One of the common questions the Timescale community asks is how to efficiently retrieve the most recent value for each item in the database, often referred to as a “last point” query. As your hypertable data grows in scale and cardinality, these kinds of queries can become slow and impact the ability of your application to quickly retrieve critical data.
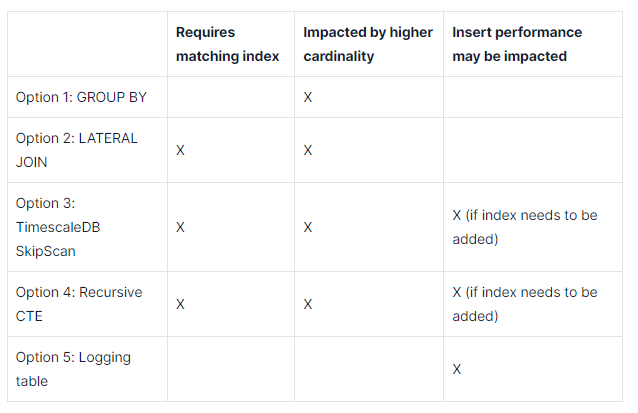
In this latest blog post, we look at 5 common approaches for getting this data efficiently, including a brief discussion on how indexes play a role and don’t always seem to help queries as you would expect.
For each option, we look at the pros and cons to help you think about which options might be usable with your application and dataset.
Enjoy the post and, as always, feel free to share your experience and add to the conversation!
Great article. I will definitely take a look at the lateral join solution. I have some additional thoughts on that:
Logging table and trigger: The naming of this solution might not be ideal because many people associate the term “logging” with an “append only” pattern, which would translate into “insert only” (no updates allowed) in the SQL world. I am aware that the term “upsert” is not very common even in the SQL world. However, “upsert” suits much better than “logging” imho.
I think it would be useful to distinguish between “actual most recent record” and “most recent record at a given point in time”. For example, there are certain metrics that I would consider as lifetime counters, for example the operating hours of a combustion engine (increment only). I have seen many scenarios where you want to know the operating hours at the end of the previous year or maybe at the beginning of the current quarter. In this scenario, you would not have a time range in the where clause but a single timestamp. The “logging table and trigger” solution would not be suitable in this scenario.
There is one problem that is very much related to the “select the most recent record” problem: Even if you are querying a certain metric with a time range, in many cases you do not only want the data points of that metric within the given time range, but also a single initial value which represents the most recent value of that metric before the given time range. This is not a problem if your metric has a fixed sampling rate (or fixed delta time respectively). However, if you only insert new values in your hypertable when the metric’s value has changed (report by exception scenario), then you don’t know how much you would have to extend your original time range to include the initial value in the query result. The worst case scenario is that you do not get a single record as a query result because the metric that you are querying has not changed in the given time range.
Appreciate the feedback @larsw! I can totally see how the “logging” name can be misleading. Depending on what you’re tracking, you could just keep it in the relation table (truck in this case) if that makes it more clear, or even something like truck_status for a name, rather than logging. Hopefully, the concept makes sense, which was the main reason for the blog post.
You’re other two points are certainly problems folks run into, for sure as they weren’t the focus of this article.
For the second scenario, depending on how much information you need to store, you could just not UPDATE the “first reading” column on CONFLICT. So, your INSERT statement would include a column like first_reading which repeats your timestamp column, but the UPDATE part of the statement wouldn’t include it. In this way, the original timestamp doesn’t get updated, but the other values for the most recent data does. Haven’t thought about it a lot, but it might be one approach.
That said, the focus of the article was specifically about “last point” because we get that question a lot. But these additional questions and ideas are good for the backlog to look at later!
Interesting approaches, is this not a solution that timescale can better help with? Like you said it is a common issue, how to get the last given record for a table - (alternately simply storing the PK with the truck_id in your logging table would likely be an ok approach as well)
Another scenario that I am typically faced with is the time in state problem - lets say the trucks had a temperature column. Now I want to know the start/end times of each truck where the temperature exceeded 100, also I want to know the max, and average temperatures for this time period and the timedelta in this period. It would be interesting to know what the optimal approach to this would be
Great question! One of the reasons we talked about “5 ways” is that schema and application design influence the options you have available. For instance the DISTINCT ON(truck_id)... option is a TimescaleDB solution that can help when your data is stored with the right indexes, but not always the best option. It’s certainly a pain point for many developers so knowing your current options is a good place to start.
To your second question, that’s a little more complicated than just getting the most recent value. Are you looking for the actual start/end times of each state or just the “duration_in” for each state within a specific window of time? (ie. how long was truck 1 in a high_temp state over the last day)
Sorry for the delay, the second case is more commonly referred to Gaps and Islands. A timescale aggregate with LAG does help with this to a certain extent. But it would be an interesting blog post to explore deeper
 New blog post: Select the most recent record (of many items) with PostgreSQL
New blog post: Select the most recent record (of many items) with PostgreSQL