“Guide to Grafana 101: Creating Awesome Visualizations” Recap and Resources
Get step-by-step demos and learn how to create 6 different visuals for DevOps, IoT, geospatial, and public data scenarios (and beyond).
We just kicked off a new “Grafana 101” webinar series, a set of technical sessions focused on getting you up and running with Grafana’s various capabilities (there are tons!) - complete with step-by-step demos, tips, and resources to re-create what we cover.
In the first session, “Grafana 101: Creating Awesome Visualizations,” I show how to build 6 common Grafana visuals, plus a few tips and tricks to help you along the way, so you leave ready to create useful, interactive, and awesome Grafana dashboards for your projects.
We know not everyone could make it live, so we’ve published the recording and slides for anyone and everyone to access at any time.
- If you missed this one, or attended and are keen to learn more, we’re hosting the next installment, “Guide to Grafana 101: Getting Started with Alerts” on May 20th (RSVP here).
What you’ll learn:
Based on my own experience with Grafana and my conversations with other developers, building useful Grafana visualizations isn’t always easy.
So, to reduce that learning curve, I created this session to illustrate the common visualization types, datasets, and tips and tricks (like variables, series-override, and thresholds) that have helped me get up and running.
I made sure to cater to new and existing Grafana users, quickly covering why you’d use Grafana to build dashboards and a quick overview of how Grafana is structured (terminology, hierarchy, etc.). From there, I go straight into step-by-step demos to show you how to build 6 common visuals, in 3 scenarios: DevOps, IoT monitoring with geospatial data, and public datasets.
More specifically, the session consists of 4 parts:
Why use Grafana?
In my opinion, Grafana is a great choice for dashboarding for three main reasons:
- It’s open source, which makes it a cheaper alternative to proprietary viz tools.
- It supports many different visualization types and also has support for alerting (which happens to be the focus of our next technical session).
- It integrates with many common data sources, like PostgreSQL, Prometheus, and AWS CloudWatch. Since Grafana allows you to combine data from different sources in one dashboard, you can build highly customized dashboards for cases like monitoring multiple deployment clusters, or deployments of multiple products.

Orientation and Data Source Setup
In this section, I introduce a basic “mental model” for thinking about how Grafana is structured, introducing its hierarchy of instances, data sources, dashboards, and panels.
You’ll also get a walkthrough of a dashboard powered by multiple data sources and see how to connect a TimescaleDB database to Grafana (I’ll use TimescaleDB as my datasource to demo various visualizations).

Let’s code: 6 (awesome) visualizations
After getting oriented with Grafana, it’s time for the best part: creating the visuals!
I spend 45 minutes taking you through how to create 6 visuals, using the use cases of DevOps, IoT and geospatial data, and charting the spread of COVID-19.
DevOps: Monitoring a production database using Prometheus and TimescaleDB
If you’re working in a DevOps scenario, you likely need to monitor various key metrics, and, in the case of my demo, I want to monitor my production database.

