

Space Exploration and Time-Series data: Why the European Space Agency Uses PostgreSQL
Big, small, relational, time-series, & geospatial data — How the European Space Agency uses PostgreSQL & TimescaleDB for the “Digital Library of the Universe”.
(The following post was written based on a joint talk given at PostgresConf US 2018 between ESA and Timescale.)
Space. That object of endless human curiosity. That setting for countless stories, books, and movies. The subject of large coordinated scientific efforts aimed at exploration and understanding. And a source of a massive amount of data.
The European Space Agency (ESA) is an intergovernmental organization of 22 member states dedicated to the exploration of space for the citizens of the world.
A crucial part of ESA’s efforts is collecting massive amounts of data and putting it to good use. In this post, we take a closer look at one of its departments called the ESDC (“ESAC Science Data Center”), and how it chose to standardize on PostgreSQL for its “Digital Library of the Universe”. We also look closely at the role that time-series data plays in space exploration, and how ESDC is using TimescaleDB to harness the power of this data.
Developing the Digital Library of the Universe
There are over 20 planetary, heliophysics, and astronomy missions at ESA. ESDC is tasked with archiving the data from all of them into a “Digital Library of the Universe.”
This universal archive serves as a repository of every mission history, hosting data for all research needs with the main goal of serving the public and scientific communities. ESDC makes this archive available by providing scientific teams all around the world privileged access to this data.

When it came to developing this “Digital Library”, ESDC had to find a database system that was reliable but would also provide the broadest access to the general scientific community at large.
In the past, ESDC had used legacy database systems: e.g., Oracle, Sybase, DB2, SQL Server. However, all of the reasons why businesses in general look for open-source alternatives to these systems also apply to ESDC: vendor lock-in, total cost of ownership, convoluted pricing models, and a lack of a larger community/ecosystem.
In particular, ESDC needed an open-source database system that would allow scientists to:
- Take advantage of the collective knowledge and experience gained by sharing information
- Cross-reference datasets between missions via a shared query language (which typically happened to be SQL)
- Leverage a broad ecosystem of compatible tools, connectors, and libraries, so that scientists could focus on the data
Put another way, storing this data in a proprietary or esoteric system would diminish its reach and value. Similarly, siloing individual mission archives into separate database systems would create barriers to analysis, e.g., by forcing scientists to write glue code to tie the systems together. And working with a NoSQL system with its own query language would require educating team members and the general community, which would take up time and resources, further detracting from the main task at hand.
All these pain points led the ESDC team to fully embrace open-source tools and to ultimately choose PostgreSQL as the database on which to standardize.
PostgreSQL as a platform for scientific research
At first glance, PostgreSQL is an obvious candidate for storing the Digital Library. It has been under active use and development for nearly three decades. (In fact, there are very few open-source databases with the kind of longevity that PostgreSQL offers.) It is an open-source database that supports SQL, a query language that has been around even longer, is constantly evolving, and is still today arguably the most widely-used query language for data analysis.
PostgreSQL is also a database with one of the largest and most active communities. It also has an incredibly large ecosystem of compatible tools, connectors, and libraries that allow users to build the stack that suits them, their applications, and their users.
If you look further, you’ll find even more reasons that make PostgreSQL a great fit.
Storing all kinds of data in PostgreSQL
As you can probably imagine, ESDC collects lots of data, of many kinds.
First they have the relational metadata describing each mission, satellite, its parts, processes, etc. Then there is the data that each mission generates: geo-spatial, time-series, some structured and some unstructured.
Some of this data is handled by core PostgreSQL, which has robust support for a variety of data types and primary and secondary indexes. For example, relational data is what core PostgreSQL is designed for.
Even unstructured data (e.g., logs and text) is handled well by core PostgreSQL, which has native support for JSON and JSONB (which can be fully indexed), and full text search.
But for geo-spatial and time-series data, ESDC had to look to the larger PostgreSQL ecosystem for help.
Searching across the sky

First, ESDC needed the ability to search across the sky: draw polygons and pull data geo-located within some portion of space.
This is where the PostgreSQL extension framework came in handy. The extension framework provides a set of APIs that allow external developers to augment PostgreSQL and build features and functionality as if they were built-in. Some of these extensions are quite powerful, enabling PostgreSQL to serve more as a real data analysis platform than just a singular system.
One popular extension is PostGIS, which adds support for geospatial data analysis. With PostGIS, ESDC could work with PostgreSQL as they normally would, but gained new powers to ask their location-based questions. They also added other extensions like pg_sphere (for additional spherical data types, functions, operators, and indexing) as well as q3c (for spatial indexing on spheres). Altogether, PostgreSQL’s support for geospatial data storage and analytics through these extensions were a major driver for ESDC to migrate their archives to it.
Yet one challenge still remained: scaling PostgreSQL for time-series workloads.
Because of the nature of time-series data, ESDC recognized that they would end up with a lot of it rather quickly. And with a database already into the tens of terabytes, with expectations of 100x growth once new missions come online, scalability was already a real concern. ESDC also had other time-series requirements: out-of-order inserts, irregular inserts, arbitrary time aggregates, and more.
In other words, ESDC required a time-series store with scalability and specific time-series functionality, neither of which PostgreSQL could handle on its own. As they were putting the pieces in place for an archive of an upcoming mission, the Solar Orbiter, they looked to another extension to provide this support: TimescaleDB.
The Solar Orbiter Archive and time-series data

