the cluster in the left data center haven’t shared the fate of the right one and still represent the quorum.

The replica on the left keeps trying to acquire the master lock every 10 seconds as if nothing happened. After three attempts, it succeeds and becomes the new leader. In this scenario, the cluster will have to wait the longest to resume the writes. If the left cluster wasn’t that fortunate and the majority of Etcd members would have yielded to the waves, the situation would not have been that fortunate, though.
The remaining two members of the cluster would not have permitted the writes because they would not represent the quorum; hence they would have never been able to write the master lock to the cluster and would have never been promoted to leader. In our clusters, Etcd members are spread across three availability zones. That’s why, to lose the quorum, we would need to lose at least two of the availability zones. That’s already a dinosaur extinction scale of events, and if it happens, we all have a much bigger problem at hand than caring about what database is the primary.

If Etcd is down, Patroni also has a failsafe to check every cluster member through Patroni's internal API on every check, and every heartbeat interval. If the nodes can be reached, the cluster state stays as it is. If a cluster member is terminated and restarted, it will always start as read-only until the Etcd is back.
Enabling Replicas for High Availability
Even without a replica enabled, Timescale has a range of automated backup and restore mechanisms that protect your data in case of failure. For example, the most common type of failure in a managed database service is a compute node failure; in Timescale, it often takes only tens of seconds to recover from such a failure, as we are able to spin up a new compute node and reattach your storage to it. In the much rarer case, in which a failure affects your (replicated) storage, Timescale automatically restores your data from backup at a rate of roughly 10 GB per minute.
For some use cases, the potential level of downtime associated with this recovery process is completely acceptable; for those customer-facing applications that require minimal downtime, replicas will provide the extra layer of availability they need.
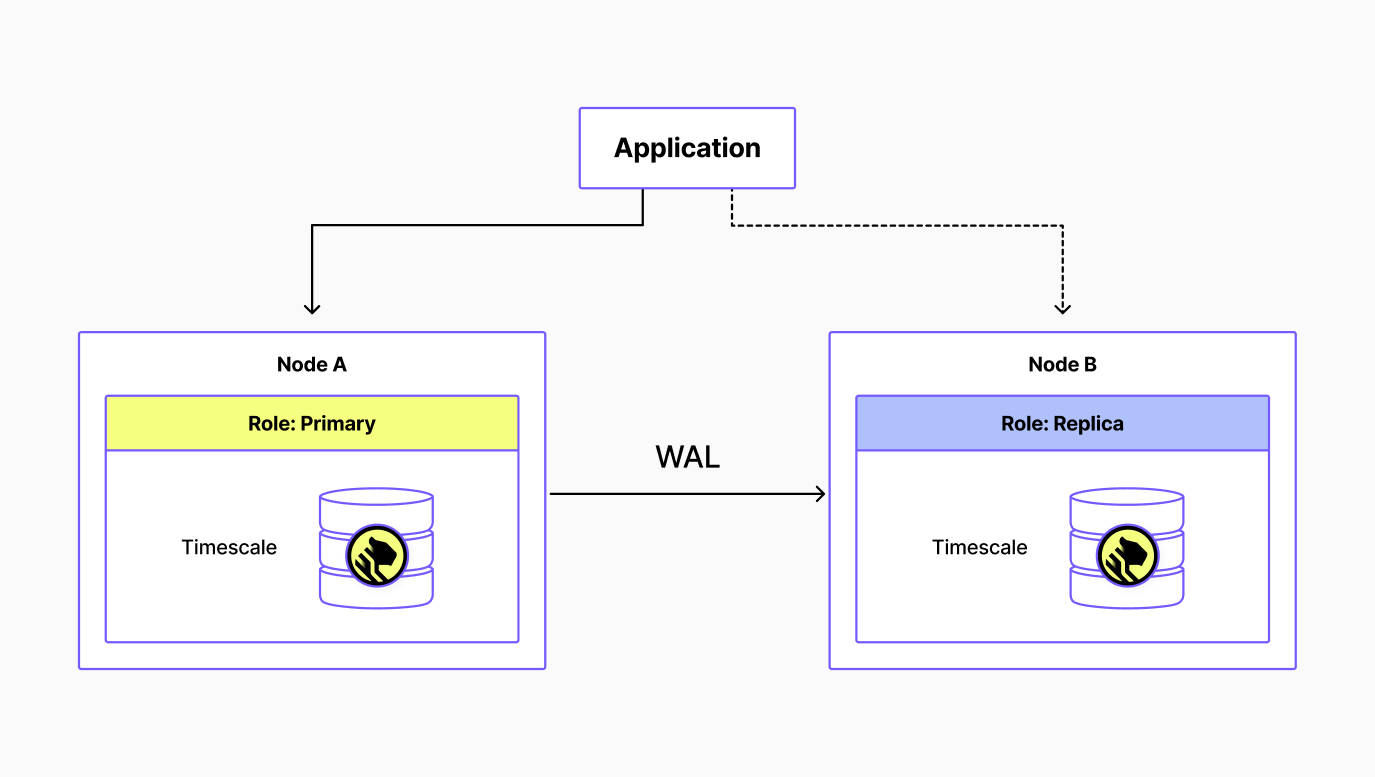
The recovery process through replicas is summarized in the figures below. In a normal operating state, the application is connected to the primary and optionally to its replica to scale read queries. Timescale manages these connections through load balancers, defining the role for each node automatically.

The next figure illustrates a failover scenario. If the primary database fails, the platform automatically updates the roles, “promoting” the replica to the primary role, with the primary load balancer redirecting traffic to the new primary. When the failed node either recovers or a new node is spun up, it assumes the replica role. The promoted node remains the primary, streaming WAL to its new replica.

