Hi there everyone, a background story:
I’m working for a company who makes rockets and my job is about gorund support softwares that process rocket telemetry data, these data fall into various groups, sources, and frequencies. to simplify, I’d say around 100 groups, each with 50 parameters(metrics) at the rate of 10ms, mostly float value. Currently we uses a bunch of softwares to process them and eventually written to MySQL in a 100_tables-each_50_columns fashion. Every time we run a launch simulation it creates 100 tables… And the system runs on a rack server with 10k SAS HDD, 256GB ram, holding a linux VM and a few win VMs:
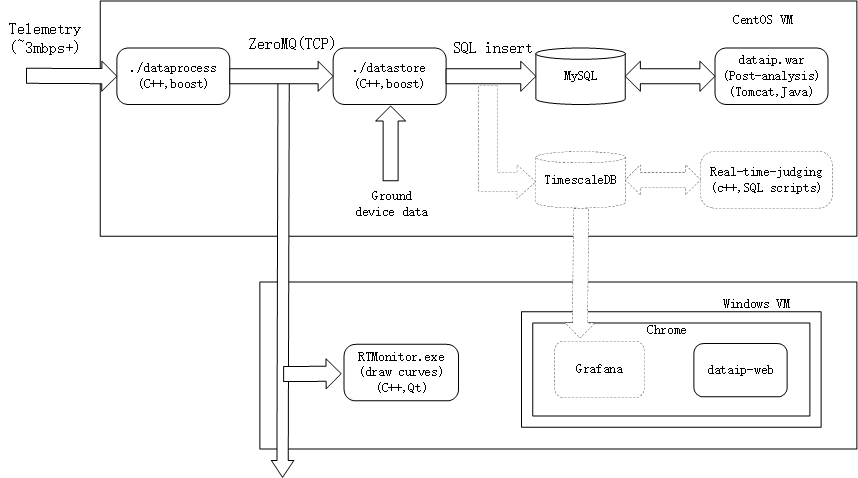
It is fast enough to present real time data since RTMonitor reads incoming data and shows them instantly. Then, we also have a post-time judging software that reads data from MySQL after the simulation ends, using predefined rules to decide whether the values are correct or not.
Now, we want to do real-time judging, the problem is that it’s not only just simple value upper/lower limit, it requires tracing data backwards in time, for example: ‘the duration of stage seperation command issued from central computer to corresponding device execution detected from sensor has to be within 100ms’. And I could not know if our enginners set a rule that overlaps minutes even hours.
That’s where I started thinking about TSDB, because I need to temporarily store large amount of time series data with an off-the-shelf structure, and it needs to be very fast. The above image in dashed lines are my thoughts of the design, grafana is just an add-on to potentially replace RTMonitor and show judge result and can be ignored, bottom line is: no bottleneck on IO, delay between incoming telemetry and data shows up on the curve/number within seconds, and flexible scripting language to write ‘rules’ that executes fast enough because it need to be evaluated like every second or half to ensure ‘real-time’ judging, and there could be dozens or hundred of rules running simutaneously.
For the past week I’ve been searching for the right TSDB, redis timeseries seems to be the best in-memory solution but it’s paid functionality in enterprise version. InfluxDB hasn’t been very acive after the release of 2.0 and ‘flux’ language isn’t cometitive against SQL in terms of history and scale. KDB outdated, prometheus and graphite may lack enough performance, TDengine claims to surpass others greatly in performance but I read their doc, one crutial functionality lacks: it only support update with timestamp given, but not a range. We have a hardware ‘offset’ timestamp generated when receiving telemetry at ground starting from zero when power up. This value needs to be shifted to make ignition time at value of 0, right after ignition happens. And post-juding rely on this time value to make decisions. It caused a serious problem when we ran the simulation for hours without ignition, mysql took too long to shift all the data for the past hours until ‘datastore’ drained it’s socket receiving cache(later I changed update procedure into async threads away from main insert loop).
Anyway, maybe I talk too much irrelevant information, but to sum up, can timescaleDB handle near instant inserting and fetching of the data amount I wanted? And is there a solution for that time shift problem because I need to start judging like seconds after ignition to catch up. Maybe a ram disk?
Thanks fo reading this long post, and forgive me if I was wrong on something because I’m just a developer with only a few years experience and has no knowledge on TSDB.