

Announcing Explorer: A Better Way to Understand Your Cloud Database
To close out our first week of Always Be Launching month, we are announcing the “Explorer,” a new feature in our cloud-native database service designed to be your easy-to-use “operations center.”
Ever since Timescale’s launch four years ago, we’ve focused on building a database that’s fast and scalable yet also easy and worry-free. It’s the Postgres you know, trust, and love—but now supercharged for time series. In fact, our launch post in April 2017 was titled “When Boring is Awesome” because “TimescaleDB is designed to just work, not wake you up at 3 a.m.”
But in software, four years is a long time, and a lot has changed since then.
These days, most developers prefer to obtain their database through fully managed cloud offerings. The reason, if you think about it, is the same reason why users also prefer to use SaaS software in general. We don’t want to worry about managing an on-premises email server, a CRM software installation, or a database. We just want it to work.
But in some ways, developers are different from the typical SaaS user.
Developers expect their cloud database service to be fast, easy, and worry-free. But developers also want to be in control: they want visibility into source code, the ability to use all their favorite tools, and purpose-built dashboards that give them insight into how their service is performing.
And therein lies the key challenge. As a developer, how do you maintain full control over your services while ceding operations and management to a third party? What does “full control” even mean in a managed service offering?
We believe that it is possible to strike a balance between worry-free and control. Our belief is that developers who opt for managed services must have, at minimum, full data portability and complete access to the underlying source. We also believe that great managed database services go further and offer fine-grained control over storage parameters, easy integration with a broad ecosystem of development and management tools, and rich dashboards that provide insight into operations.
To continue serving developers and keep evolving with their needs, we’ve launched cloud services that offer managed TimescaleDB, and simply called it Timescale.
Timescale is our cloud-native database service, and it embraces this ethos operationally. It’s worry-free—Postgres under the hood, and we do all the operations and management work for you—but provides control when and where you want.
Remember, because TimescaleDB is also a database you can install and run yourself for free (with all our source code right there on GitHub), the ultimate control we offer developers is a lack of vendor lock-in compared to closed, managed-only services. Developers can always take their data (or easy backup) and start running TimescaleDB themselves, anywhere from the edge to the cloud. That’s control.
This month, our “Always Be Launching” month, we’ll be announcing a variety of new features for Timescale aimed at providing developers with even more control through greater scale, security, robustness, and management.