You’ll see how to set thresholds and build visualizations to answer questions about database performance and status.
Grafana visualization types and questions we answer:
- Single Stat: Which version of the database are we running?
- Gauge: How much disk space are we currently using? Is it within an acceptable range?
- Graph: What’s the cache-hit ratio for my database over time?
- Single Stat with status: What’s the cache-hit ratio for queries in my database? Is it in an acceptable range?
Note: We use the dataset from this tutorial on using Timescale as a long term datastore for Prometheus metrics.
And, we’re at work on a new connector for Prometheus. If you’re interested in learning more and trying it out, you can check out our design doc and GitHub repo.
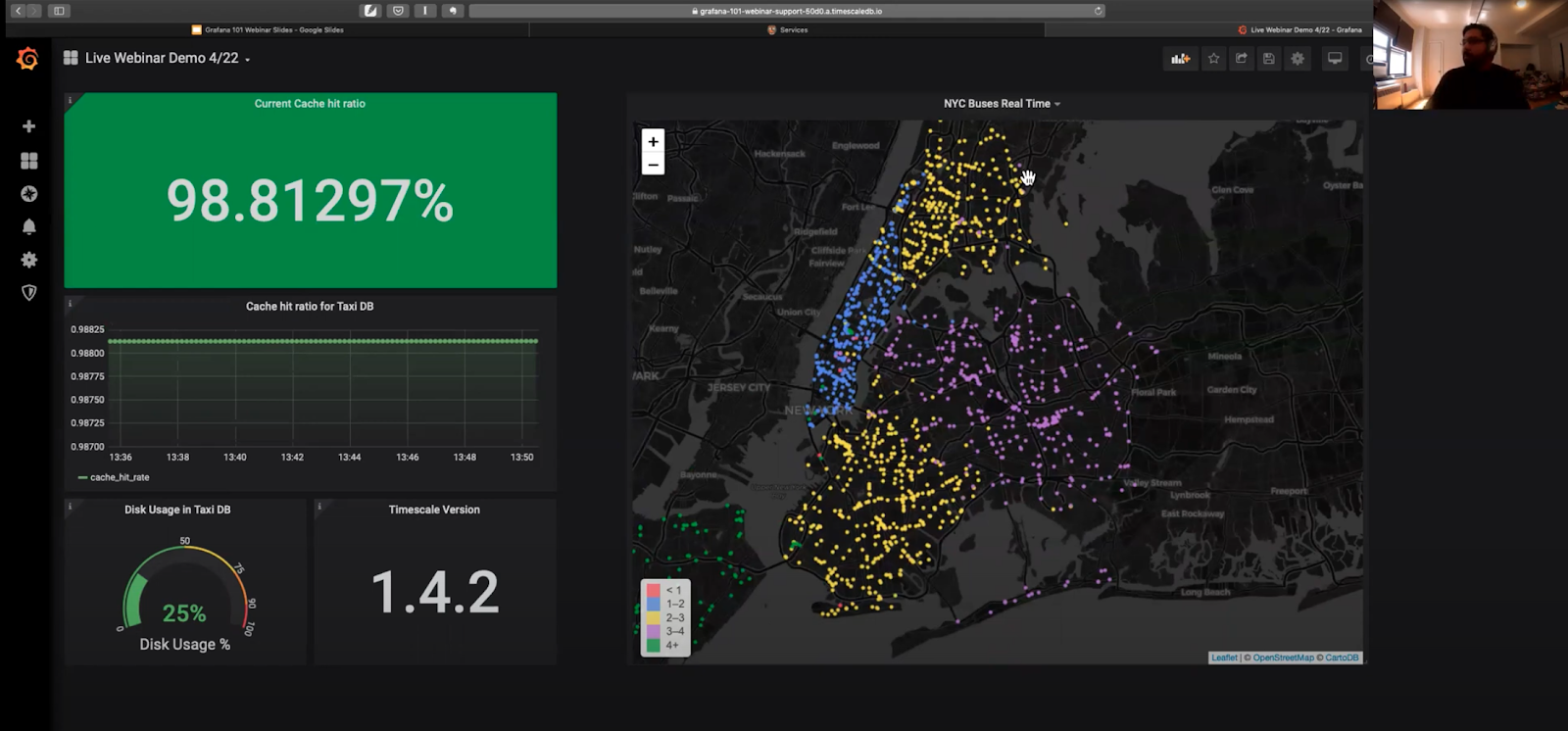
IoT / GeoSpatial: Monitoring Public Bus Locations in New York City
Using data from the New York Metropolitan Transport Authority, I show you how to combine time-series and geospatial data to display the real-time location of various buses throughout New York City.

In this section, I focus on one of my favorite visualization types, the Worldmap Panel.
Grafana visualization type and question we answer:
- Worldmap: where are the public buses in New York City right now? Does a certain route or burrough have more buses on the streets at a given time?
As a bonus, I also show you how to use variables to allow users to filter the bus routes and locations that appear on the map. This turns the dashboard from a static visual into an interactive one, where anyone can select various routes they want to see from an interactive drop down menu.
You can learn more about variables and how they work here.
Public Data: Charting and analyzing trends in the spread of COVID-19 in the USA
Finally, I chart the spread of COVID-19 in the USA, using publicly available data from the New York Times.

