Hi there
We have a hypertable where we store electricity smart meter meter readings.
Our table looks like this:
– auto-generated definition
create table zaehlerstand
(
devicehuid text not null,
timestamp timestamp with time zone not null,
obiscodeid uuid not null,
wert numeric(18, 8),
readingqualitytype varchar(50),
createdat timestamp with time zone not null,
constraint pk_zaehlerstand
primary key (devicehuid, timestamp, obiscodeid)
);
create index zaehlerstand_timestamp_idx
on zaehlerstand (timestamp desc);
SELECT create_hypertable(‘zeitreihen.zaehlerstand’, ‘timestamp’);
In this table we have several millions of data from about the last 3 months (it will get more in future).
For calculating the measuring deltas between two meter readings, we will use the functions described in here Dear Eon - Measuring Deltas Correctly for Smart Energy Meters - #9 by davidkohn
Now we need some possibility to evaluate for which meter readings in the hypertable we not yet have calculated this deltas. For this reason we created another table where we stored the max timestamp for each device (and obiscode) of last calculation. This table looks like this:
create table lastgangprocessinfo
(
devicehuid text not null,
obiscodeid uuid not null,
lastprocesseddate timestamp with time zone,
constraint pk_lastgangprocessinfo
primary key (obiscodeid, devicehuid)
);
So now for getting the new meter readings we wanted to do the following query:
select * from zeitreihen.zaehlerstand z
join zeitreihen.lastgangprocessinfo lp on z.devicehuid = lp.devicehuid and z.obiscodeid = lp.obiscodeid
where z.timestamp > lp.lastprocesseddate
When we look at the execution plan and the time it uses to get the data, we see that it always makes a full table scan on each chunk of the hypertable.
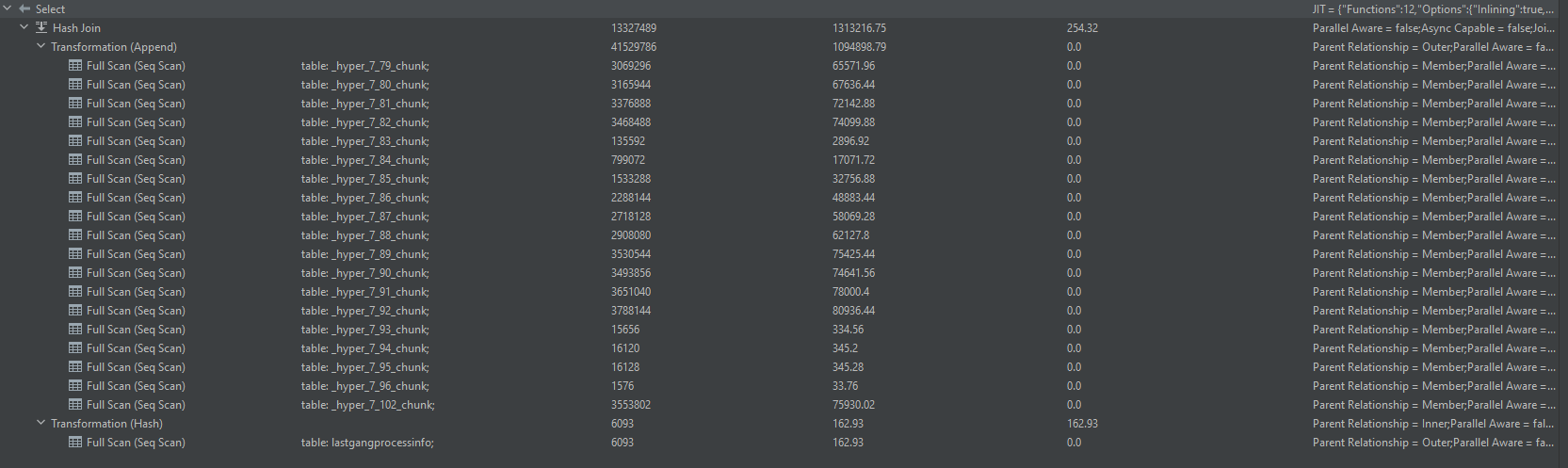
I would assume that it should take the timestamp from lastgangprocessinfo and only getting the chunks that are greater than the lastprocessddate.
So, now you maybe ask how much data and what data we have in lastgangprocessinfo. I thought also about that and created for testing purpose a simple table where I stored only one timestamp in there:
create table zeitreihen.testtimestamp (lastprocesseddate timestamptz);
insert into zeitreihen.testtimestamp (lastprocesseddate) values (‘2023-09-06 00:00:00.0 +00:00’);
If I do a similar query as before with joining this table, it also get this weird execution plan with a full table scan on every chunk.
select * from zeitreihen.zaehlerstand z
join zeitreihen.testtimestamp lp on z.timestamp > lp.lastprocesseddate;
Execution plan: Same as before
When I directly select the timestamp in a with query and do the same, it only takes the correct chunk and even uses the timestamp_idx on this chunk:
with testtimestamp as (select ‘2023-09-06 00:00:00.0 +00:00’::timestamp with time zone as lastprocesseddate)
select * from zeitreihen.zaehlerstand z
join testtimestamp lp on z.timestamp > lp.lastprocesseddate;
Execution plan:
INDEX_SCAN (index scan) table: _hyper_7_102_chunk; index: _hyper_7_102_chunk_zaehlerstand_timestamp_idx; 90452 4787.72 0.43 Parallel Aware = false;
Async Capable = false;
Scan Direction = Forward;
Alias = z;
Plan Width = 67;
Index Cond = (“timestamp” > ‘2023-09-06 00:00:00+00’::timestamp with time zone);
Does anyone now, why this behaviour occurs on joining hypertables with other “normal” tables? And how we can bring timescale to use the timestamp from our table to select first the chunks before scanning them?