Today, we’re excited to announce the new Timescale Explorer, which provides a richer administrative dashboard for understanding the state of your database instance. The Explorer gives you insight into the performance of your database, giving you both greater confidence and control over your data.
Keep reading for more about how Timescale Explorer works and how to get started.
If you’re new to Timescale, create a free account to get started with a fully managed Timescale instance (100% free for 30 days, no credit card required). After creating a new database service, just navigate to your service page to start playing with the Explorer yourself.
Once you are using Timescale, please join the Timescale community and ask any questions you may have about time-series data, databases, and more.
And, for those who share our mission and want to join our fully remote, global team, we are hiring broadly across many roles.
The new Explorer: Your easy-to-use “operations center”
A cloud-native database platform is a full user experience. The Timescale cloud console exposes highly relevant information, including many operational aspects for resource management, configuration tuning, and observability (metrics and logs).
Today, we’re releasing a much richer administrative dashboard for understanding the state of your database instance, which we call the Explorer.
The Explorer is meant to serve as your easy-to-use “operations center” as you develop and run your applications on TimescaleDB. It gives you quick access to the key properties of your database (like table sizes, schema definitions, and foreign key references) but is designed specifically for the TimescaleDB user and use case (e.g., providing information on hypertables and continuous aggregates), as opposed to more “general” Postgres admin UIs, such as pgAdmin or DBeaver.
We’ve listened to the broader TimescaleDB community about which information they often turn to in order to better understand their database, and designed the Explorer to give them this visibility and control.
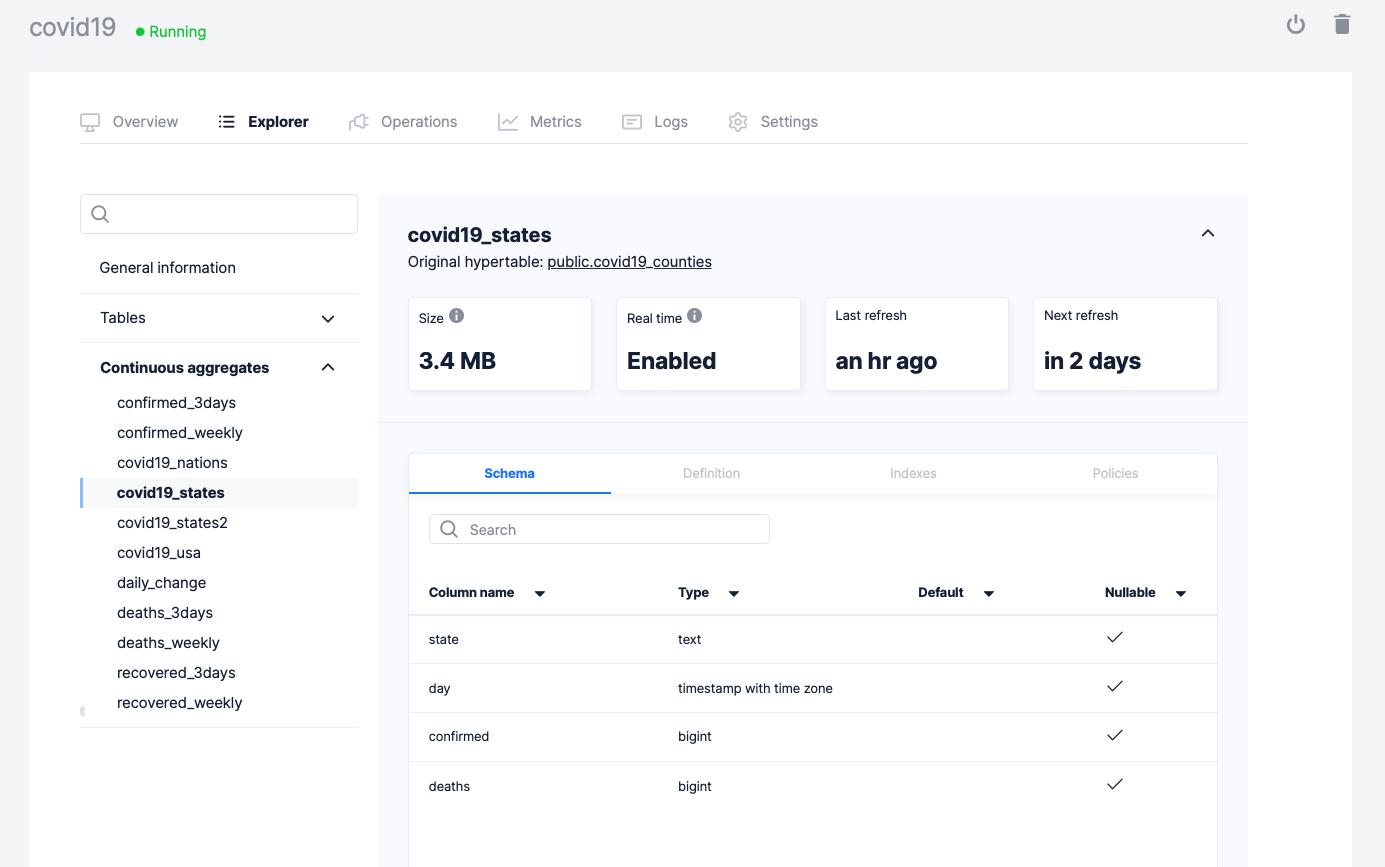
The Explorer gives you insight into both basic and advanced aspects of your database, providing higher-level overviews of your entire database (and what key features might be enabled for improved performance and cost efficiency), as well as detailed information about hypertables, chunks, continuous aggregates, policies, and more.
The below illustrations show some of the information now easily accessible via the Explorer, reflecting live information from your database:
- General information. A high-level summary of your TimescaleDB database, including all hypertables and relational tables. It summarizes your overall compression ratios, as well as other policy and continuous aggregate data. And, if you aren’t already using key features like TimescaleDB’s native compression, continuous aggregates, or other automation policies and actions, it provides pointers to tutorials and documentation to help you get started.