series-override in this example using COVID-19 dataGrafana visualization type and questions we answer:
- Graph: How many COVID-19 cases and deaths have taken place in the USA to date? How do these trends compare?
You’ll also see how to use Grafana’s series-override function to plot your data on two Y-axes and more accurately show COVID-19 case and death rates over time (something that’s lost due the variables relative scale when both variables are plotted using the same Y-axis).
Resources + Q & A
Want to re-create the dashboards shown in the demo? Or perhaps you want to try modifying them to work with your own data sources for your projects? Don’t sweat, we have you covered!
In the session, we link to several resources, like tutorials and sample dashboards, to get you well on your way:
- Import our demo dashboard as a starting point for your own Grafana creations (includes variables, queries, and parameters).
- Learn how to get up and running with Grafana and TimescaleDB in our Grafana mega-tutorial or get started visualizing your Prometheus metrics.
- Follow along with the session recording.
- Get started with Timescale Cloud (our hosted time-series database, which comes with a 30-day free trial)
- Join our Slack to ask questions and get help from our engineers and community members.
Community questions
We received over 30 questions during the session (thank you to everyone who submitted one!). Here’s a selection:
Q: Is the PostgreSQL datasource "stock" in Grafana, or a TimescaleDB-specific one?
A: The PostgreSQL data source is stock in Grafana and was (fun fact) actually contributed by Timescaler Sven Klemm.
While you can use the PostgreSQL data source in Grafana for Postgres instances that don’t contain TimescaleDB; if you’re using TimescaleDB, we strongly recommend enabling TimescaleDB when setting up your data source, in order to get better performance (like I mention in the demo and as outlined in this tutorial).
Q: The latest PG version in the datasource in the demo was 10. What about later versions of PostgreSQL?
A: Grafana supports PG 11 and PG 12, but if you’re using Grafana 6.5.2, you may find that the version picker doesn’t include versions above PG 10 (as noted in this forum post).
From my reading, this has been fixed in the latest Grafana releases (6.6 and 6.7), so you can connect your TimescaleDB instances with PG 11 (and now PG 12!) to Grafana.
Q: When should I use a Gauge vs. a Single Stat?
A: Single Stats and Gauges both show a single number.
The main difference is that Gauges are generally for measuring the current state of consumption of fixed resources (e.g disk, memory, CPU etc.), or cases where it’s important to know usage relative to thresholds. For example, gauges are ideal to quickly let you know that you are currently at 80% of storage capacity.
On the other hand, Single Stats are well-suited for displaying current values (like counts), things like version numbers, or other one-off values.
Q: From a performance perspective, is it better to give reporting users pre-built views (like aggregates) or the raw time-series data directly?
A: If you’re optimizing for performance with regard to query speed and ingestion rate, using views, like TimescaleDB’s continuous aggregates, is the way to go.
That way, your reporting users query the continuous aggregates, which is faster than directly querying hypertables for the kind of aggregate queries reports require. Additionally, by not querying hypertables directly, you ensure higher insert performance (since you don’t have queries and inserts being performed on the same hypertable).
For use cases like dashboarding and IT Ops reporting, where you want the speed of querying aggregated views and also need fully up-to-date data, check out our new real-time aggregates feature.
Q: Variables, once defined, are visible across the whole dashboard. Is there a way to make variables visible only to relevant panels?
A: Grafana variables are dashboard-specific, not panel-specific, so multiple panels can access the same variable.
This is useful if you have several panels that use the same variable, but can be tricky if your panel:variable ratio is closer to 1:1 (this can be the case with many dashboards that depend on a variety of data sources, like a CTO dashboard that looks at details for multiple products and deployments).
There is no way to make variables apply only to specific panels, at the time of writing. However, there is an open issue on GitHub for you to add to and upvote.
Two quick tips:
- A variable won’t apply to a panel if it’s not used in the query, or as a parameter in the panel settings.
- If you find yourself with too many variables in one dashboard, consider branching off into smaller, more focused, and purpose-specific dashboards. This can help keep your dashboards organized and easy to navigate when you have many variables.
Q: In the IT monitoring demo, your data was Prometheus metrics, stored in TimescaleDB. Can you explain a bit more about how TimescaleDB interacts with your Postgres table and Prometheus?
A: Many people are familiar with using Prometheus as a direct Grafana datasource.
But, in the demo, I use Prometheus to scrape metrics from my target (a database I’m monitoring), then use TimescaleDB as a remote read and write for Prometheus. This way, all of my Prometheus metrics are written to and stored in TimescaleDB, so I can query TimescaleDB for my metrics - rather than Prometheus directly.
This is useful because:
- I have a long-term store for Prometheus data, so I can retain data over longer periods of time
- I can aggregate metrics from multiple Prometheus instances in one database, giving me more operational ease (i.e., I simply query that one database v. multiple instances).
Learn more about why you should use a long-term store for Prometheus metrics and how to get started here.
Q: When are the next webinars in this series? Is there a way we can sign up to be notified?
A: Glad you asked! The next webinar in our Grafana 101 series is “Getting Started with Alerting” (Wednesday, May 20th at 10 am PT/1 pm ET / 4 pm GMT). I hope to see you there.
...and to make sure you never miss sessions like this, signup for Timescale's newsletter, where we always add upcoming technical sessions (as well as announcements and best practices from our community).
Ready for more Grafana goodness?
As always, thank you to those who made it live – and to those who couldn’t, I – and the rest of Team Timescale – are here to help at any time. Reach out via our public Slack channel, and we’ll happily jump in.
For easy reference, here are the recording and slides for you to check out, re-watch, and share with friends and teammates.
Want to learn more about this topic? Be sure to sign up for session 2 in our Grafana 101 technical session series, on Wed, May 20: “Guide to Grafana 101: Getting Started with Alerts”
- 🔍RSVP to learn how to use your Grafana dashboards to understand when issues arise in your critical metrics, get notifications, and take action quickly.
To learn about future sessions and get updates about new content, releases, and other technical content, subscribe to our Biweekly Newsletter.
Hope to see you on the next one!