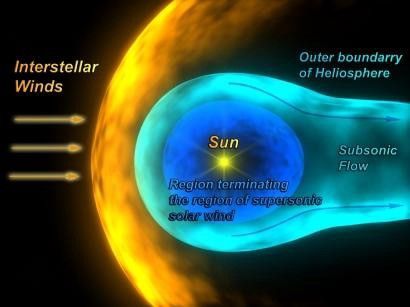
The Solar Orbiter mission’s objective is to perform close-up, high-resolution studies of our Sun and inner heliosphere. The heliosphere (see title photo) is a bubble-like region that protects our solar system from the outside pressure of the interstellar medium, which is made up of the matter and radiation that exists in the space between the star systems in a galaxy (e.g., our Milky Way).
With a combination of in-situ and remote-sensing instruments, the Solar Orbiter will address a central question of heliophysics: How does the Sun create and control the heliosphere?
To do this, Solar Orbiter will collect a lot of information (an estimated 100s of terabytes) over many years, such as:
- Constituents of solar wind plasma (protons, alpha particles, electrons, heavy ions)
- Properties of suprathermal ions and energetic particles
- Measurements of the heliospheric magnetic field
- Measurements of electromagnetic and electrostatic in the solar wind
The subsequent Solar Orbiter Archive (SOAR) files are comprised of three types of variables: data variables of primary importance (e.g., density, magnetic_field, particle_flux) and support_data variables of secondary importance (e.g., energy_bands associated with particle_flux) measured over time; and metadata variables (e.g., a label for magnetic field).
Storing time-series data of the Sun and Heliosphere
For storing this time-series data, the ESDC team first looked at a variety of specialized time-series databases. Some examples of these include (note that ESDC did not evaluate all of these): OpenTSDB, Kdb, InfluxDB, Prometheus, etc. Yet these are all NoSQL systems, and the team was already starting to standardize on SQL and PostgreSQL.
For SOAR time-series storage, ESDC also had additional needs:
- Structured data types
- Ability to discover and explore data with ad hoc queries, especially allowing cross-matching between datasets
- Support for a moderate to large data volume (up to 100s terabytes).
(Note that since the data was delivered in batches per spacecraft dump and processing, insert velocity was not a strong requirement.)
First, the ESDC team tried to develop a scalable time-series datastore themselves in PostgreSQL. In parallel, they also began to evaluate TimescaleDB, since it is an open-source time-series database packaged as a PostgreSQL extension that handles scalability automatically and transparently for the user.
While ESDC found some success scaling PostgreSQL by implementing declartive partitioning (first introduced in PostgreSQL 10), they found that that approach still had some performance challenges and would require quite a bit of manual effort.
In fact, the performance challenges with declarative partitioning in PostgreSQL was something we had already found in our experiments:

In particular, with time-series data it is not uncommon to end up with thousands of partitions (there are TimescaleDB users with tens of thousands of partitions), so this insert performance with PostgreSQL was a real problem.
Note: While PostgreSQL 11 (slated for release later this year) addresses some of the performance issues with many partitions (including, critically, improved partition pruning on select queries), significant performance issues still remain for both insert and select queries as the number of partitions grows into the 100s.
On the other hand, ESDC found TimescaleDB more performant, and also easier-to-use.
TimescaleDB transparently and automatically partitions time-series data, but then hides all that partition complexity behind an abstraction layer called a hypertable. Hypertables, in turn, have the exact interface of normal PostgreSQL tables. This removes the need to manually implement table inheritance or declarative partitioning, and lets one effectively store billions of rows of data within one virtual table.
In other words, as an extension to PostgreSQL engineered for time-series workloads, TimescaleDB:
- Natively supports full SQL
- Supports JOINs between time-series hypertables and normal PostgreSQL tables
- Adds functionality for working with time-series data in PostgreSQL
- Adds lower level query planner logic and optimizations for various time-series queries
- Offers high insert throughput (150K rows or over 1 million metrics per second)
- Scales upwards of 100 terabytes per server
- Plays well with geospatial data via PostGIS and other extensions
- Can be made highly available (via PostgreSQL streaming replication)
Put another way, TimescaleDB combines the scalability of the NoSQL systems ESDC reviewed, while natively supporting full SQL and leveraging all that PostgreSQL has to offer.
Thanks to these capabilities and features, ESDC selected TimescaleDB as the first candidate to fit the time-series needs for the Solar Orbiter Archive.
We look forward to watching SOAR’s progress and seeing how the time-series data it collects will enable the scientific community to learn more about our Sun and heliosphere.
Bringing this back to earth
Of course, time-series data isn’t just about space.
Why does ESA continue to build expensive, specialized and meticulously crafted satellites and launch them into space? Similar to why application developers collect data of user interactions, or why oil & gas operators put thousands of sensors on their wells: analyzing data to better understand the amazingly complex reality around us.
Next Steps
If you identify with ESDC’s use case, we encourage you to consider using TimescaleDB to store, analyze, and manage your time-series data.
If you’re ready to get started, please download TimescaleDB via the installation instructions, and as always, let us know if you have any questions.
Like this post? Want to learn more about how other businesses are using PostgreSQL and TimescaleDB? Join our Slack channel and sign up for our community mailing list below.