When the failed node either recovers or a new node is spun up, it assumes the replica role. The promoted node remains the primary, streaming WAL to its new replica.

On top of increasing the availability of your database in case of failure, replicas also essentially eliminate the downtime associated with upgrades, including database, image, or node maintenance upgrades. These upgrades usually imply 30 to 60 seconds of downtime without a replica.
With a replica, this is reduced to about a second (just the time to failover). In this case, when the upgrade process starts, your system will switch over to the replica, which now becomes the primary. Once the upgrade is completed in the now-replica-formerly-primary, the system switches back so it can subsequently upgrade the other node. (On occasion, the replica is upgraded first, in which case only one failover will be necessary.)
Read Replicas: Enabling Replicas for Load Reduction
Timescale's replicas act as “hot standbys” and thus also double as read replicas: when replicas are enabled, your read queries can be sent to the replica instead of the primary.
The main advantages of read replicas are related to scalability. By allowing your replica to handle all of the read load, your primary instance only has to handle writes or other maintenance tasks that generate writes, such as TimescaleDB’s continuous aggregates. Using read replicas would result in higher throughput for writes and faster execution times on analytical reads, plus a less strained primary instance.
For example, read replicas can be particularly useful if you have many Grafana dashboards connecting to your service. Since visualizations don’t need perfectly real-time data—that is, using data that’s a few seconds old is often more than acceptable—the replica can be used to power these dashboards without consuming resources on the primary.
Plus, with this setup, data analysts can work with up-to-date production data without worrying about accidentally impacting the database operations, such as with more ad-hoc data science queries.
Another benefit of using read replicas is to limit the number of applications with write access to your data. Since the entire replica database is read-only, any connection, even those with roles that would have write privileges in the primary, cannot write data to the replica.
This can serve to easily isolate applications that should have read/write access from those that only need read access, which is always a good security practice. Database roles should certainly also be used to ensure “least privilege,” but a bit of redundancy and “defense in depth” doesn’t hurt.
Enabling replicas in Timescale
Your database should be worry-free: You shouldn't have to think about it, especially if there’s a problem. As any database operator knows, failures occur. But, a modern database platform should automatically recover and re-establish service as soon as issues arise. Our commitment is to build a dependable, highly available database that you can count on. Boring is awesome when the platform prevents you from getting paged at 3 a.m.
Many architectural aspects of Timescale are intentionally aligned with this high availability goal. For example, Timescale’s decoupled compute and storage is not only great for price optimization but also for high availability. In the face of failures, Timescale automatically spins up a new compute node and reconnects it to the existing decoupled database storage, which itself is independently replicated for high availability and durability.
Indeed, even without a replica enabled, this cloud-native architecture can provide a full recovery for many types of failures within 30-60 seconds, with more severe physical server failures often taking no more than several minutes of downtime to recover your database.
Further, incremental backups are taken continuously on Timescale for all your services (and stored separately across multiple cloud availability zones), allowing your database to be restored to any point in time from the past week or more. And Timescale continuously smoke tests and validates all backups to ensure they are ready to go at a moment’s notice.
However, many customers run even their most critical services on Timescale, where they need almost zero downtime—even in the case of unexpected and severe hardware failures. Indeed, Timescale powers many customer-facing applications, where downtime comes with important consequences for the business: application dashboards stop responding, assembly lines are no longer monitored, IoT sensors can no longer push measurements, critical business data can be lost, and more. Database replication provides that extra layer of availability (and assurance) these customers need.
Apart from decreasing downtime, Timescale replicas have another advantage: they can also help you ease the load from your primary database. If you are operating a service subjected to heavy read analytical queries (e.g., if you’re using tools like Tableau or populating complex Grafana dashboards), you can send such read queries to the replica instead of to your primary database, liberating its capacity for writes and improving performance. This makes your replica useful even in the absence of failure.
Leveraging this functionality is as easy as using a separate database connection string that Timescale makes available: one service URL for your (current) primary, and the platform transparently re-assigns this connection string to a replica if that replica takes over and a second service URL that maps to your read-only replica.
If you are already a Timescale user, you can immediately set up a database replica in your new and existing services. Enabling your first replica is as simple as this:
- Select the service you’d like to replicate.
- Under “Operations,” select “High availability” on the left menu.
- To enable your replica, click on “Add HA replica.”
That’s it! 🔥
If a service has a replica enabled, it will show under Operations -> High availability. (Take into account that the replica won’t show in your Services screen as a separate database service, as it is not an independent service.)
If you want to direct some of your read queries to the replica, go to your service's “Overview” page. Under “Connect to your service,” you will see a drop-down menu allowing you to choose between “Primary” and “HA replica.” To connect to your replica, you can simply select “HA replica” and use the corresponding service URL.
Database replication is still in active development. We will add new functionality to replicas in the future.
You’ll hear from us again!
Coming soon
We released database replication under an “early access” label, meaning this feature is still in active development. We’ll be continuing to develop capabilities around database replication in Timescale, including:
- Multiple replicas per database service
- Greater flexibility around synchronous vs. asynchronous replicas
- Replicas in different AWS regions
So keep an eye out—more replication options coming soon!
Get Started
Timescale’s new database replication provides increased high availability and fault tolerance for your important database services. It also allows you to scale your read workloads and better isolate your primary database for writes. Check out our documentation for more information on how to use this database replication in Timescale.
Replicas are immediately available for Timescale users. If you want to try Timescale, you can create a free account to get started—it’s 100 % free for 30 days, and no credit card required. If you have any questions, you can find us in our Community Slack and the Community Forum.