- Hypertable and table information. A detailed look into all your tables, including information about table schemas, table indexes, and foreign keys—and for hypertables, it surfaces details about chunks, continuous aggregates, and policies (such as data retention policies, data reordering, etc.). You can also inspect individual hypertable tables, including their sizes, dimension ranges, and compression status.

- Continuous aggregate information. A detailed look into all your continuous aggregates, including top-level information such as their size, whether they are configured for real-time aggregation, and their refresh periods.
For those new to TimescaleDB, TimescaleDB’s continuous aggregates are similar to database materialized views but are continuously and incrementally refreshed. This refresh is typically performed by a policy (reflected in the Explorer), which only recomputes the specific time regions that have changed since the last refresh, as opposed to the whole view. This is both optimized for time-series workloads that typically insert recent data but also correctly supports backfills to older time intervals.

Today, the Explorer provides read-only information about your database, although nearly every aspect highlighted in the Explorer either comes with good defaults (worry-free) or can be easily created or altered via simple database commands (control).
In the future, we plan to provide users with an even more powerful Explorer—including the ability to create and modify key aspects of your database directly from the Explorer—for an even more seamless experience.
Watch our demo video to see the Explorer in action
All that, and more
In addition to the Explorer, Timescale already includes a number of storage management and ecosystem integration capabilities that put developers in control of their database experience:
- Decoupled compute and storage. By separating compute and storage, users have total flexibility in allocating resources. So you don’t have to worry about a large price increase when you need to jump to the next size service for a little more storage. You choose and pay for just what you need.
- Independent resizing. Data needs often grow. So users can start small but scale compute or storage (or both) when they need. Timescale currently starts at $39/month and scales up to store more than 50 TB of data for a single instance when employing TimescaleDB’s advanced native compression.
- Automated, controllable tuning. Database parameter tuning can be complicated, so Timescale automatically tunes all databases for your provisioned service, taking into account our knowledge of time-series workloads. But your needs might be slightly different, so developers can easily adjust parameters via the console UI (while providing guardrails to avoid mistakes) or via psql, with most parameters supporting live reconfiguration. But next time your database is resized? Don’t worry, the system will automatically reconfigure those parameters which are impacted by the change for more optimal performance.
- Instantaneous recovery. Because of TimescaleDB’s cloud-native architecture, with decoupled compute and storage, all databases enjoy high availability at no extra cost to developers. All storage volumes are transparently replicated multiple times for high availability, and the platform continually monitors the health and availability of every database. If the database instance ever becomes unavailable – including due to underlying hardware failures of the cloud platform – platform orchestration immediately spins up a new compute service, reconnects it to the existing database storage, and enters fast recovery (e.g., replaying WAL for any uncommitted transaction). Databases are fully available in a few tens of seconds, even for databases measuring in the terabytes! And, unlike traditional primary/replica setups with database streaming replication – which similarly take 10+ seconds to identify failures and promote replicas – no additional physical replicas ($$$) are needed.
- Continuous backups and archiving. The platform takes streaming backups of your database continuously, such that the platform can recover services to any arbitrary point in time within the last week or more. Accidentally dropped that important table, deleted that column, or incorrectly updated critical data? No problem! Employing parallel recovery speeds up the process even for large databases. But want to control your own backup/recovery for extra safety? Developers are free to use the rich ecosystem of Postgres tooling for full database backups, and you can restore directly to running instances.
And even more to come soon
This is just the first announcement about new features for Timescale, our cloud-native platform; we have more to come this month (and beyond)!
Read my co-founder’s post for more details about “Always Be Launching” May, kicked off by our announcement of $40M of new financing. We continue to be excited and passionate about the future of Timescale and time-series data.

Get started
If you’re new to Timescale, create a free account to get started with a fully managed Timescale instance (100 % free for 30 days). After creating a new database service, just navigate to your service page to start playing with the Explorer yourself.
And once you are using TimescaleDB, please join the TimescaleDB community and ask any questions you may have about time-series data, databases, and more.
And, for those who share our mission and want to join our fully remote team, we are hiring broadly across many roles.
To the stars! 🐯🚀



